Crear un data pipeline
Ahora que hemos subido el dataset, procederemos a crear un data pipeline con el dataset.
-
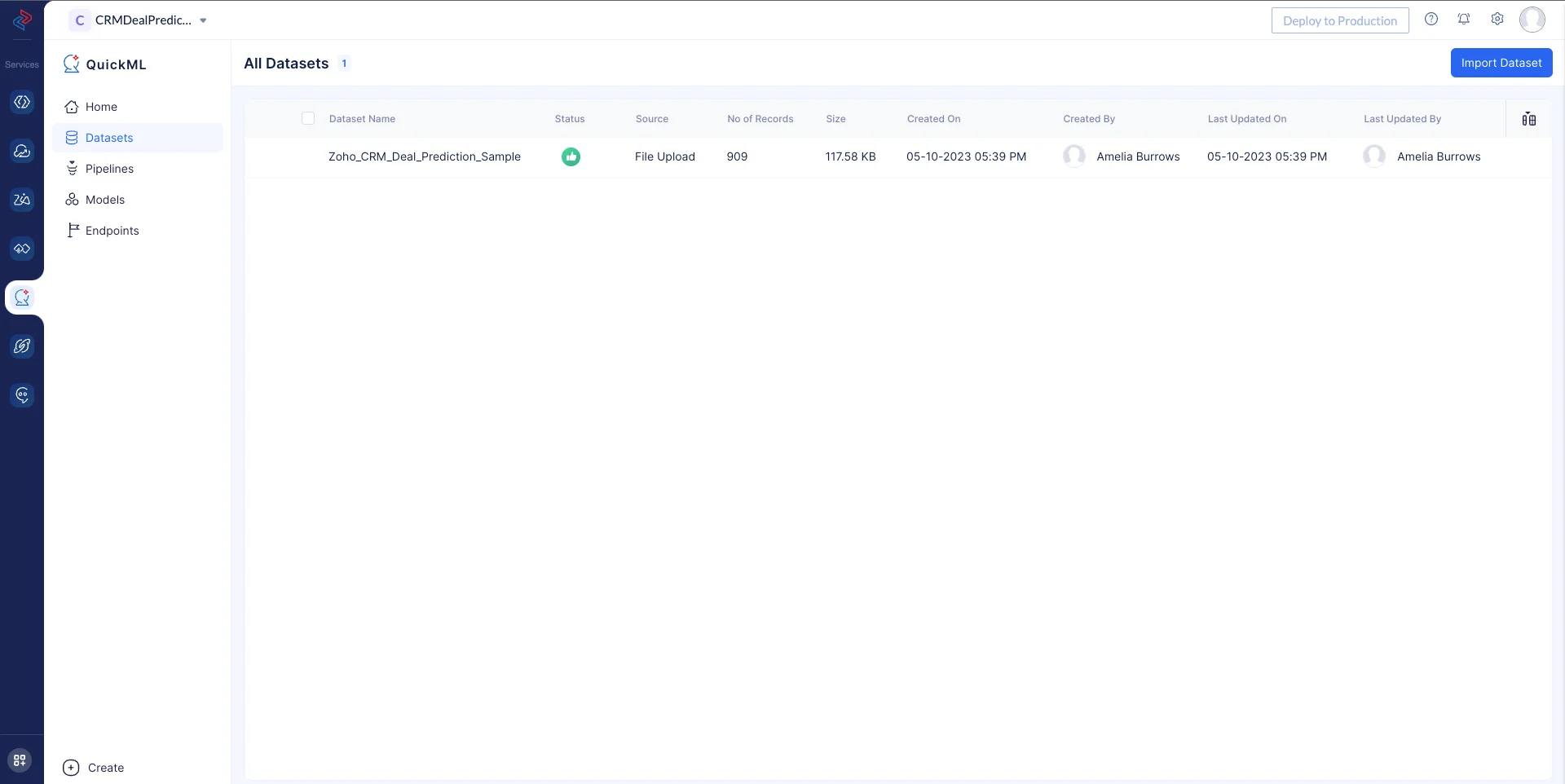
Navega al componente Datasets en el menú izquierdo y haz clic en el dataset Zoho_CRM_Deal_Prediction_Sample.
