MLパイプラインの作成
このセクションでは、前のセクションで前処理したデータセットを使用して、予測MLモデルを構築します。このデータセットはMLパイプラインビルダーへの入力となり、モデルのアーキテクチャの定義と予測対象の列の選択が可能になります。
MLパイプラインを作成するには、以下の手順に従ってください。
-
左メニューのPipelinesコンポーネントに移動し、Create Pipelineをクリックします。
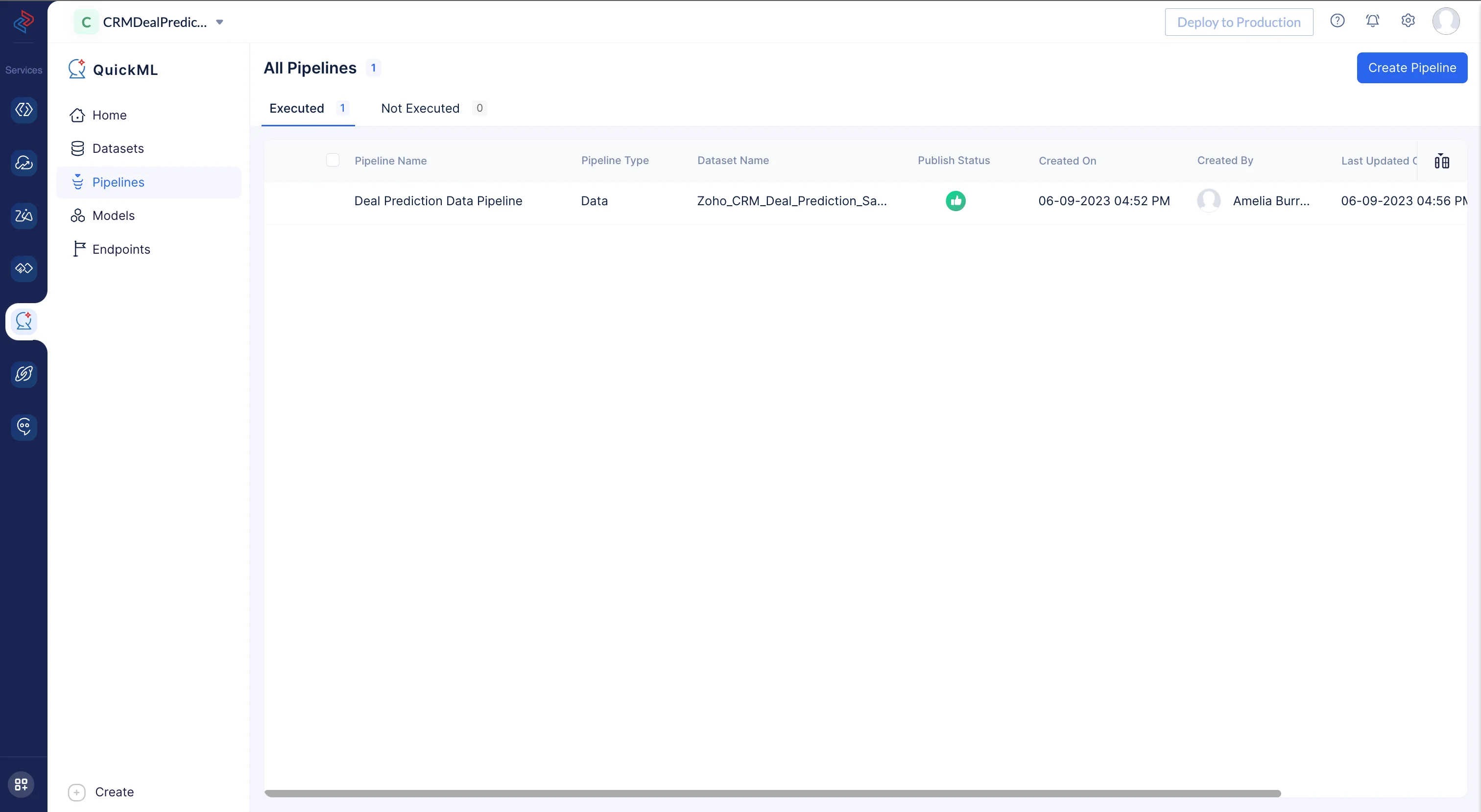
-
表示されるポップアップで、パイプラインタイプとしてPredictionを選択し、パイプライン名を「Deal