Create an ML pipeline
To build the prediction model, we will use the preprocessed dataset in the ML Pipeline Builder. The initial step in building the ML Pipeline involves selecting the target column, which is the column that we are trying to predict.
To create an ML pipeline, first Navigate to the Pipelines component and click on the Create Pipeline option.
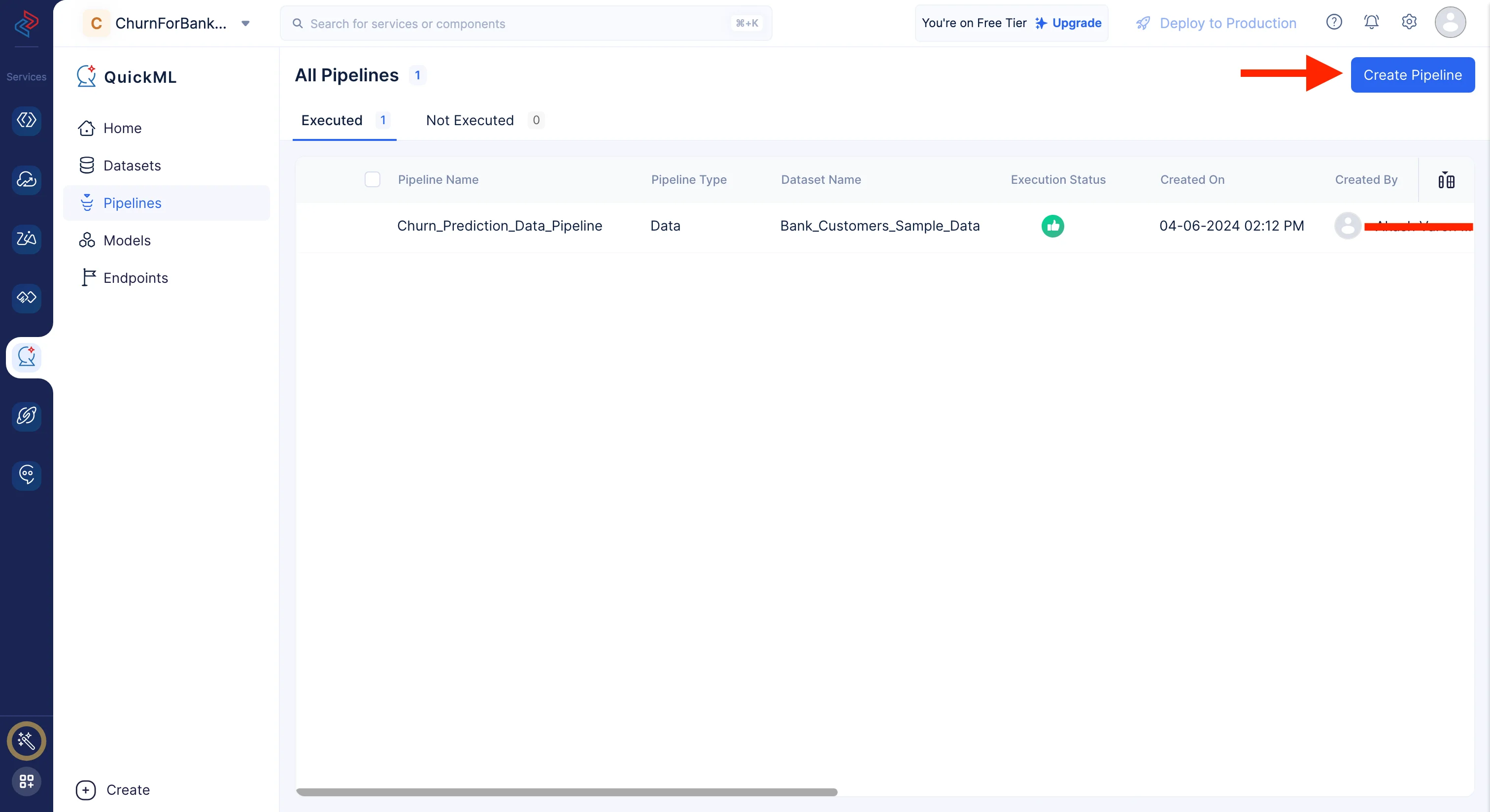
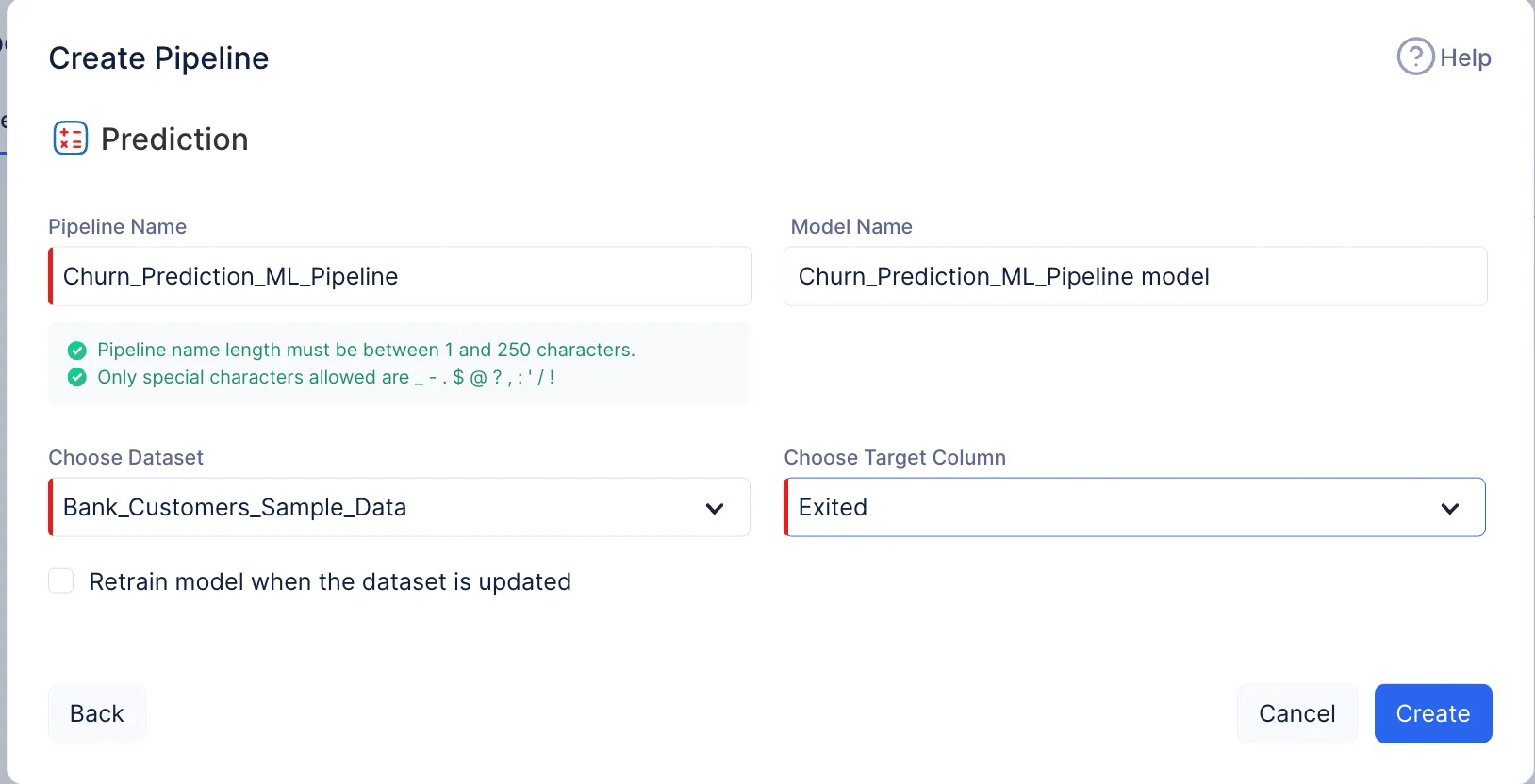
In the pop-up that appears, select Prediction as pipeline type and provide the pipeline name, we’ll name the pipeline as Churn_Prediction_ML_Pipeline and the model Churn_Prediction_ML_Pipeline Model in the Create Pipeline pop-up. Then, select the appropriate dataset and the column name of the target.