-
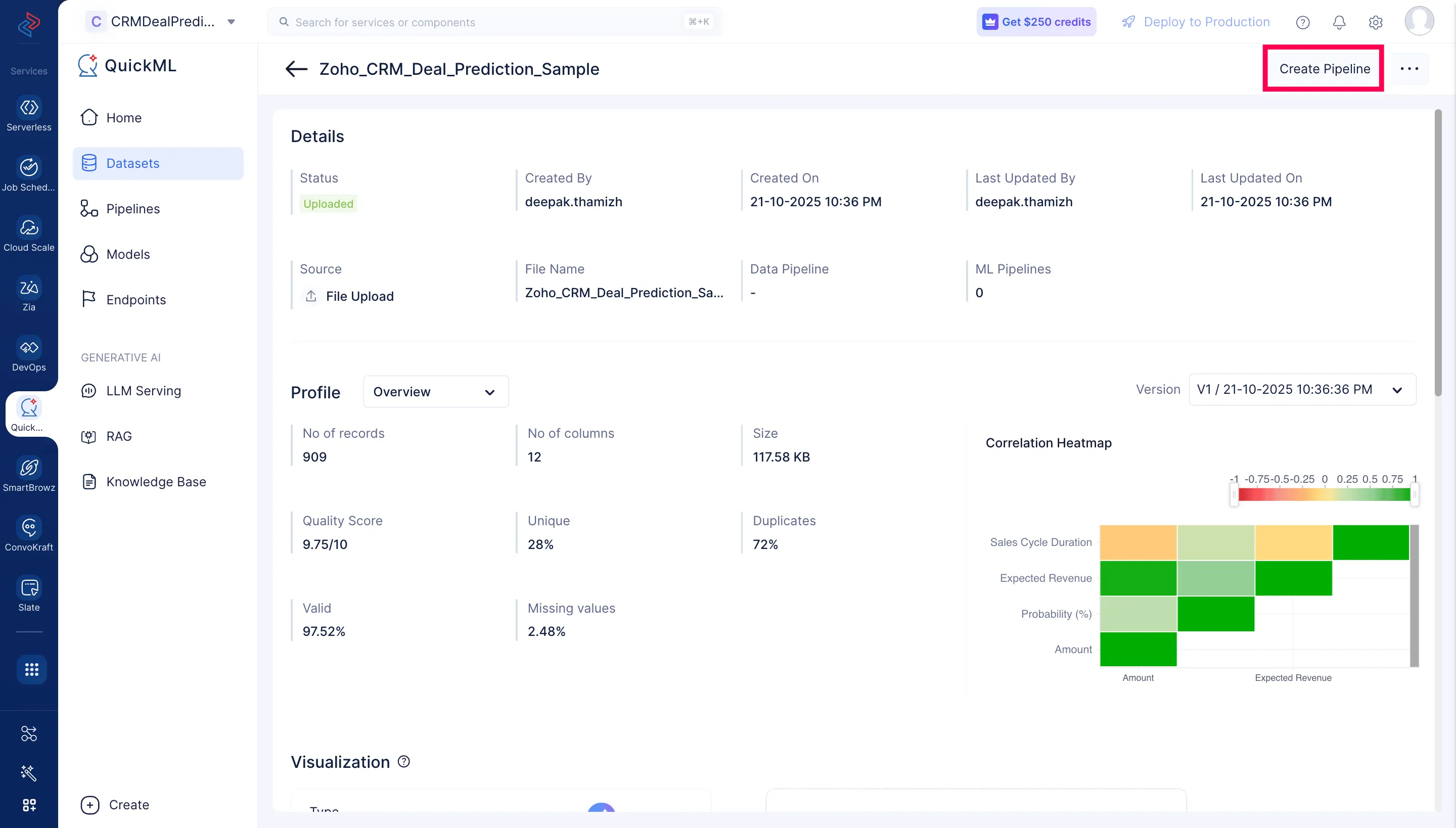
Se mostrará la página de Details del dataset. Haz clic en Create Pipeline en la esquina superior derecha de la página.
-
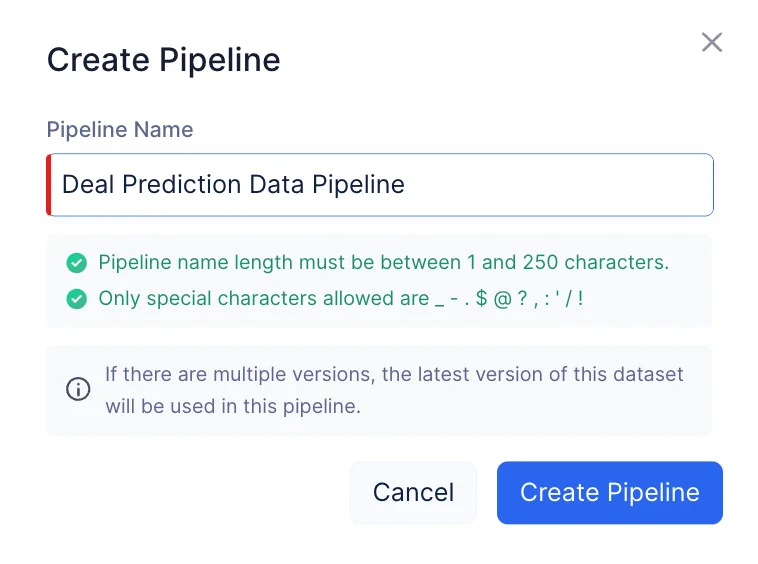
Nombra el pipeline “Deal Prediction Data Pipeline” y haz clic en Create Pipeline.
La interfaz del pipeline builder se abrirá como se muestra en la captura de pantalla a continuación.