Prediction ML Pipeline」と入力し、入力データセットとしてZoho_CRM_Deal_Prediction_Sampleを選択します。ここでは、ターゲット列を「Stage」に設定します。モデル名はパイプライン名に基づいて自動的に入力されます。Create Pipelineをクリックします。
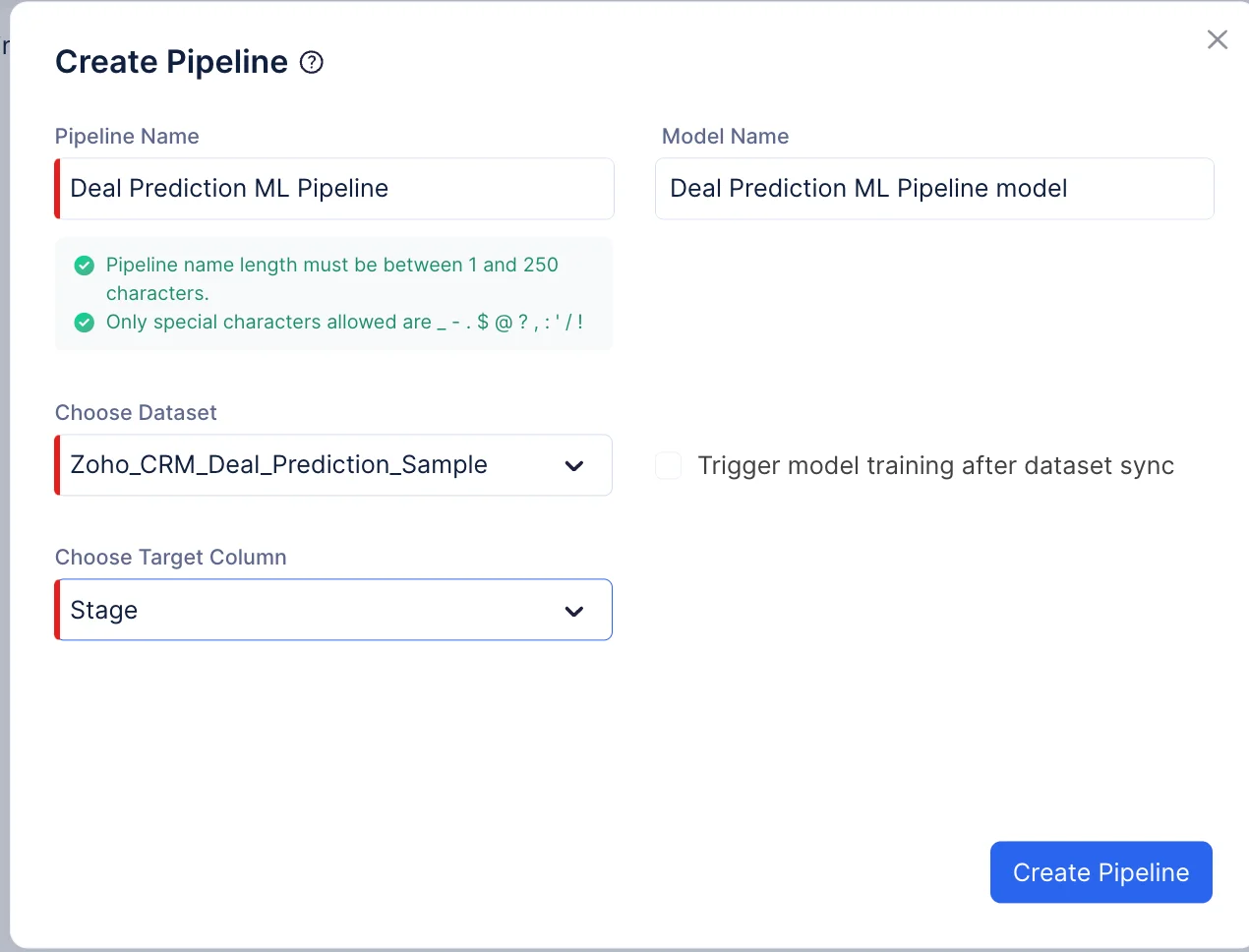
-
以下のスクリーンショットのように、MLパイプラインビルダーインターフェースページが表示されます。
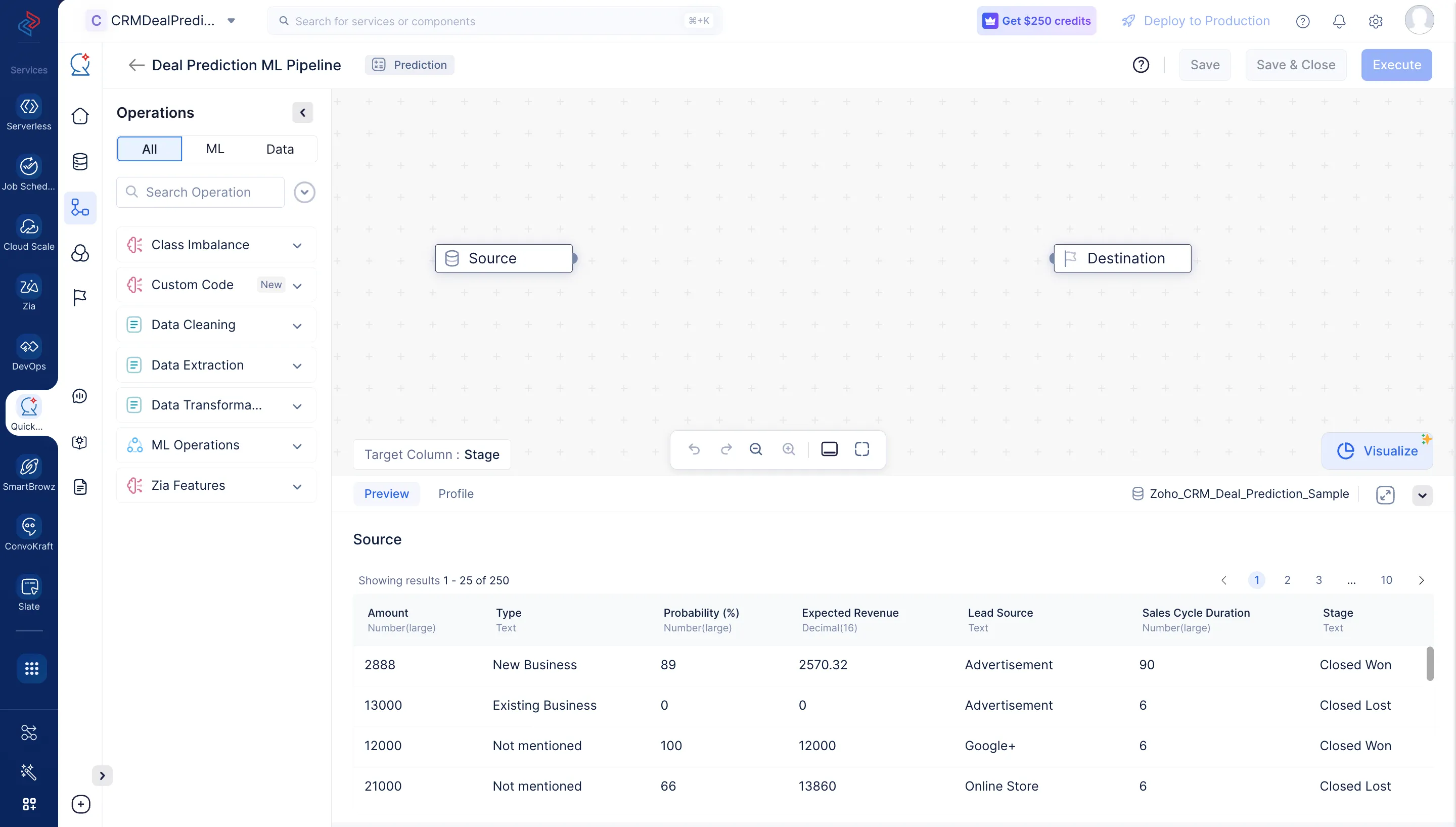
