Crear un ML pipeline
En esta sección, construiremos un modelo de predicción de ML usando el dataset preprocesado de la sección anterior. Este dataset será la entrada al ML pipeline builder que te permite definir la arquitectura del modelo y seleccionar una columna objetivo para la predicción.
Para crear un ML pipeline, asegúrate de seguir los pasos a continuación.
-
Navega al componente Pipelines en el menú izquierdo y haz clic en Create Pipeline.
-
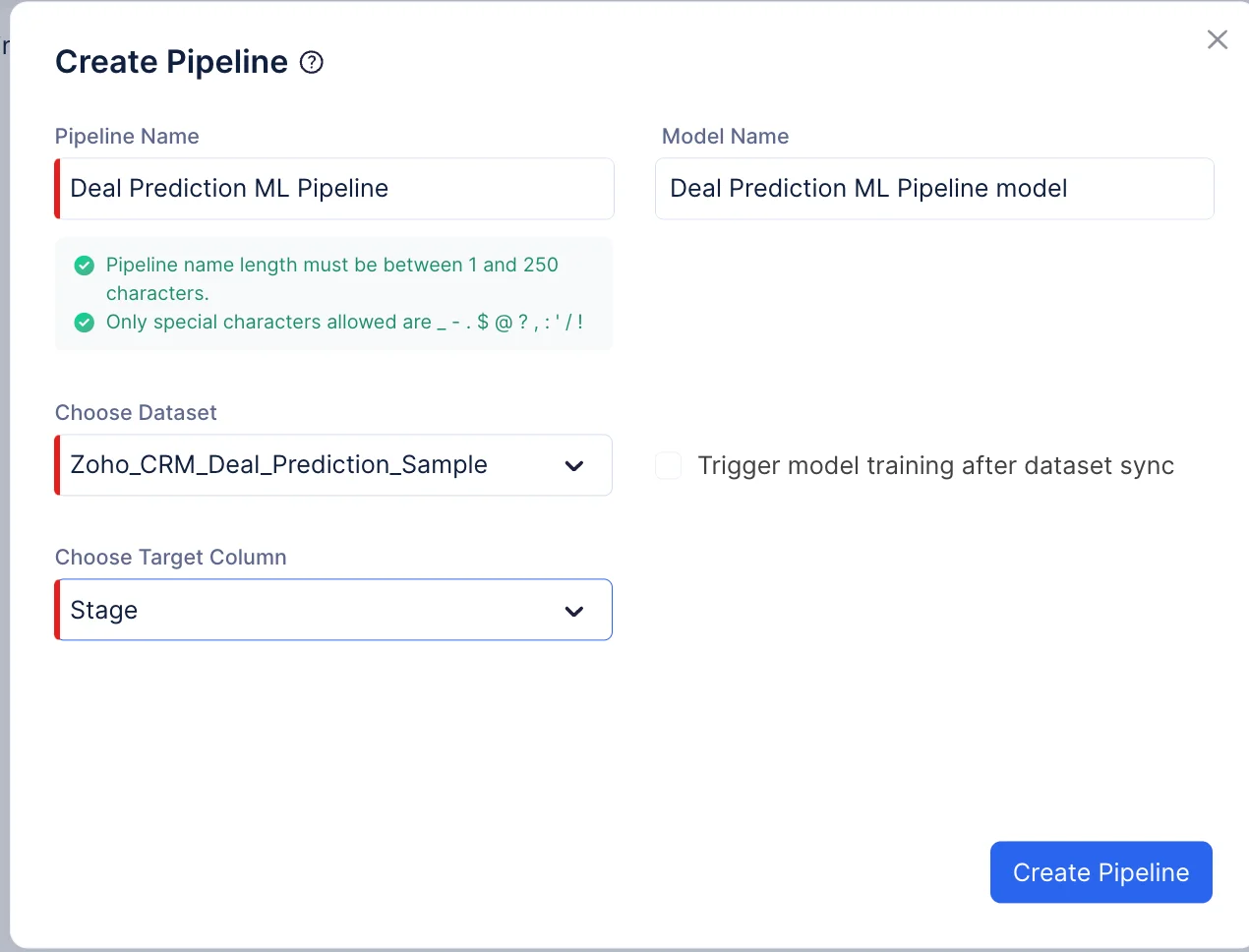
En el pop-up que aparece, selecciona Prediction como tipo de pipeline y nombra el pipeline “Deal Prediction ML Pipeline” y elige el dataset de entrada como Zoho_CRM_Deal_Prediction_Sample. En nuestro caso, la columna objetivo debe ser “Stage”. El nombre del modelo se completará automáticamente basándose en el nombre del pipeline. Haz clic en Create Pipeline.
-
La página de la interfaz del ML pipeline builder se mostrará como en la captura de pantalla a continuación.