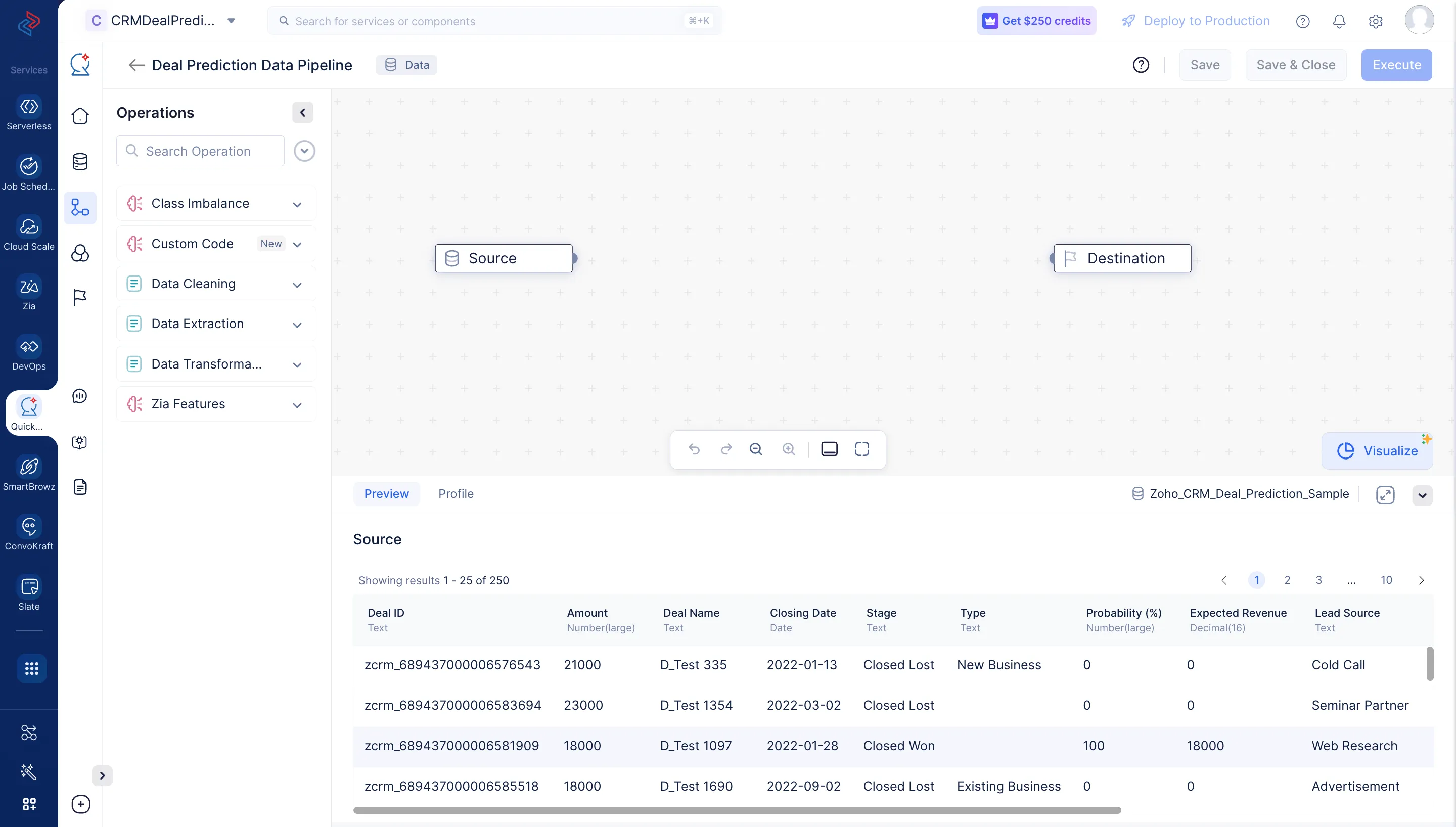
Realizaremos el siguiente conjunto de operaciones de preprocesamiento de datos para limpiar, refinar y transformar los datasets, y luego ejecutar el data pipeline. Cada una de estas operaciones involucra nodos de datos individuales que se usan para construir el pipeline.
Seleccionar campos para el preprocesamiento de datos
Primero, seleccionaremos los campos requeridos en el dataset para modificarlos posteriormente.