MLパイプラインが作成されたので、MLパイプラインビルダーインターフェースでノードを定義してパイプラインの設定を行います。
カテゴリ列のエンコーディング
ターゲット列「Stage」、「Type」、「Lead Source」にはString型のカテゴリデータが含まれているため、MLトレーニング基準に合わせてエンコードする必要があります。列をエンコードするには、以下の手順に従ってください。
-
Operationsメニューで、ML operations-> Encoding-> Label Encoderに移動します。Label EncoderノードをMLパイプラインビルダーインターフェースにドラッグ&ドロップします。右パネルのLabel Encoder設定セクションで、列として「Stage」を選択し、Saveをクリックします。
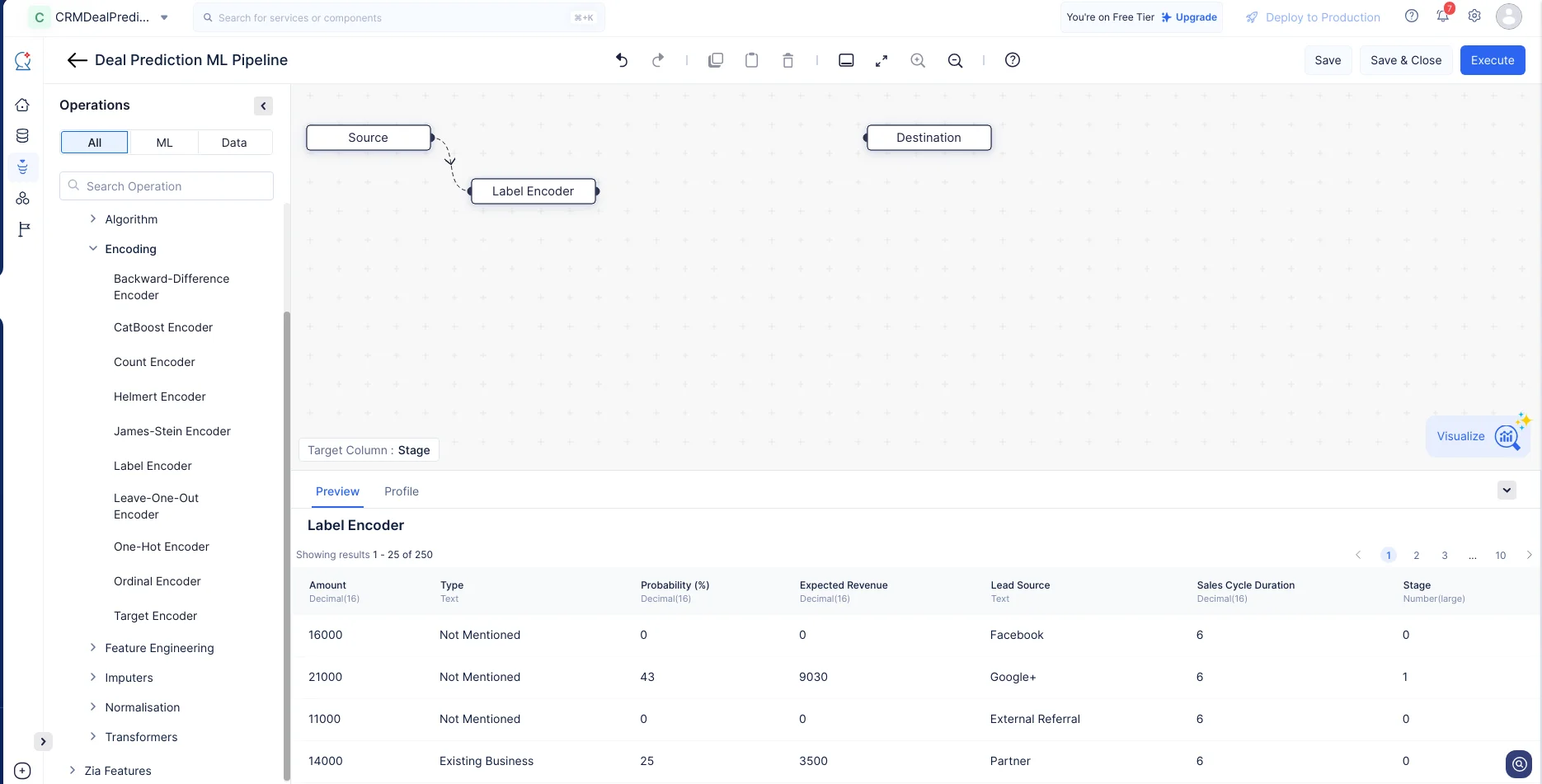
-
同様に、ML operations-> Encoding-> One-Hot Encoderに移動します。One-Hot encoderノードをMLパイプラインビルダーインターフェースにドラッグ&ドロップします。右パネルの設定セクションで、列として「Type」と「Lead Source」を選択し、Saveをクリックします。
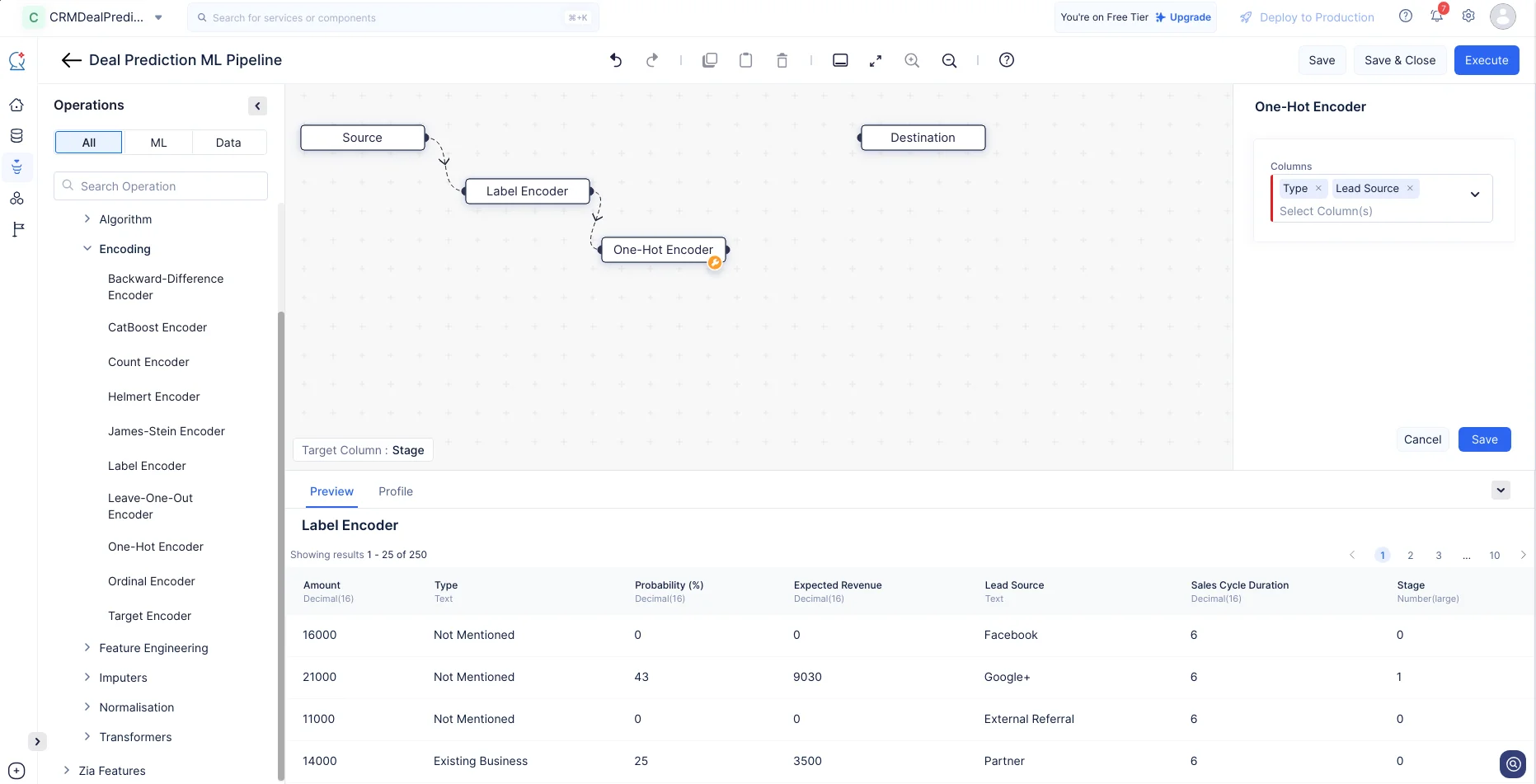