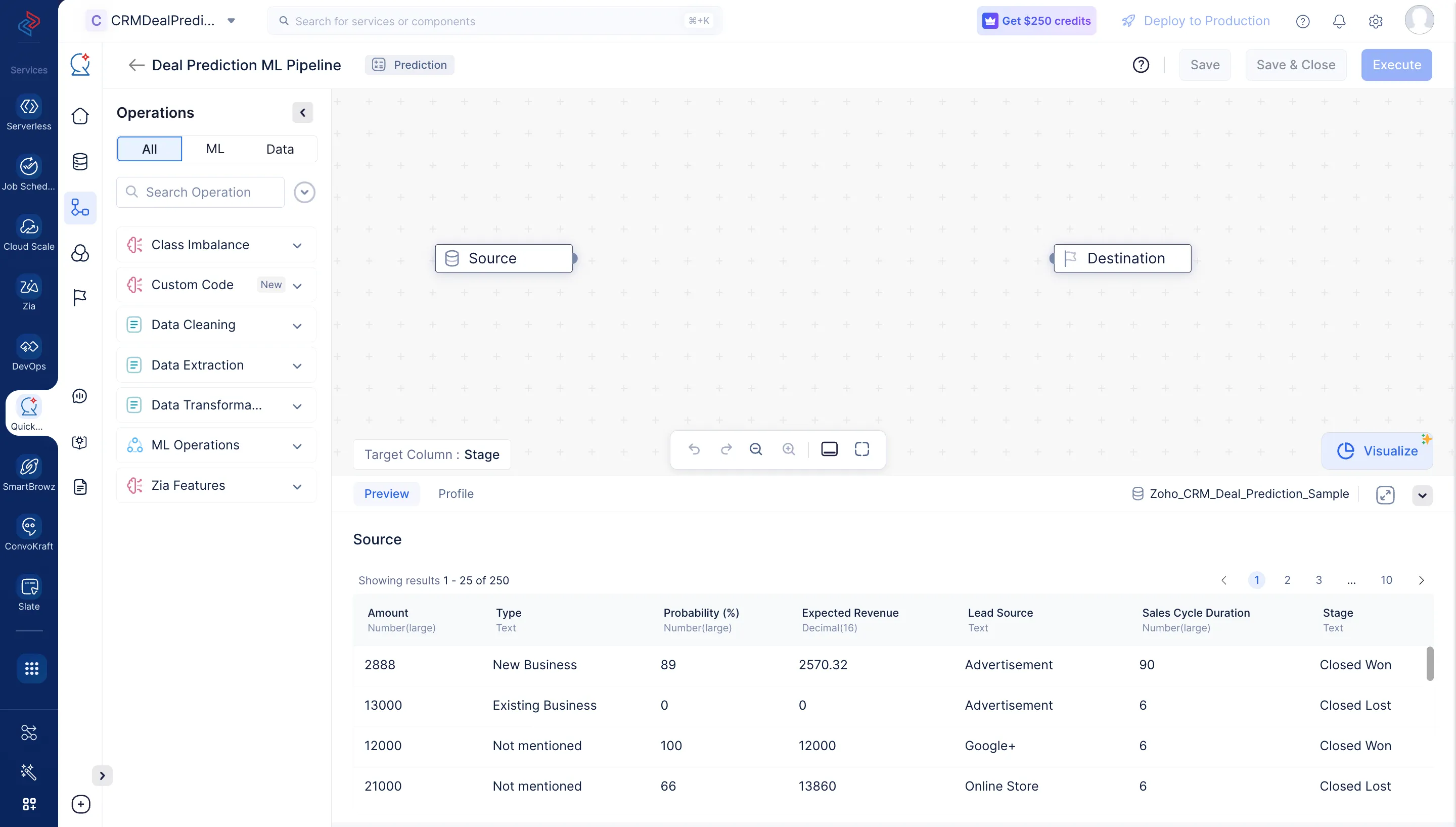
Ahora que hemos creado nuestro ML pipeline, procederemos a configurar el pipeline definiendo los nodos en la interfaz del ML pipeline builder.
Codificar columnas categóricas
Dado que nuestra columna objetivo “Stage”, “Type” y “Lead Source” contienen datos categóricos de tipo String, las codificaremos para los estándares de entrenamiento de ML posteriores. Asegúrate de seguir los pasos a continuación para codificar las columnas.
-
En el menú de Operations, navega a ML operations-> Encoding-> Label Encoder. Arrastra y suelta el nodo Label Encoder en la interfaz del ML pipeline builder. En la sección de configuración de Label Encoder en el panel derecho, elige la columna como “Stage” y haz clic en Save.