-
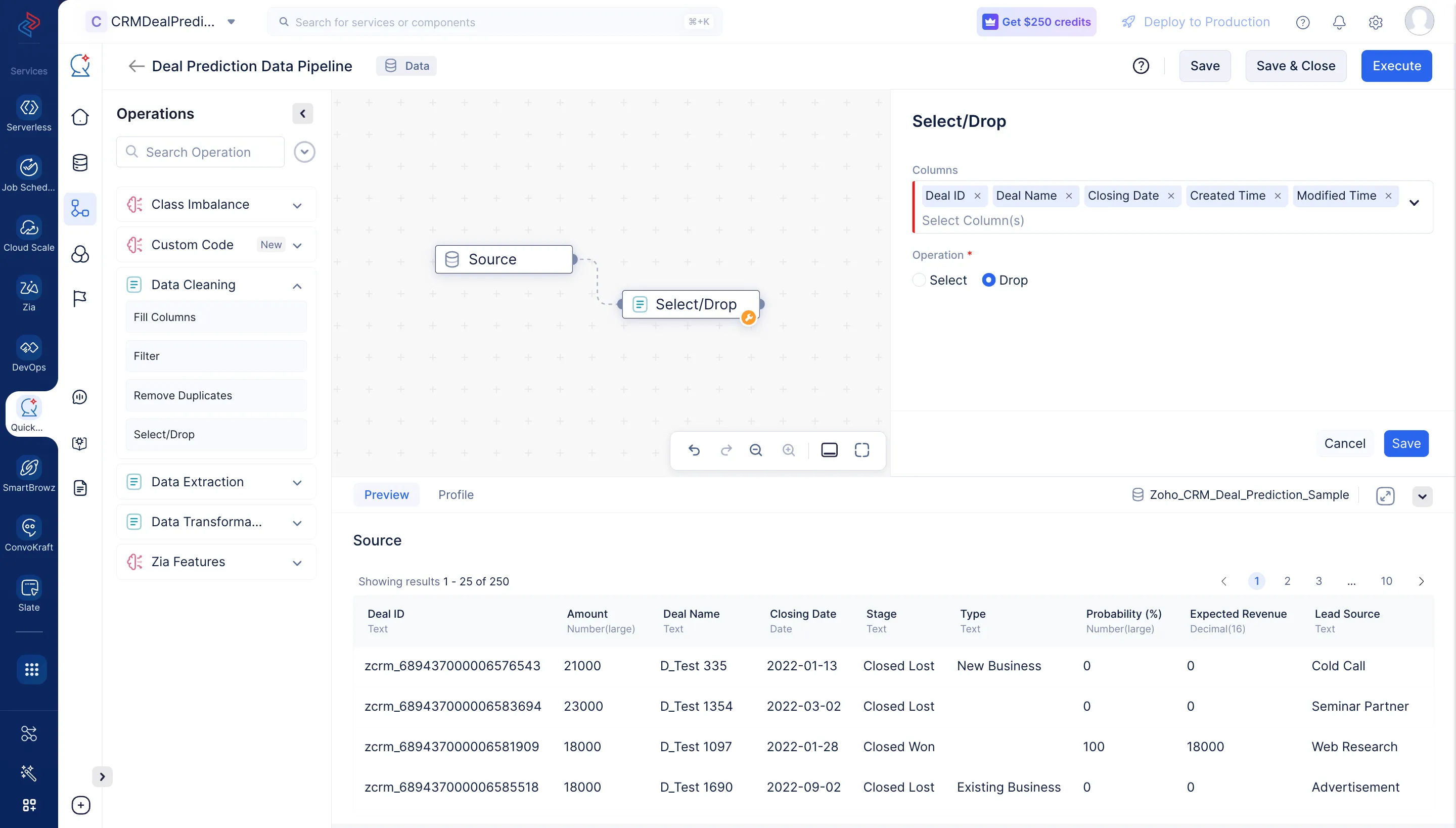
Expande el componente Data Cleaning en el menú de Operations. Arrastra y suelta el nodo Select/Drop en el pipeline builder y haz una conexión con el nodo Source.
-
En la sección Select/Drop del panel derecho, selecciona las columnas “Deal ID,” “Deal Name,” “Closing Date,” “Created Time,” y “Modified Time”, y elige la operación “Drop” para eliminar las columnas del dataset, luego haz clic en Save. En nuestro caso, estas columnas son genéricas y no sirven para ser usadas posteriormente, por lo que las eliminamos.
Manejar valores faltantes
Para mejorar la calidad de los datos usados para el entrenamiento, filtraremos los datos no vacíos para las columnas requeridas usando el nodo Filter. Este proceso elimina datos irrelevantes o incompletos, asegurando que solo se use información valiosa para el desarrollo del modelo.