これらのエンコーディング操作により、String型の列の値がInteger型に変換され、順序が維持されデータの正確性が保たれます。
列の正規化
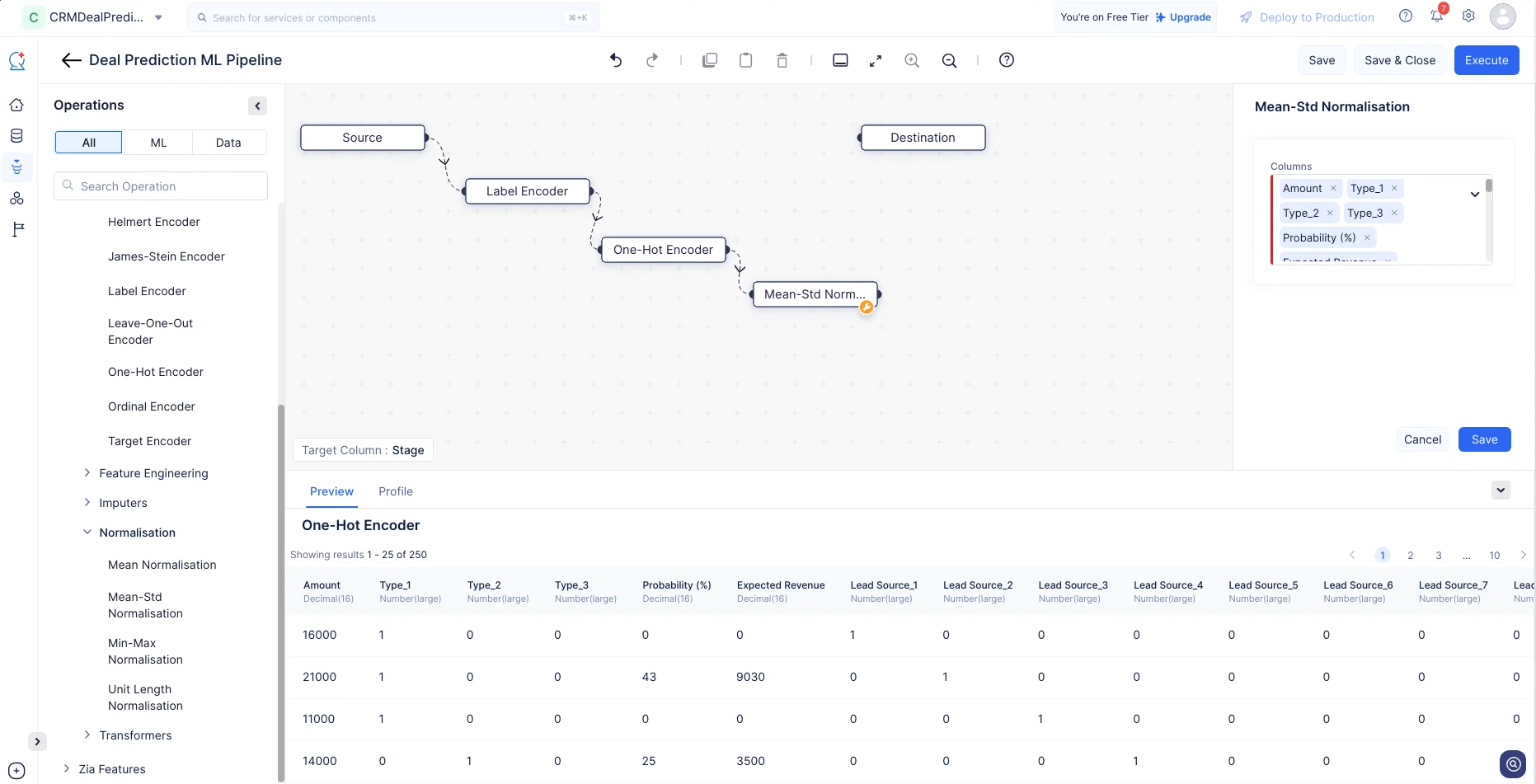
すべての特徴量の値がさまざまな範囲にあるため、Mean - Std Normalizationコンポーネントを使用して、特徴量の値を通常0から1の共通の範囲にスケールダウンします。ML operations-> Normalizationに移動します。Mean-Std NormalizationノードをMLパイプラインビルダーインターフェースにドラッグ&ドロップします。右パネルの設定ボックスで、「Stage」を除くすべての列を選択し、Saveをクリックします。