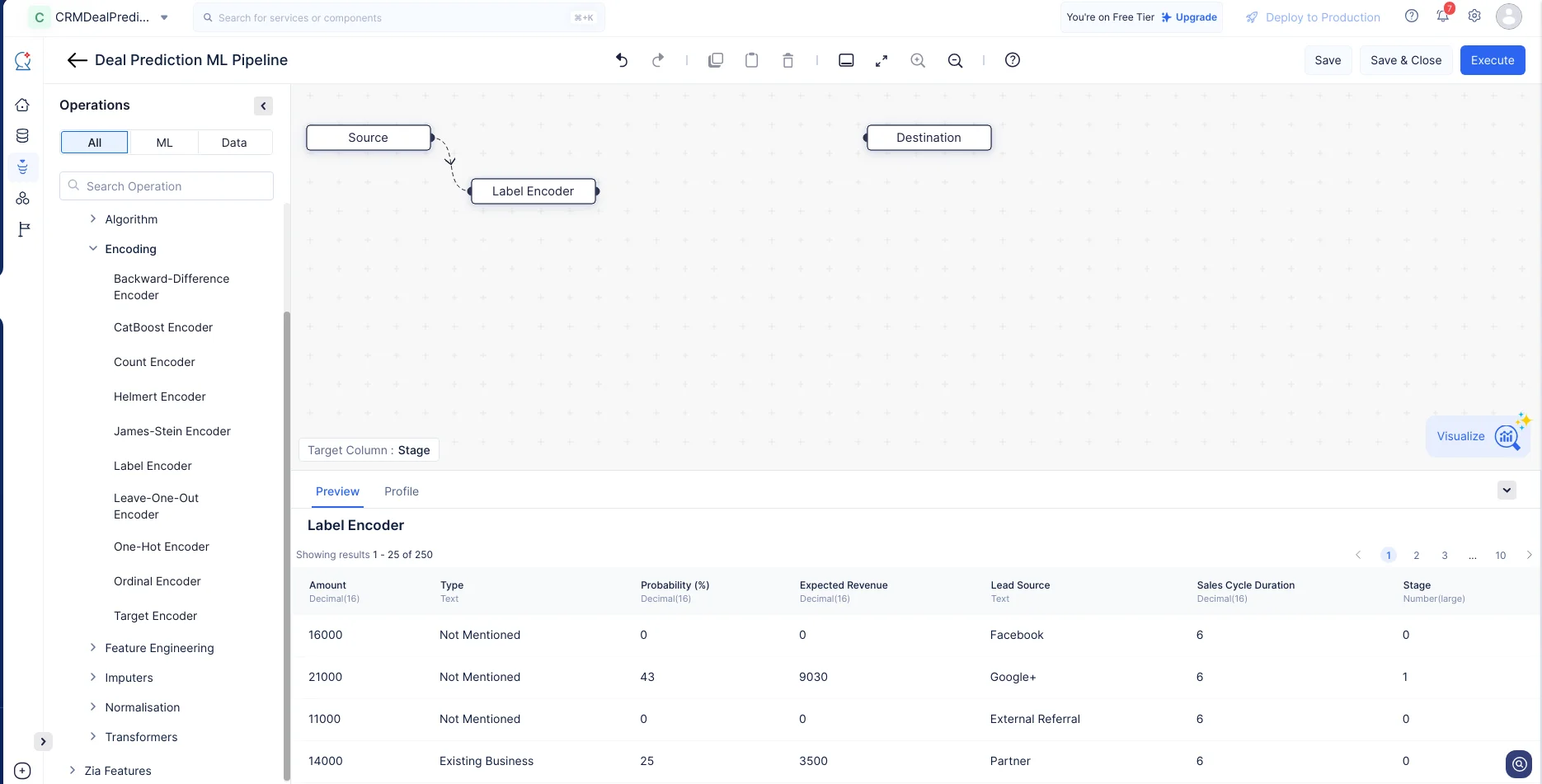
-
De la misma manera, navega a ML operations-> Encoding-> One-Hot Encoder. Arrastra y suelta el nodo One-Hot encoder en la interfaz del ML pipeline builder. En la sección de configuración del panel derecho, elige las columnas como “Type” y “Lead Source”, y haz clic en Save.
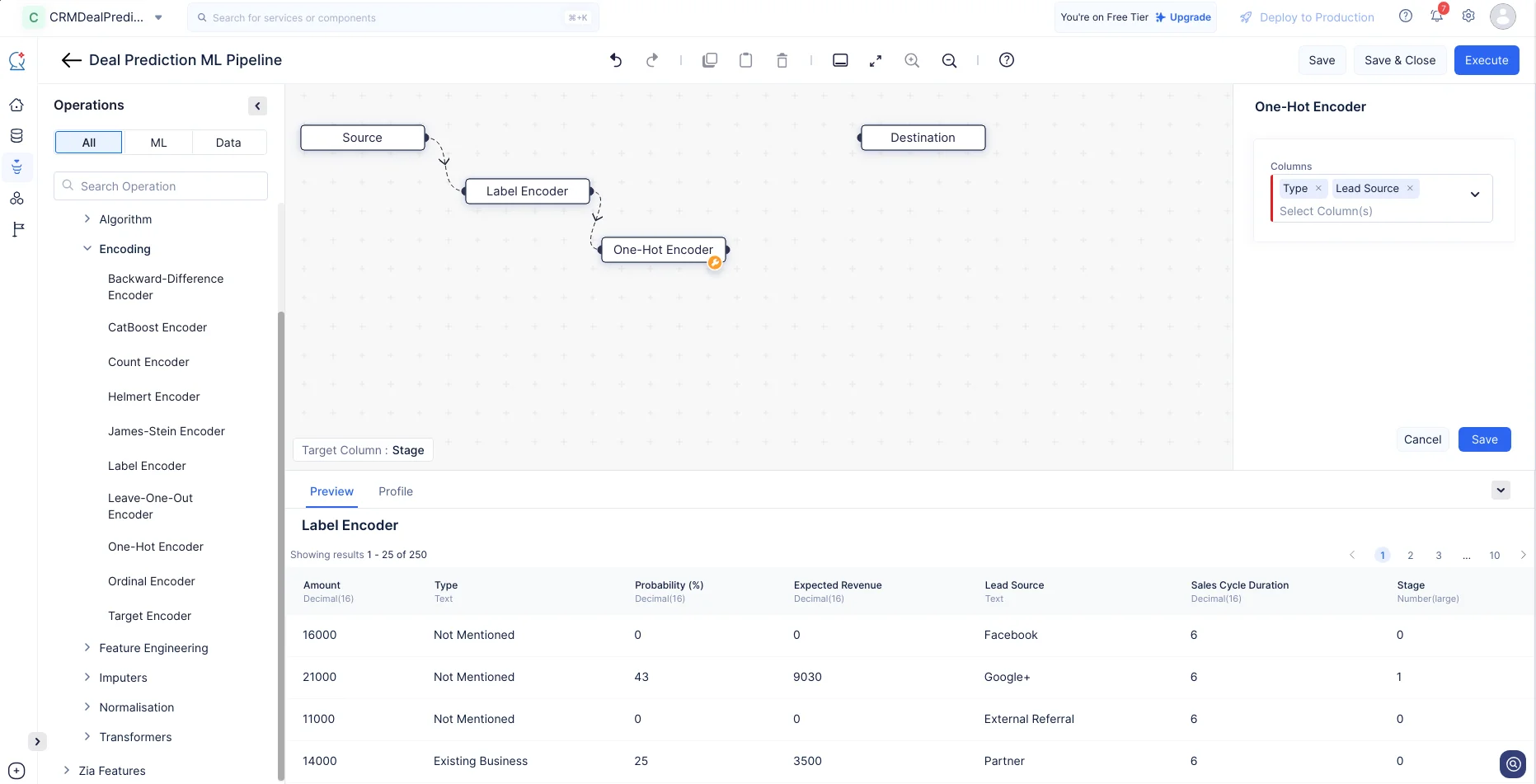
Estas operaciones de codificación convertirán los valores de las columnas de tipo String a Integer, manteniendo el orden y preservando la precisión de los datos.