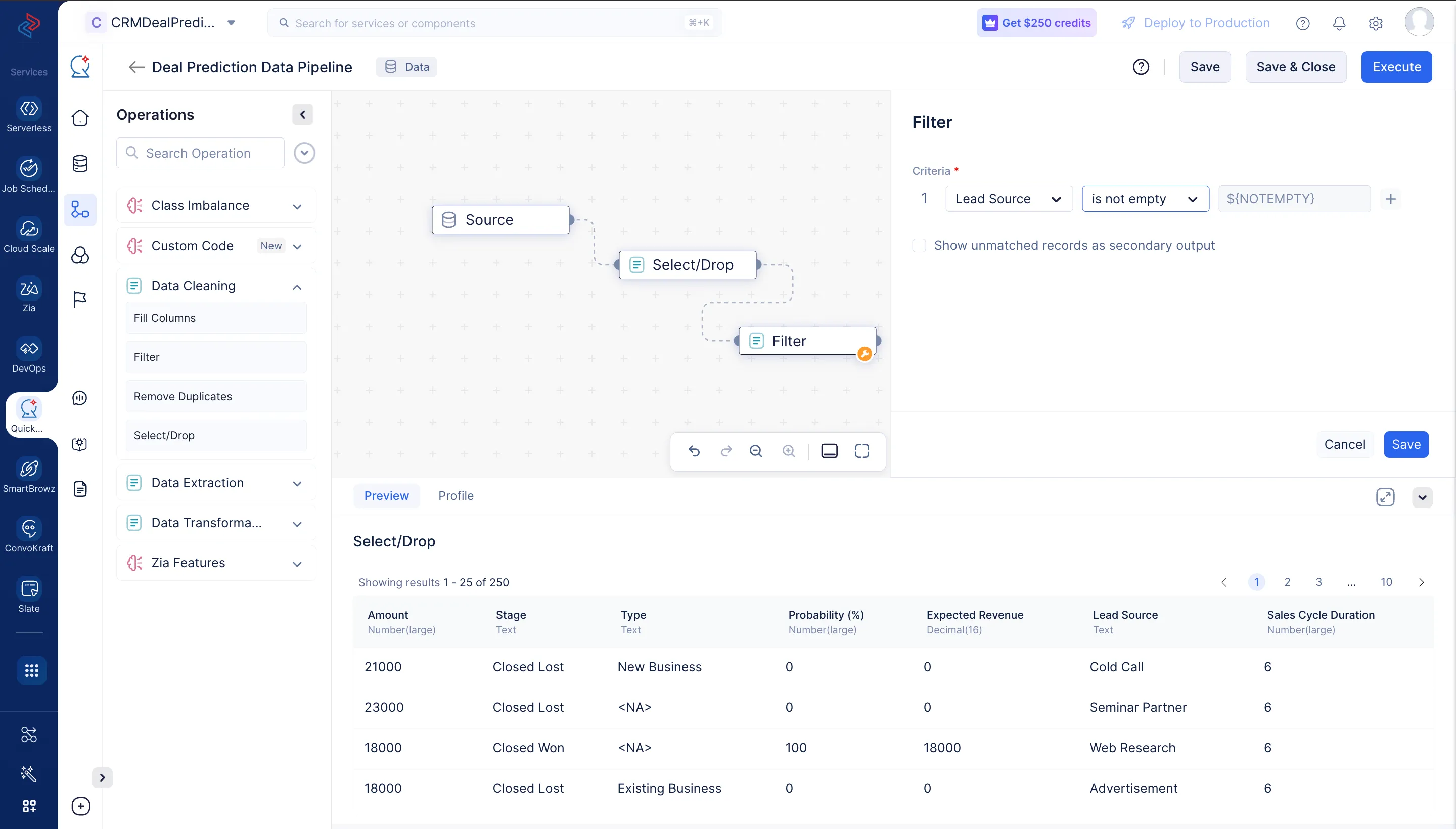
Dado que Lead Source es una de las columnas clave para el entrenamiento de nuestro modelo, estamos agregando un filtro a esa columna para evitar celdas vacías. Si deseas procesar los datos no coincidentes del filtro, elige show unmatched records as a secondary output si quieres obtener otra salida para datos no coincidentes.
Rellenar columnas
Como parte del preprocesamiento de datos, necesitaremos verificar si hay valores faltantes en alguna de las columnas de los datasets y rellenarlos. Usaremos el nodo Fill Columns para ejecutar esta operación.
-
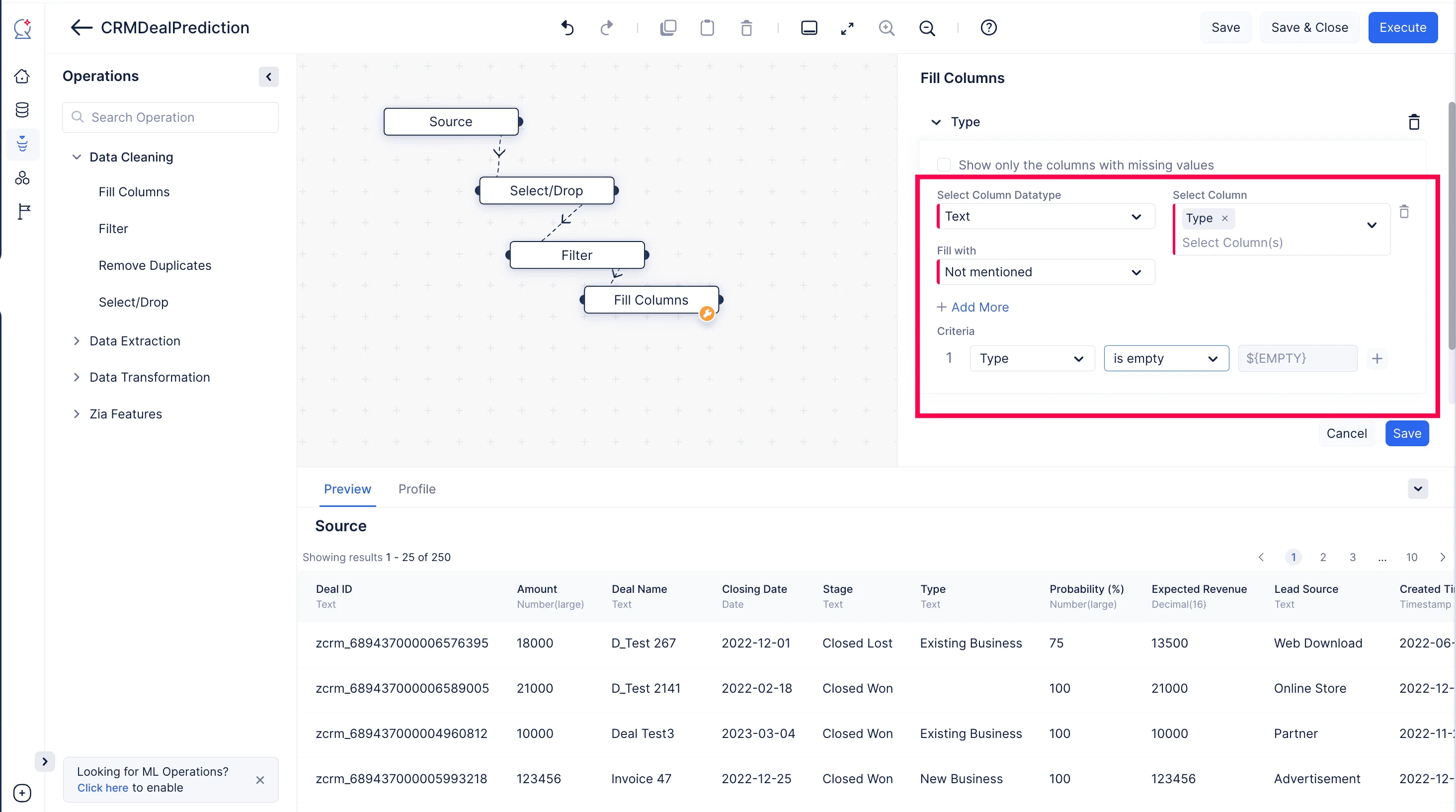