正規化を適用すると、MLパイプラインビルダーページは以下のように表示されます。
MLアルゴリズムとハイパーパラメータチューニング
MLモデルには、モデルのトレーニングの基盤となるMLアルゴリズムの実装が必要です。このチュートリアルでは、Random-Forest Classificationアルゴリズムを実装して、前処理済みデータセットに最適化されたMLモデルのチューニングパラメータを設定します。
-
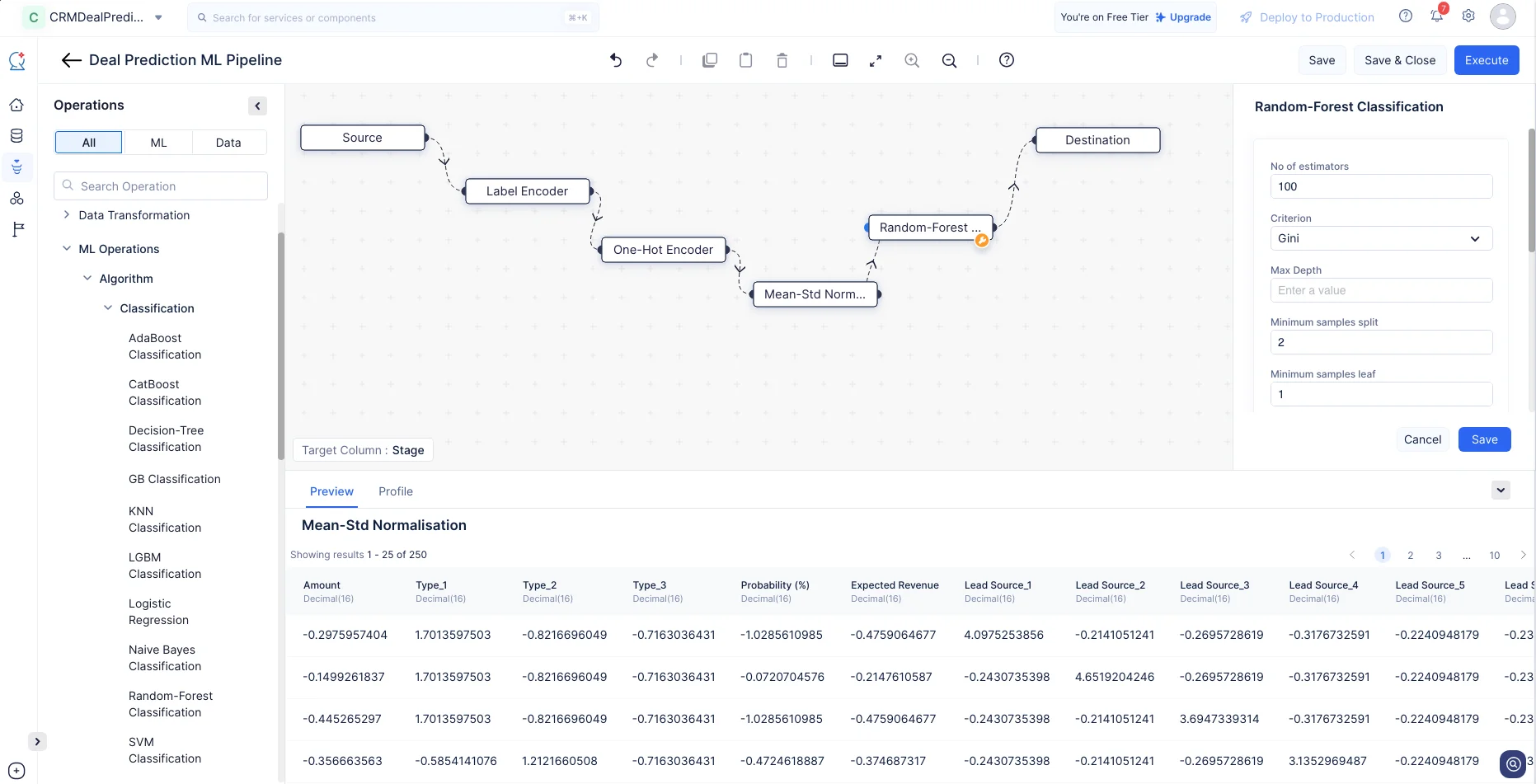