Normalizar las columnas
Dado que los valores de todas las características están en varios rangos, usaremos el componente Mean - Std Normalization para escalar los valores de las características a un rango común, típicamente entre 0 y 1. Navega a ML operations-> Normalization. Arrastra y suelta el nodo Mean-Std Normalization en la interfaz del ML pipeline builder. En el cuadro de configuración del panel derecho, elige todas las columnas excepto “Stage” y haz clic en Save.
Una vez aplicada la normalización, la página del ML pipeline builder se mostrará como a continuación:
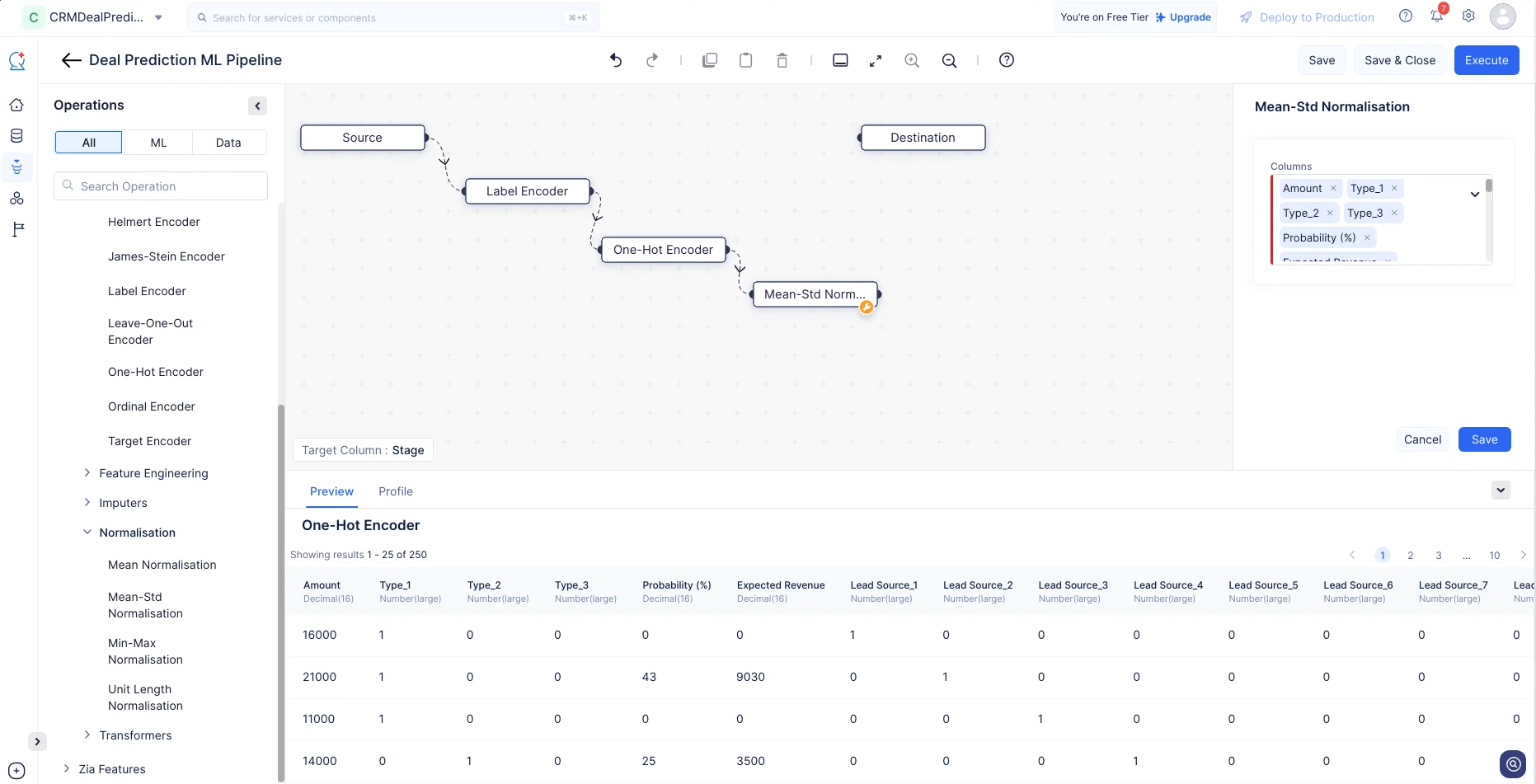
Algoritmo de ML y ajuste de hiperparámetros
Para cualquier modelo de ML, es necesario implementar un algoritmo de ML basándose en el cual el modelo será entrenado. En este tutorial, implementaremos el algoritmo de clasificación Random-Forest para configurar los parámetros de ajuste para el modelo de ML y asegurar que esté optimizado para nuestro dataset preprocesado.