We need to select the source dataset that is chosen for building the data pipeline, as the preprocessed data is reflected in the source dataset. In our case, we will be importing the Bank_Customers_Sample_Data dataset, as we have selected it for preprocessing and cleaning, and our target is the column named Exited.
-
Imputers
Imputers are used in various fields, such as data analysis, statistics, and machine learning to handle missing or incomplete data. Here, we are using mean imputer by importing it from ML operations > Imputers > Mean Imputer for imputing the missing values in the dataset. Mean Imputing & Mode Imputing refers to a data imputation technique where missing values are filled based on some mean or mode of selected columns.
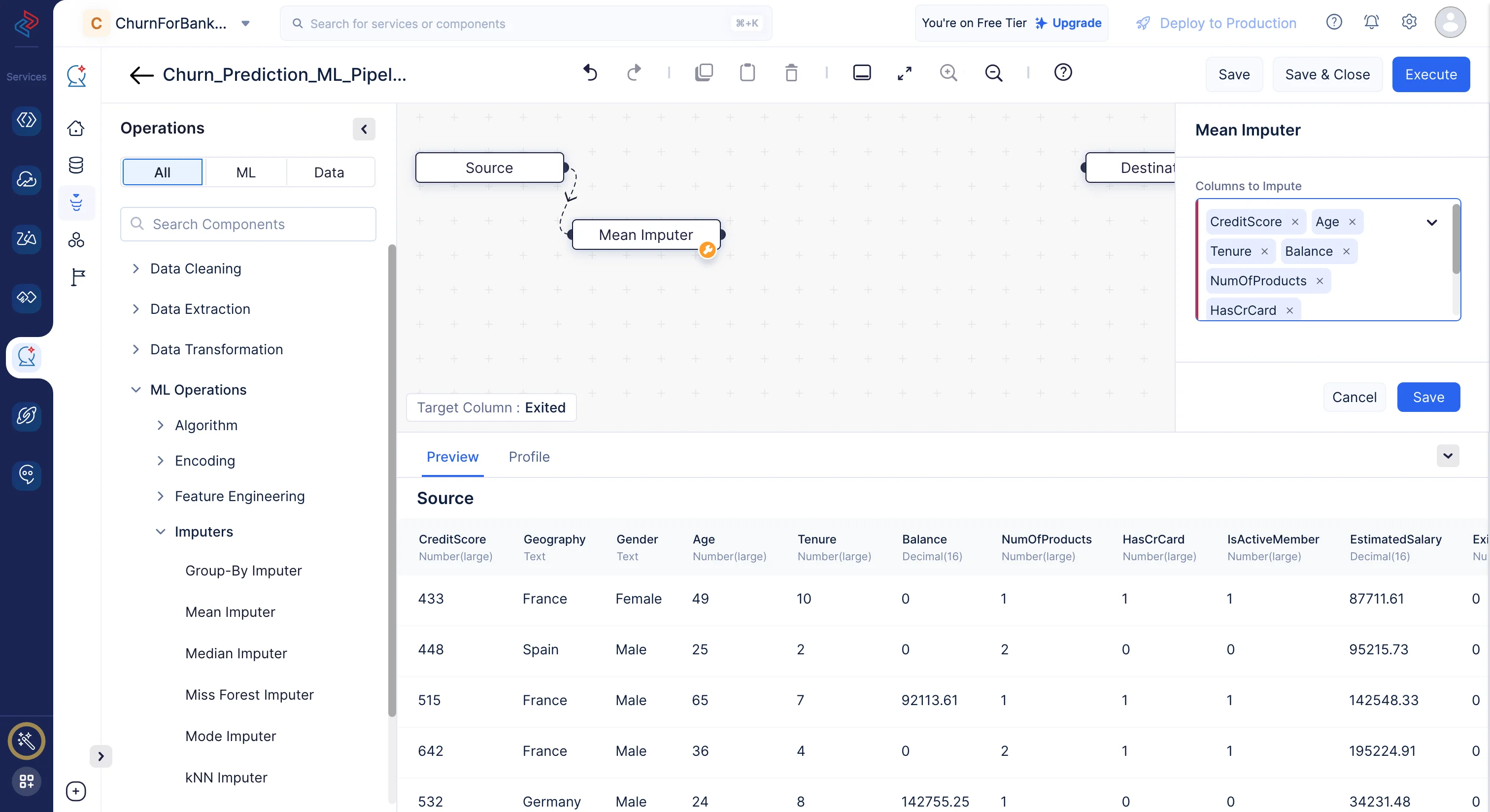
Here, the columns should not contain empty values for best model predictions are “CreditScore”,"Age","Tenure","Balance","NumOfProducts","HasCrCard","IsActiveMember","EstimatedSalary" imputed by its mean values and the few columns that are imputed by their mode are “Gender”,"Geography".
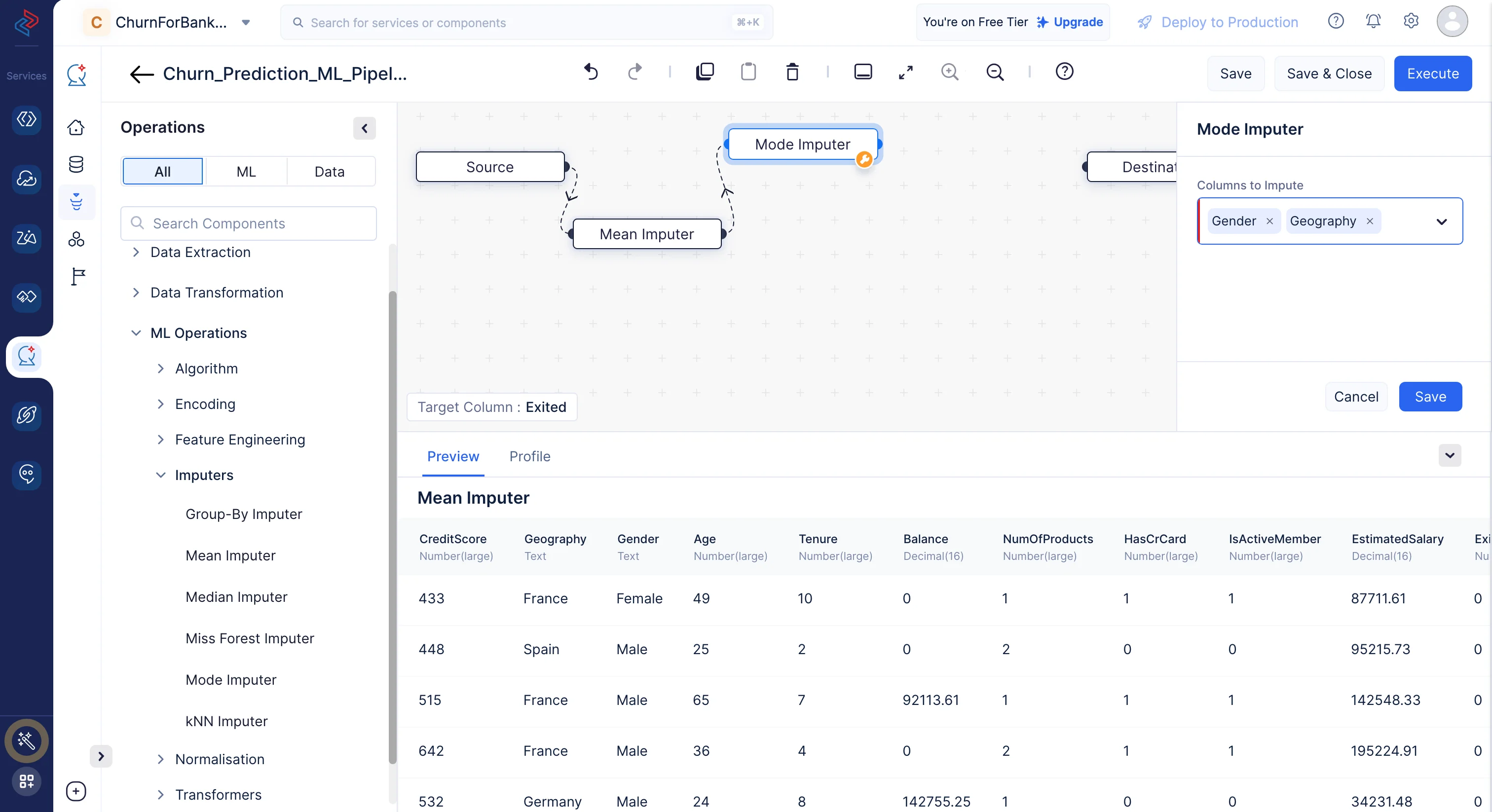
-
Encoding
Encoders are used in various data preprocessing and machine learning tasks to convert categorical or non-numeric data into a numerical format that machine learning algorithms can work with effectively.