Operationsメニューで、ML operations-> Algorithm-> Classificationを展開します。Random-Forest Classificationノードをパイプラインビルダーにドラッグ&ドロップします。ノードは自動的にDestinationノードに接続されます。Mean-Std NormalizationとRandom-Forest Classificationノード間に入力接続を作成します。
-
Random-Forest Classificationノードについては、デフォルト設定のままSaveをクリックします。
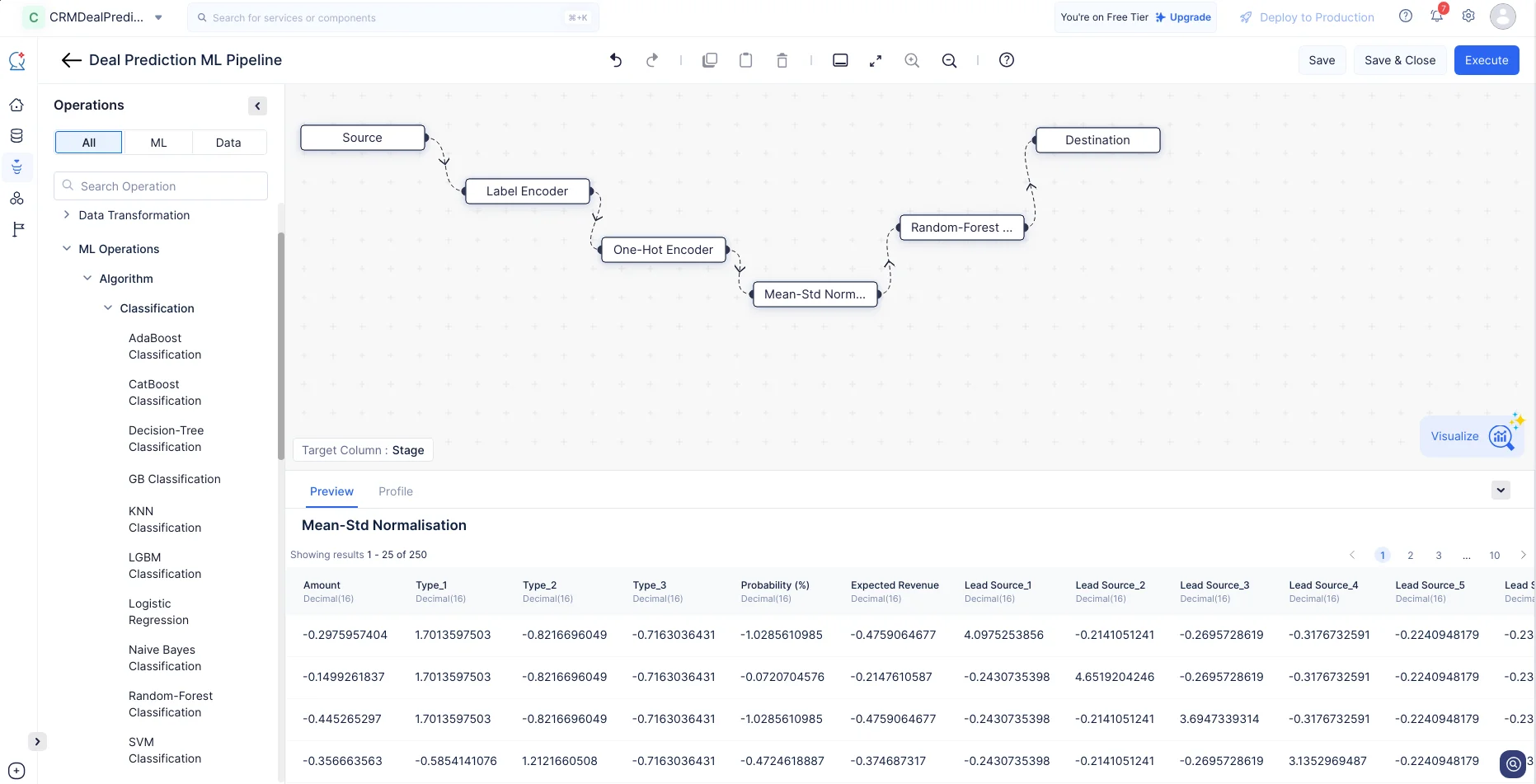