-
En el menú de Operations, expande ML operations-> Algorithm-> Classification. Arrastra y suelta el nodo Random-Forest Classification en el pipeline builder. El nodo se conectará automáticamente al nodo Destination. Haz una conexión de entrada entre el nodo Mean-Std Normalization y el nodo Random-Forest Classification.
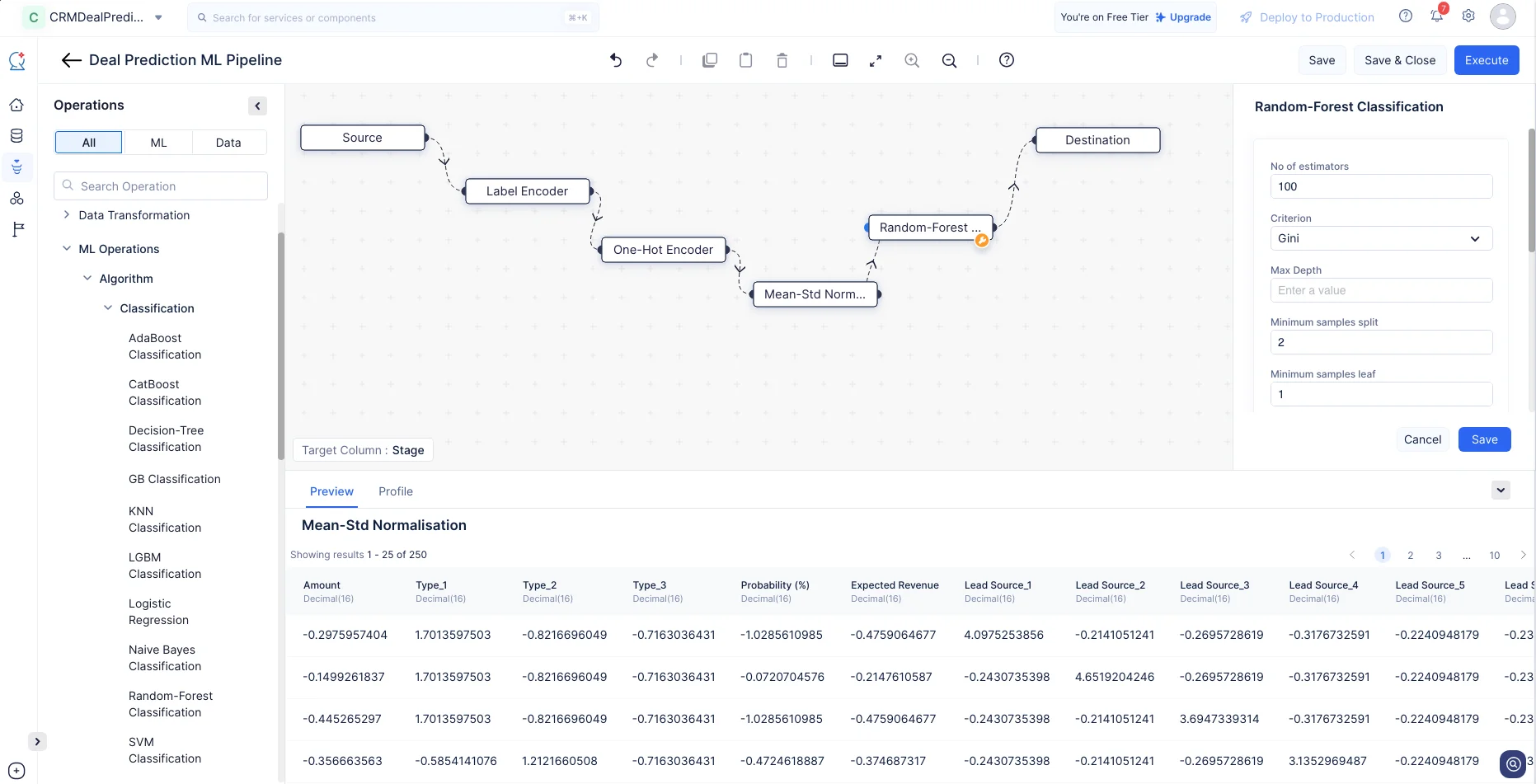
-
Para el nodo Random-Forest Classification, mantendremos la configuración predeterminada y haremos clic en Save.