Ordinal encoding
Here, we are using ordinal encoding to encode the following categorical features: “gender”. It assigns integers to the categories based on their order, making it possible for machine learning algorithms to capture the ordinal nature of the data. We’ll use the Ordinal Encoder node by navigating to ML operations, clicking the ->Encoding component, and choosing -> Ordinal Encoder in QuickML to turn the selected category columns into numerical columns.
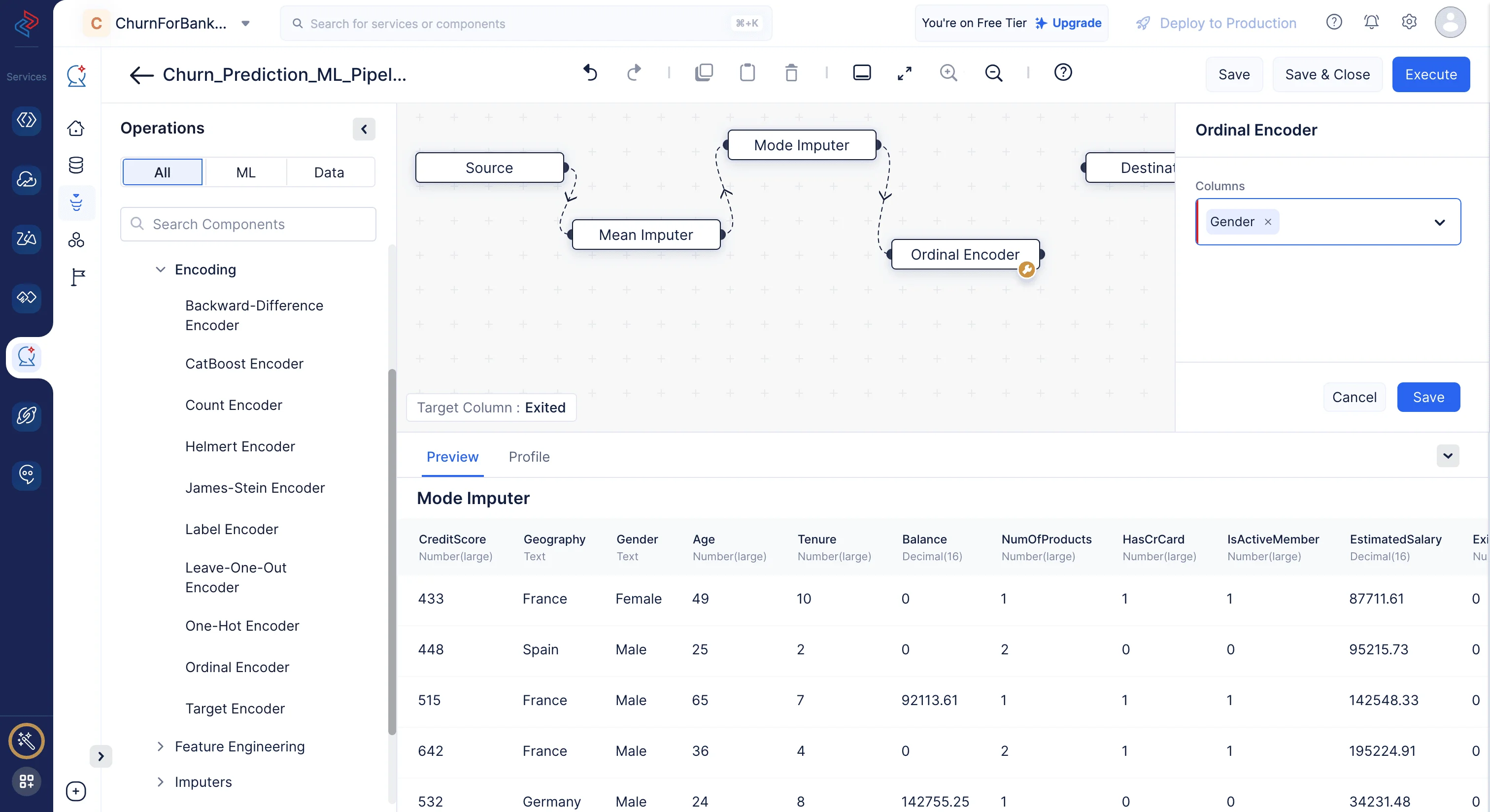
Ordinal Encoder
Ordinal Encoding involves mapping each unique label to an integer value. This type of encoding is really only appropriate if there is a known relationship between the categories. If the data is ordered, we can use ordinal encoding.
Here we aare using Ordinal Encoder node to encode the Gender column. We can use the Ordinal Encoder node from ML Operations > Encoding > Ordinal Encoder in QuickML to turn the category columns into numerical columns. Here, we are converting all categorical columns to numerical format while retaining the columns’ original order and data for model training.