これで、必要なノードの接続と設定がすべて完了しました。Executeをクリックしてパイプラインを実行し、評価とデプロイに進みます。
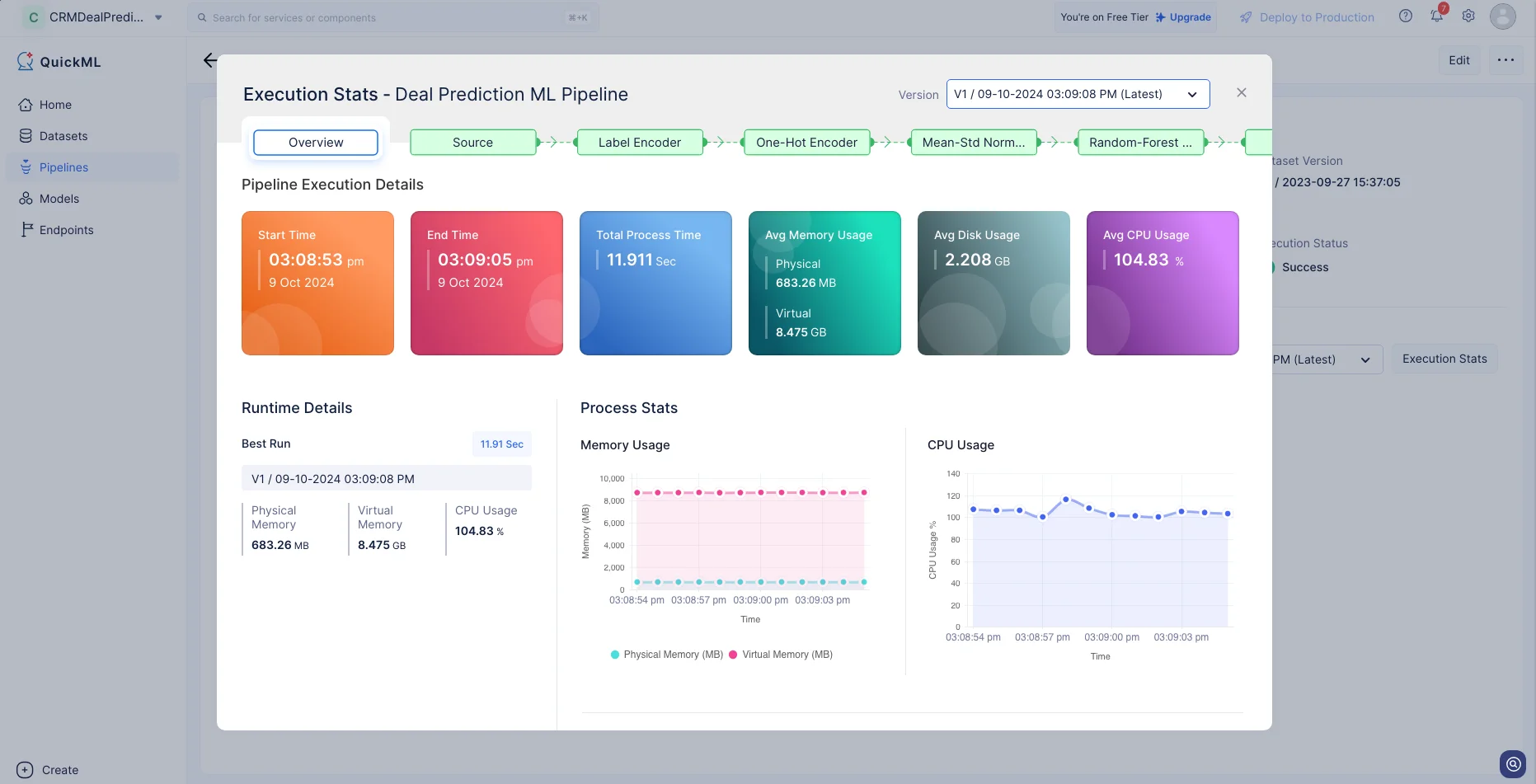
Execution Statsをクリックすると、実行の各ステージの詳細を確認できます。
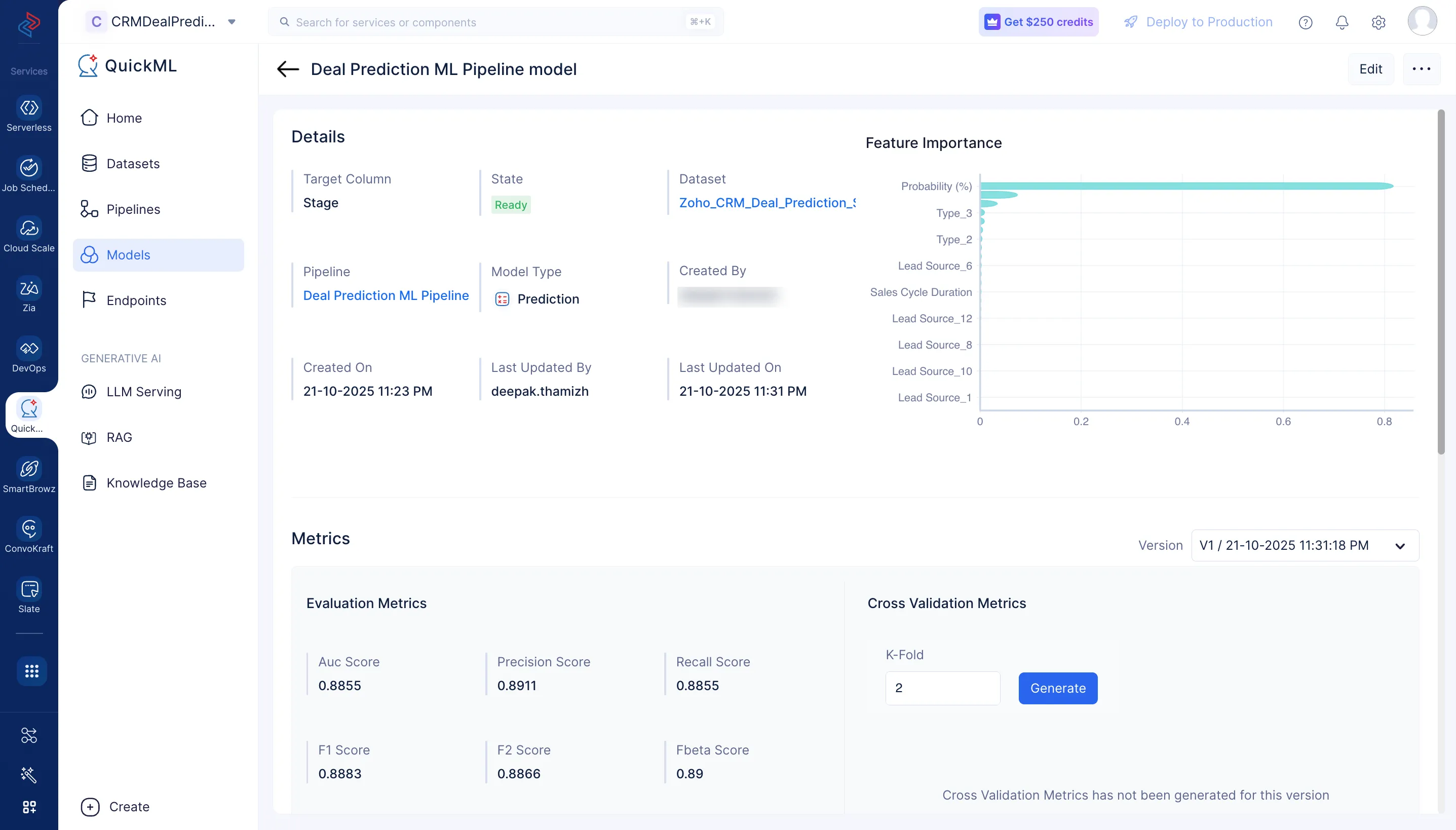
MLパイプラインが正常に実行されると、Deal Predictionモデルが作成され、Modelsセクションに表示されます。
モデル名をクリックすると、モデルの詳細ページでモデルの詳細を確認できます。
最終更新日 2026-03-05 11:43:24 +0530 IST