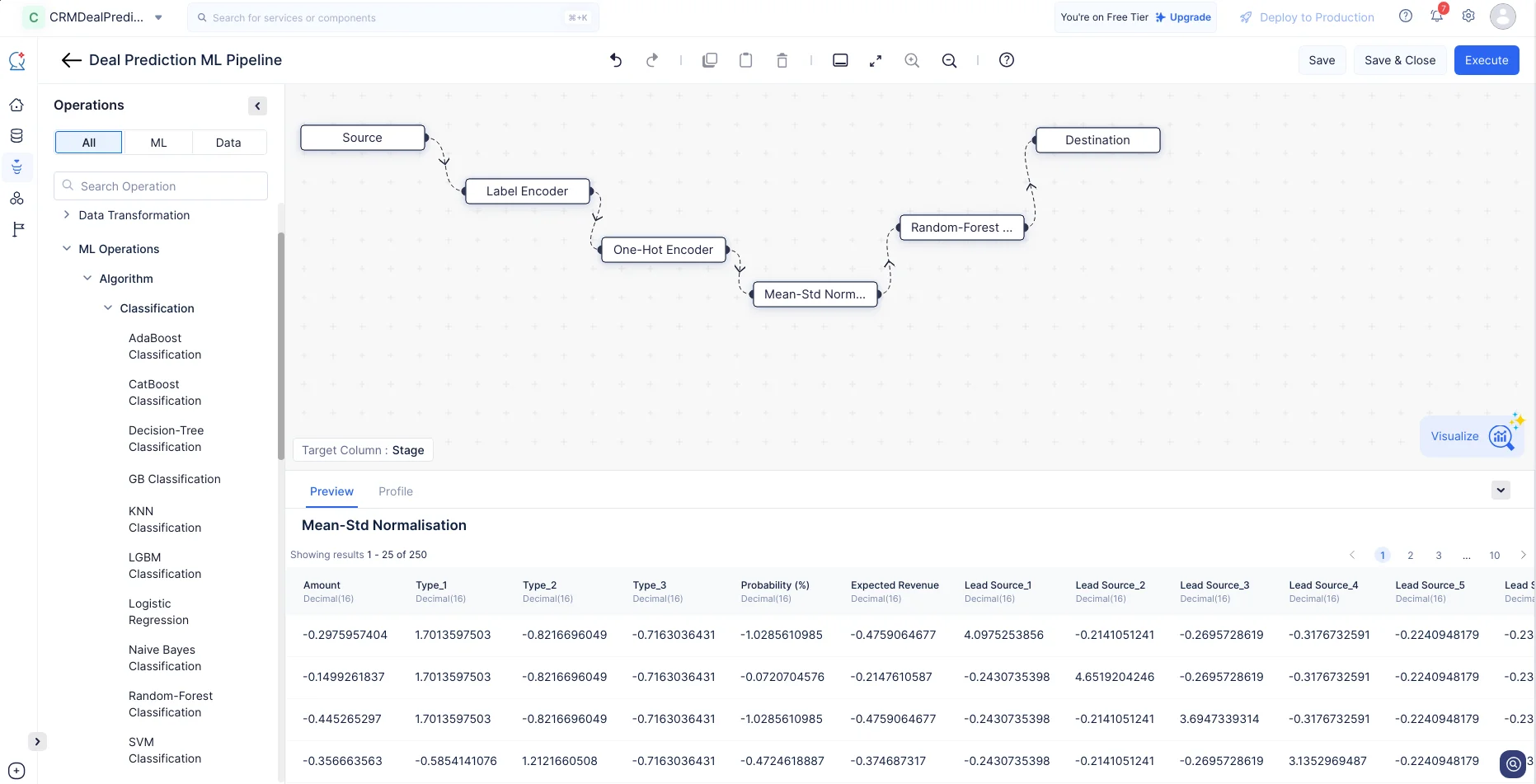
Ahora, hemos completado las conexiones y configuraciones de nodos requeridas. Podemos proceder a ejecutar el pipeline haciendo clic en Execute para evaluación y despliegue posteriores.