-
One-hot encoding
One-hot encoding is typically applied to categorical columns in a dataset, where each category represents a distinct class or group. This method typically increases the dimensionality of the dataset because it creates a new binary column for each unique category. The number of binary columns is equal to the number of unique categories minus one, as you can infer the presence of the last category from the absence of all others.
Here, we are using One-Hot Encoder node to encode the following column: “Geography”. We’ll use the One-Hot Encoder node by navigating to ML operations, selecting the -> Encoding component and choosing -> One-Hot Encoder in QuickML to turn the selected category columns into numerical columns.
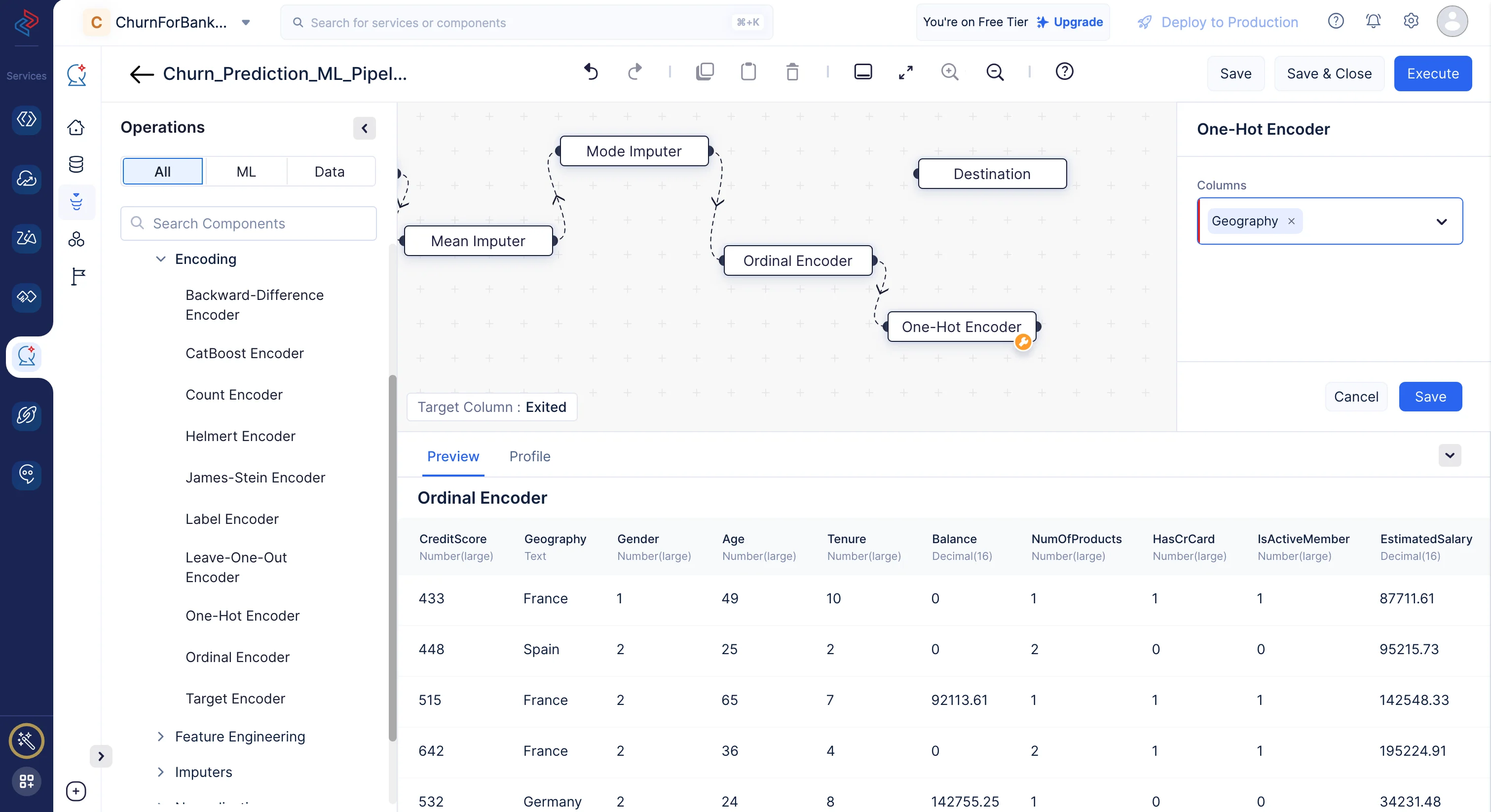
-
Normalize the columns
Navigate to ML operations-> Normalization. Drag and drop the Min-Max Normalization node to the ML pipeline builder interface. In the configuration box on the right panel, choose all the columns except Exited which is the target and click Save.