Expande el componente Data Cleaning en el menú de Operations. Arrastra y suelta el nodo Fill Columns en el pipeline builder y haz una conexión con el nodo Filter anterior como se muestra en la captura de pantalla a continuación.
-
Del desplegable llamado Select Column, elige “Type”. En el campo Fill with, elige “Custom Value”. Actualiza el campo Value como “Not mentioned”, y selecciona el criterio como “Type”, e “Is empty” en el desplegable, luego haz clic en Save. Esto rellena los valores vacíos como “Not mentioned” en la columna Type.
Hasta ahora, nuestro dataset está preparado y hemos configurado los nodos requeridos para este tutorial. Finalmente, haz una conexión entre el último nodo configurado Fill Columns y el nodo Destination.
Haz clic en Execute.
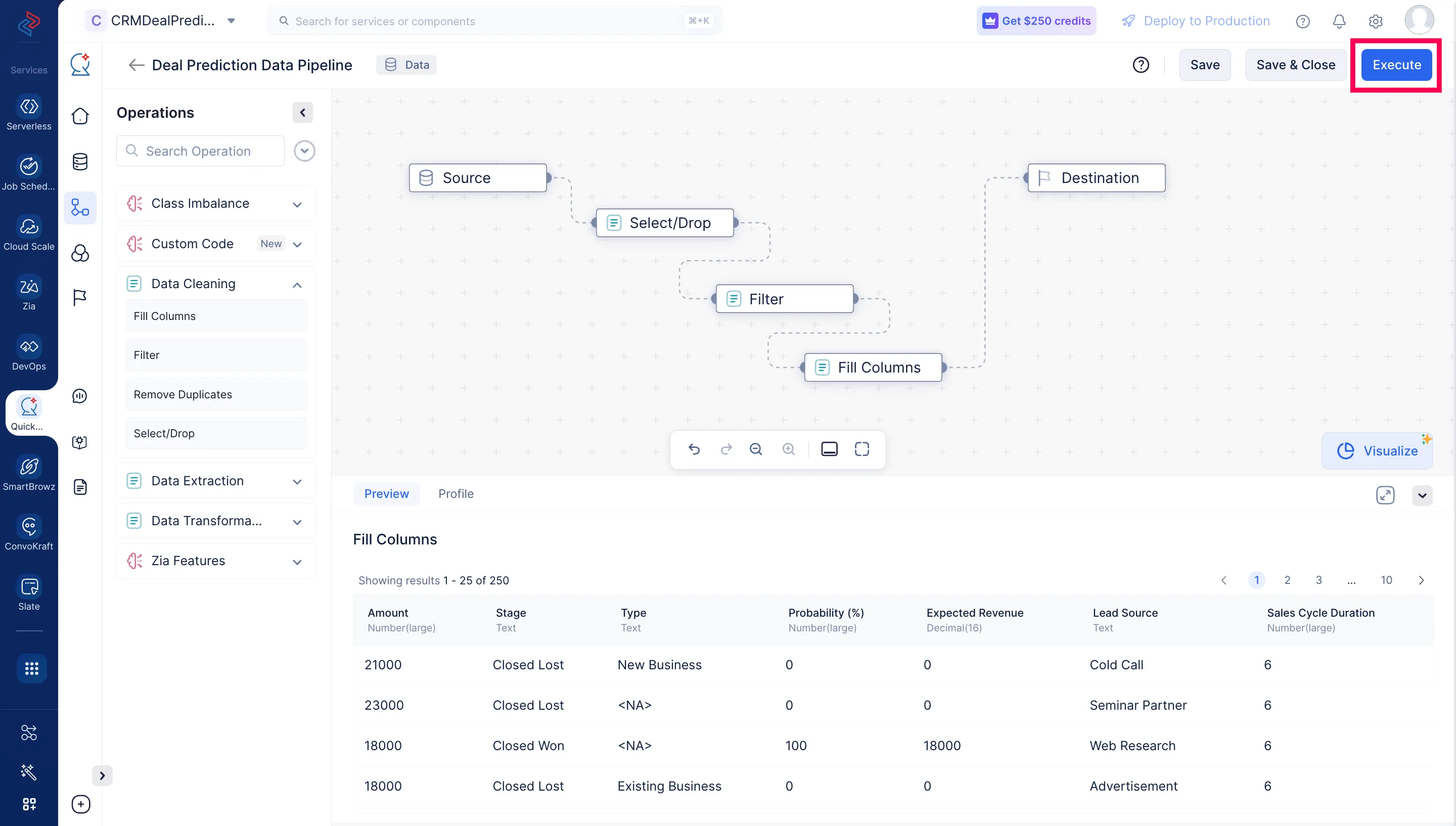
El data pipeline comenzará la ejecución y el estado de la ejecución se mostrará en la página de Details del pipeline como se muestra en la captura de pantalla a continuación. Una vez que el pipeline haya completado la ejecución, el estado de ejecución mostrará “Success”.
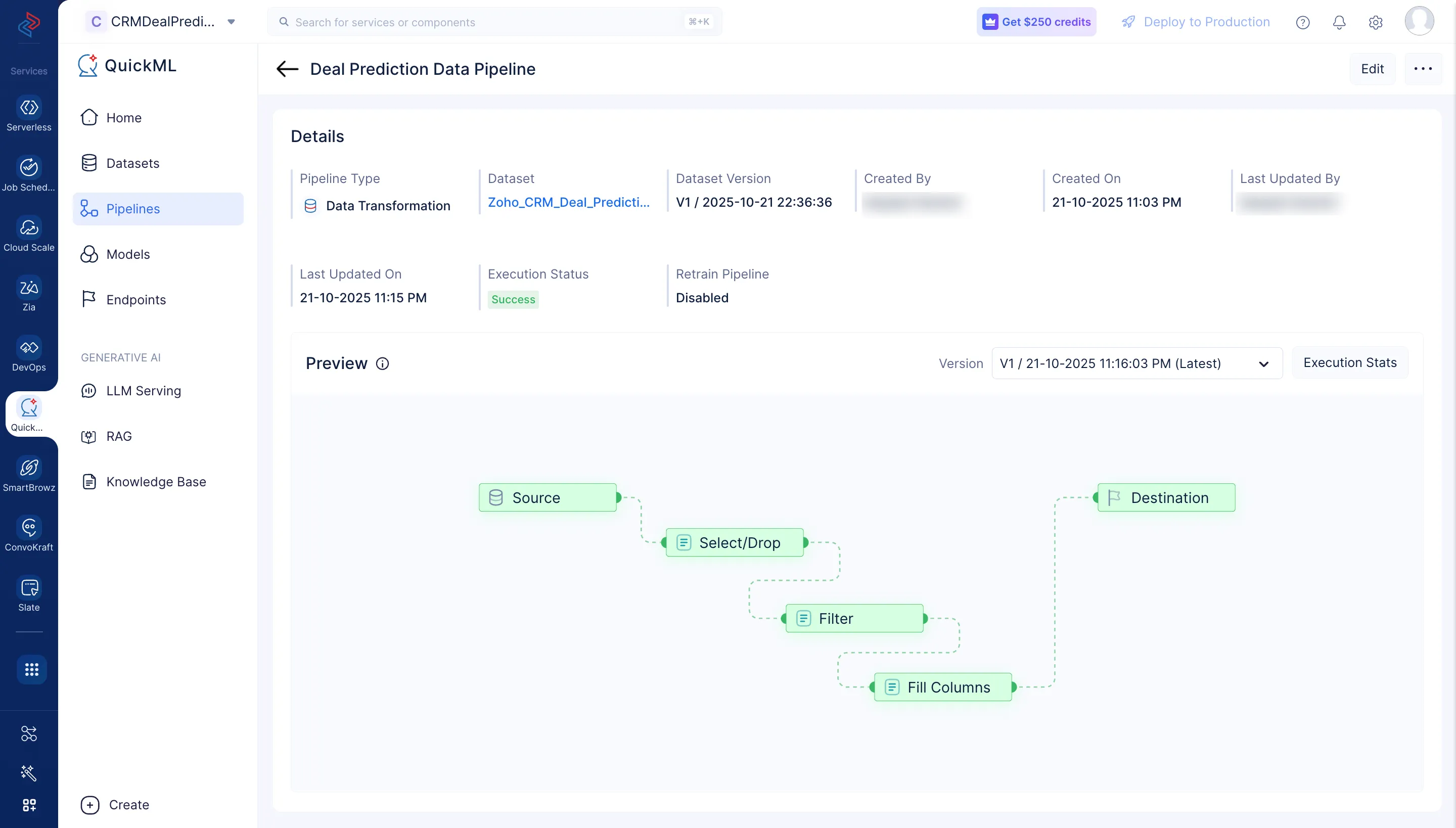
Haz clic en Execution Stats para ver más detalles sobre cada etapa de la ejecución en detalle.