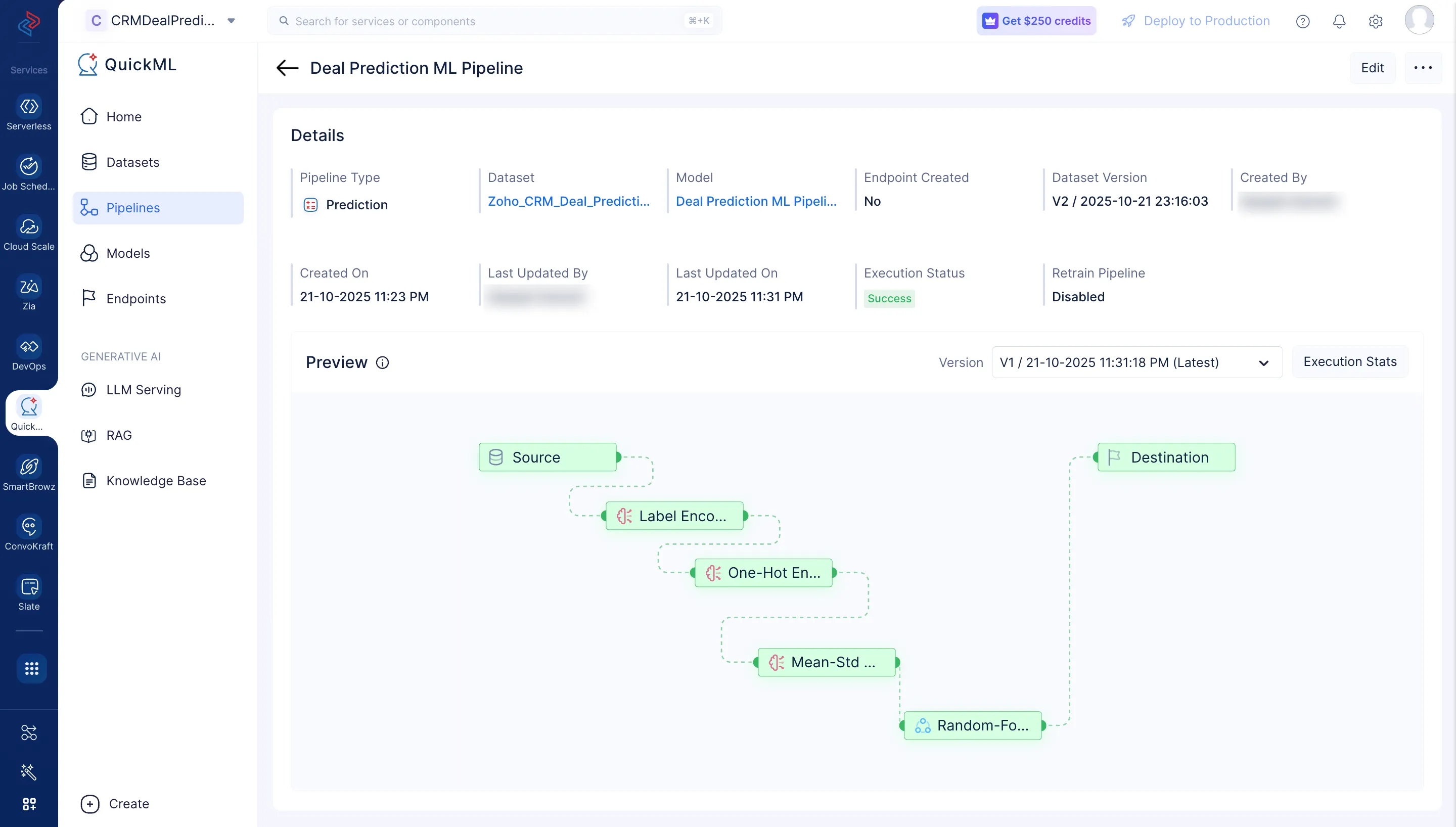
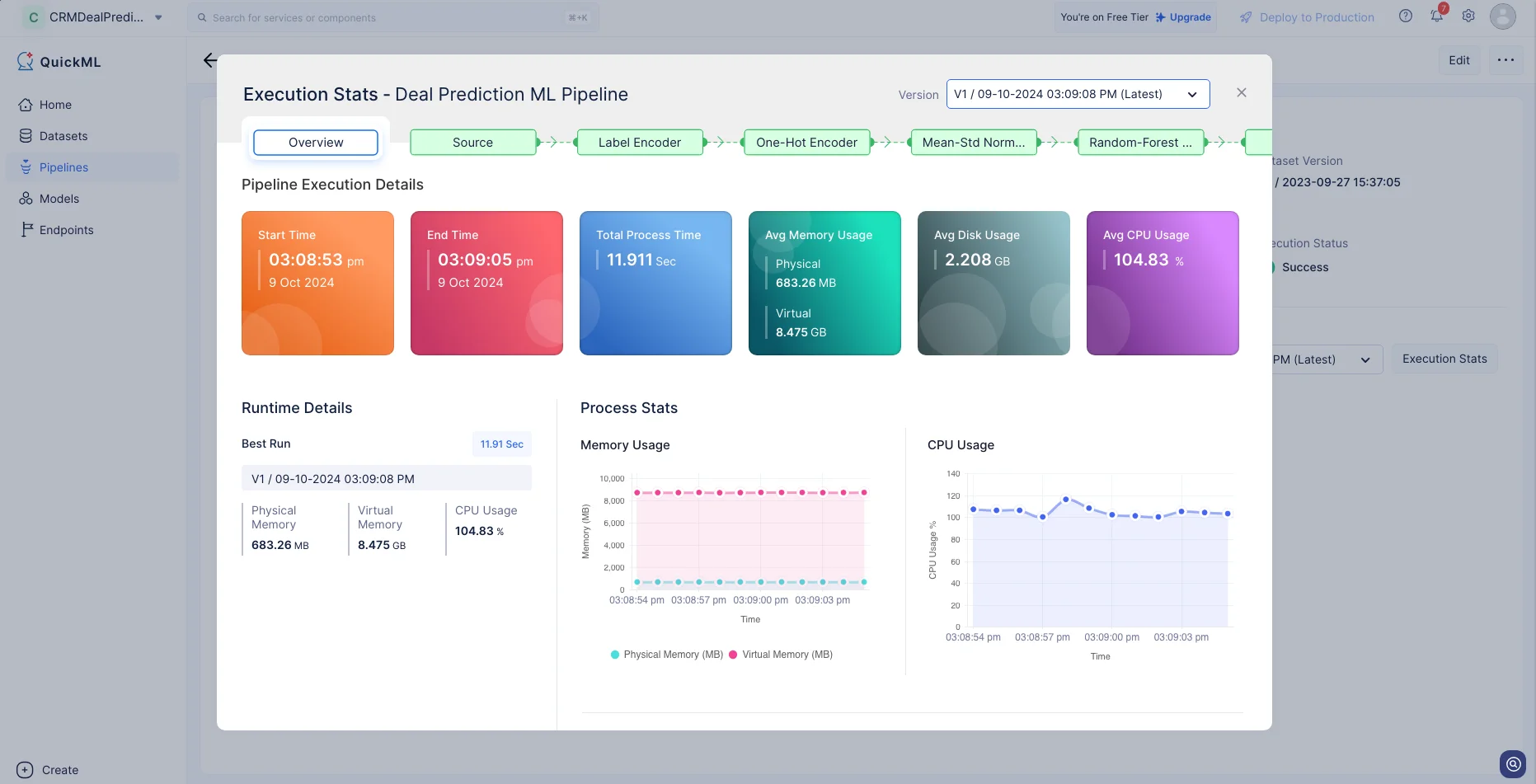
Haz clic en Execution Stats para ver más detalles sobre cada etapa de la ejecución en detalle.