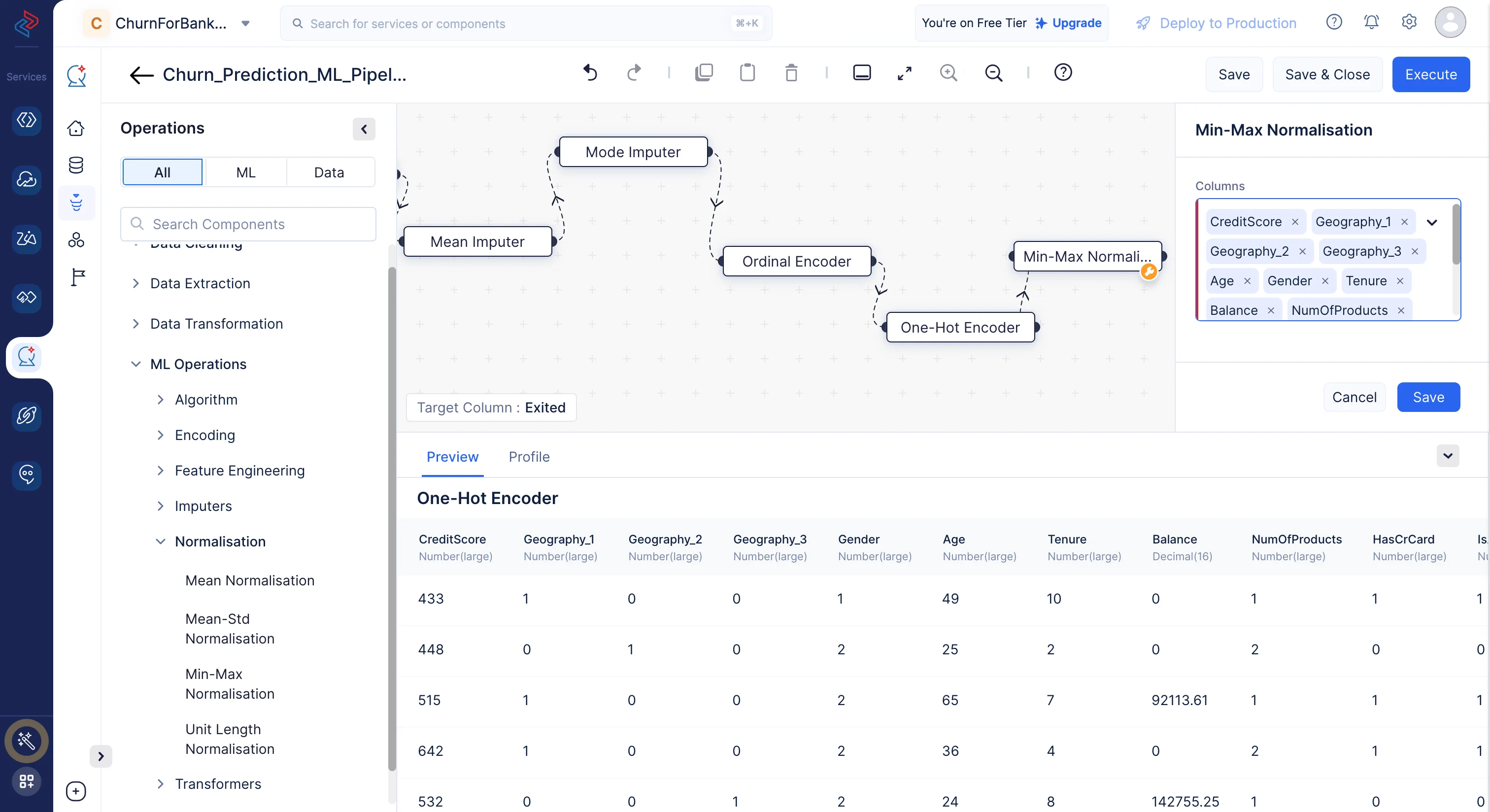
-
Feature Engineering:
Feature selection is the process of choosing a subset of the most relevant and important features (variables or columns) from the dataset to use in model training and analysis. The goal of feature selection is to improve the performance, efficiency, and interpretability of machine learning models. Feature selection is particularly crucial when dealing with high-dimensional datasets, as it can help reduce overfitting, reduce computation time, and enhance model interpretability.
Here we are using the PCA feature selection technique to generate the features. Select PCA node by navigating to ML operations, clicking ->Feature Engineering, and choosing ->Feature Reduction.
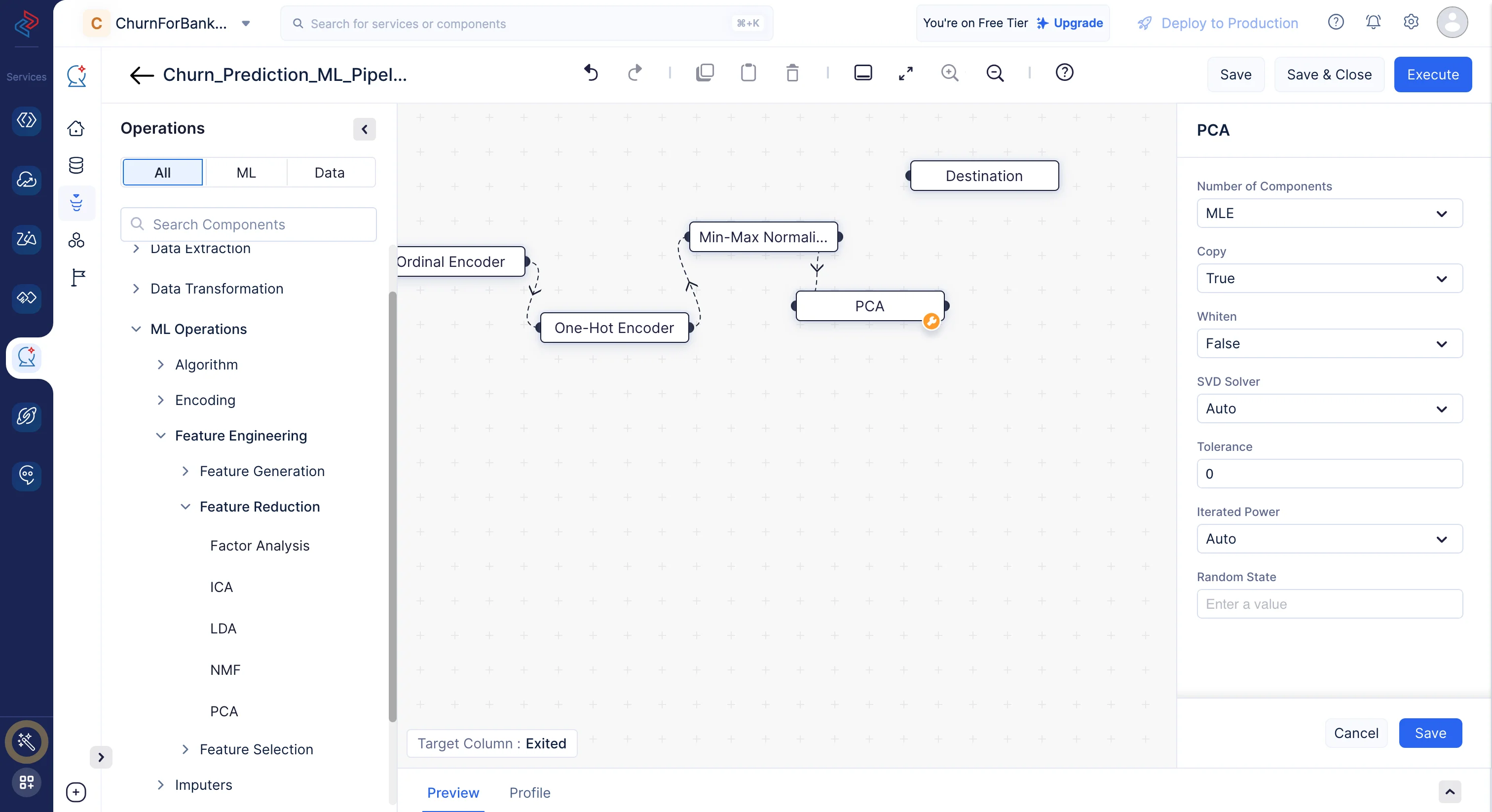
-
ML Algorithm:
The next step in ML pipeline building is selecting the appropriate algorithm for training the preprocessed data. Here we’ll use the Random-Forest Classification to train the data.