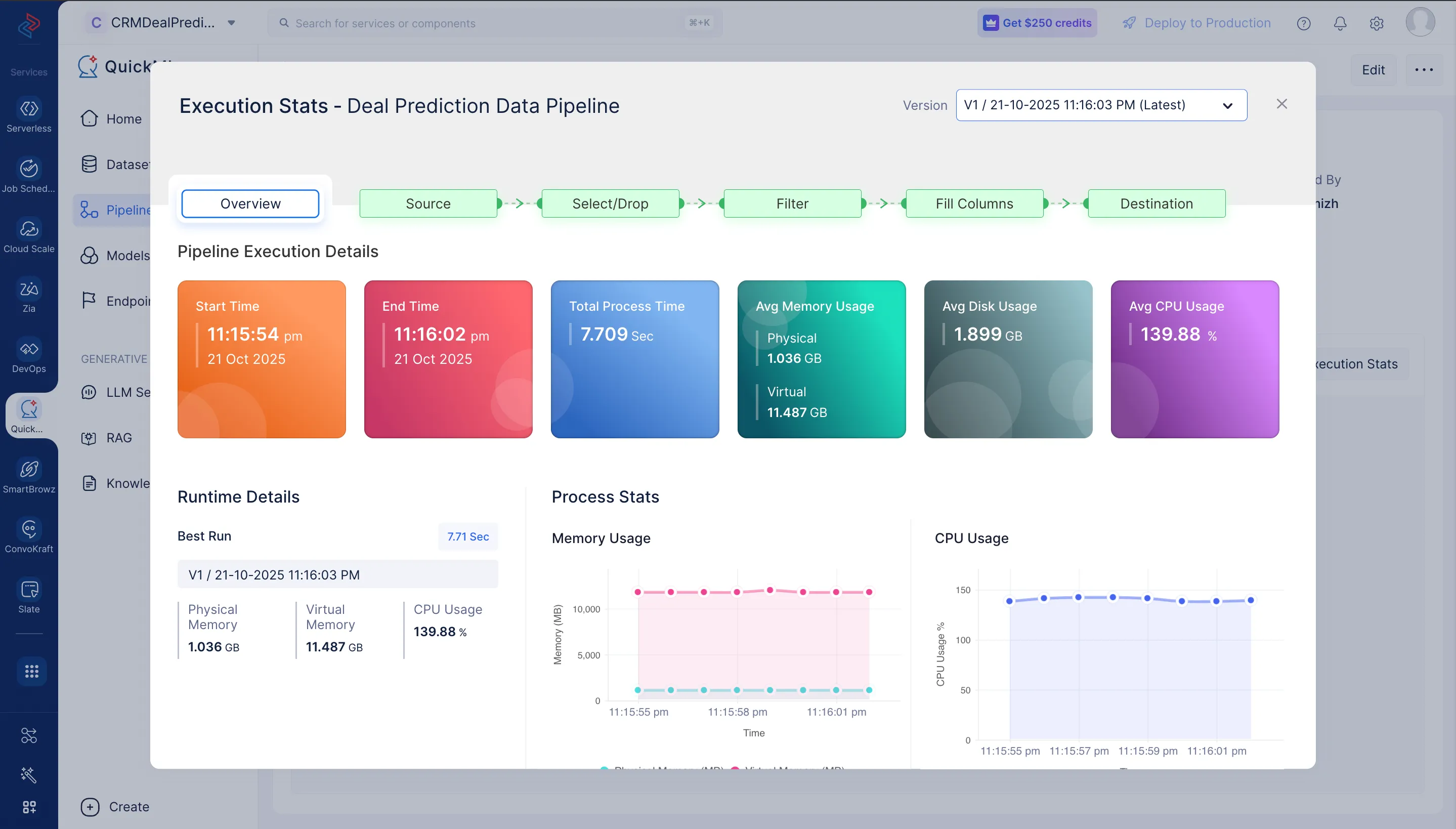
Ahora, hemos preparado nuestro dataset que puede usarse para desarrollar el modelo de ML. Discutiremos más sobre la creación del ML pipeline en la siguiente sección.
Última actualización 2026-03-20 21:51:56 +0530 IST