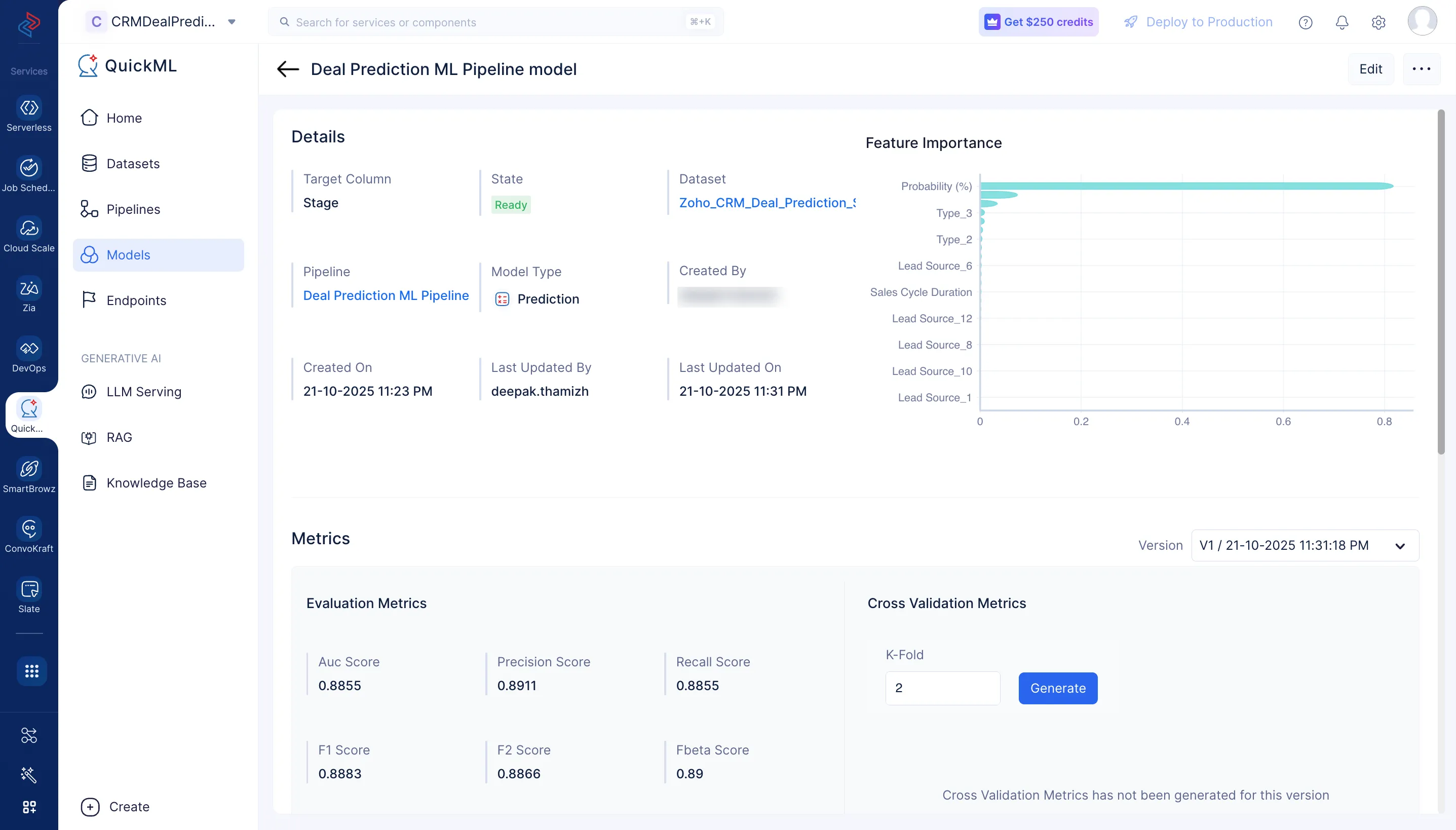
Tras la ejecución exitosa del ML pipeline, el modelo de Deal Prediction está creado y se mostrará en la sección Models.
Puedes ver los detalles del modelo en la página de detalles del modelo haciendo clic en el nombre del modelo.
Última actualización 2026-03-20 21:51:56 +0530 IST