In order to make sure the model is optimized for our particular dataset, we may also adjust the tuning parameters; in our instance, we can just stick with the default settings. Select Random-Forest Classification node by navigating to ML operations, clicking ->Algorithms, and choosing ->Classification. When everything is configured, we may save the pipeline for further testing and deployment.

Once we drag-and-drop the algorithm node, its end node will be automatically connected to the destination node. Click Save to save the pipeline and execute the pipeline by clicking the Execute button at the top-right corner of the pipeline builder page.
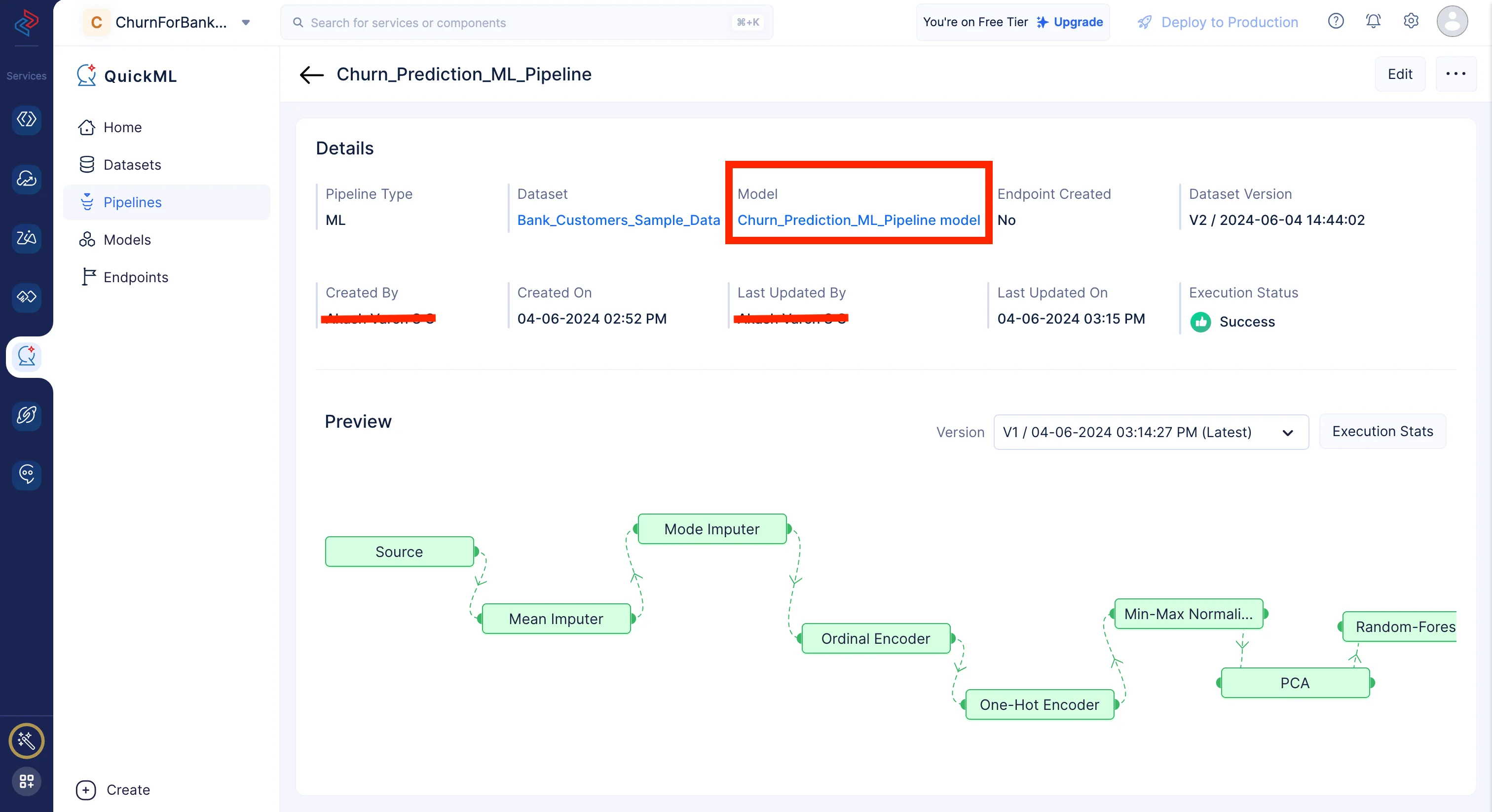
This will redirect you to the page below which shows the executed pipeline with execution status. We can clearly see here that the pipeline execution is successful.

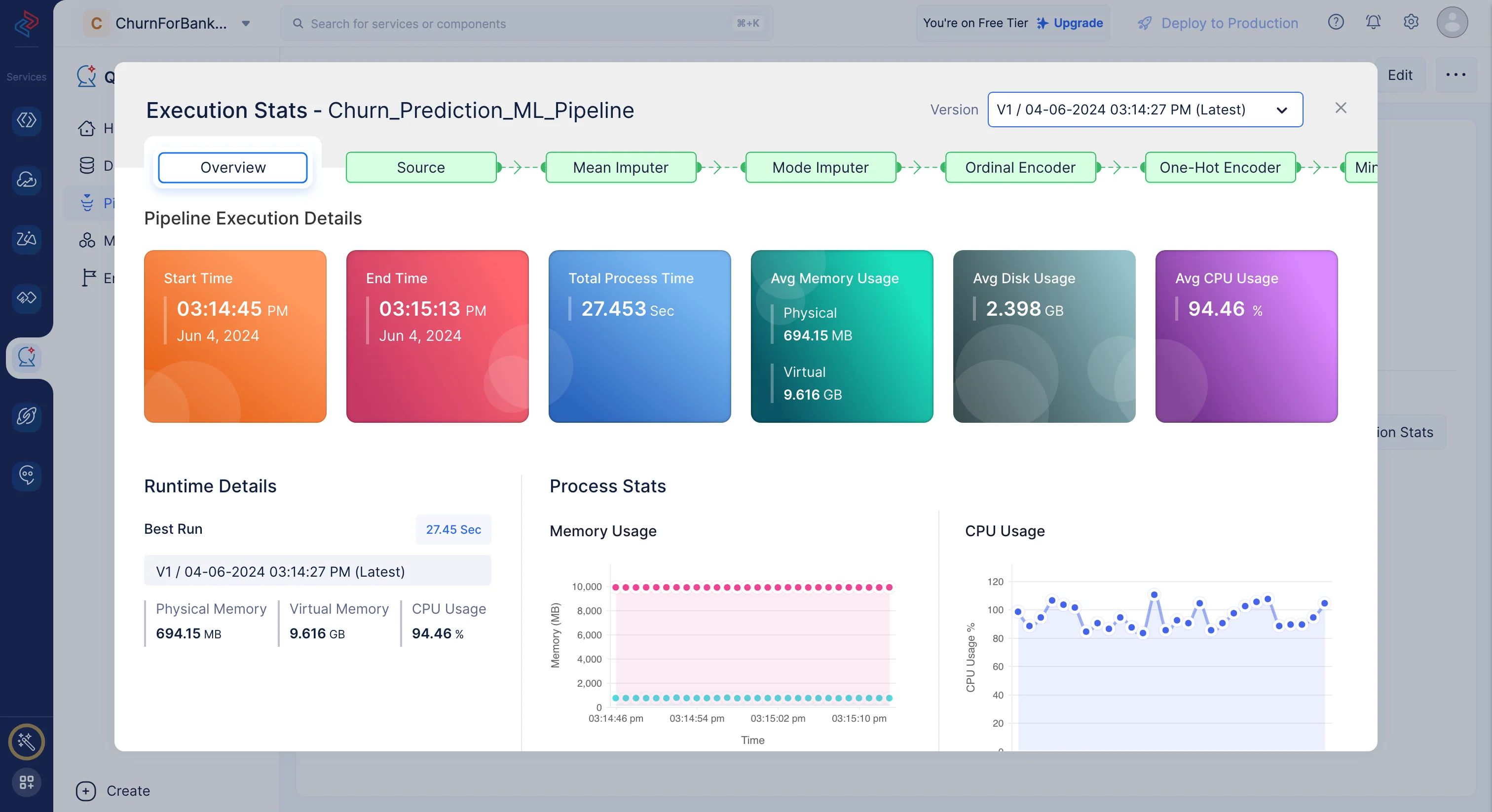
Click Execution Stats to view more compute details about each stage of the model execution in detail.
The prediction model is created and can be examined under the Model section(click on Churn_Prediction_ML_Pipeline Model) following the successful completion of the ML workflow.
This offers useful perceptions into the efficiency and performance of the model while making predictions based on the data.

Last Updated 2025-10-29 12:32:36 +0530 IST