ML パイプラインの作成
予測モデルを構築するために、前処理済みデータセットをML Pipeline Builder で使用します。ML Pipeline Builder の最初のステップでは、予測対象のカラムであるターゲットカラムを選択します。
ML パイプラインを作成するには、まず Pipelines セクションに移動し、Create Pipeline をクリックします。
表示されるポップアップで、パイプラインタイプとして Prediction を選択し、パイプライン名(ここでは Car Price Model を使用)とモデル名を指定します。次に、適切なデータセットとターゲットのカラム名を選択します。この場合、ターゲットは「money」という名前のカラムです。
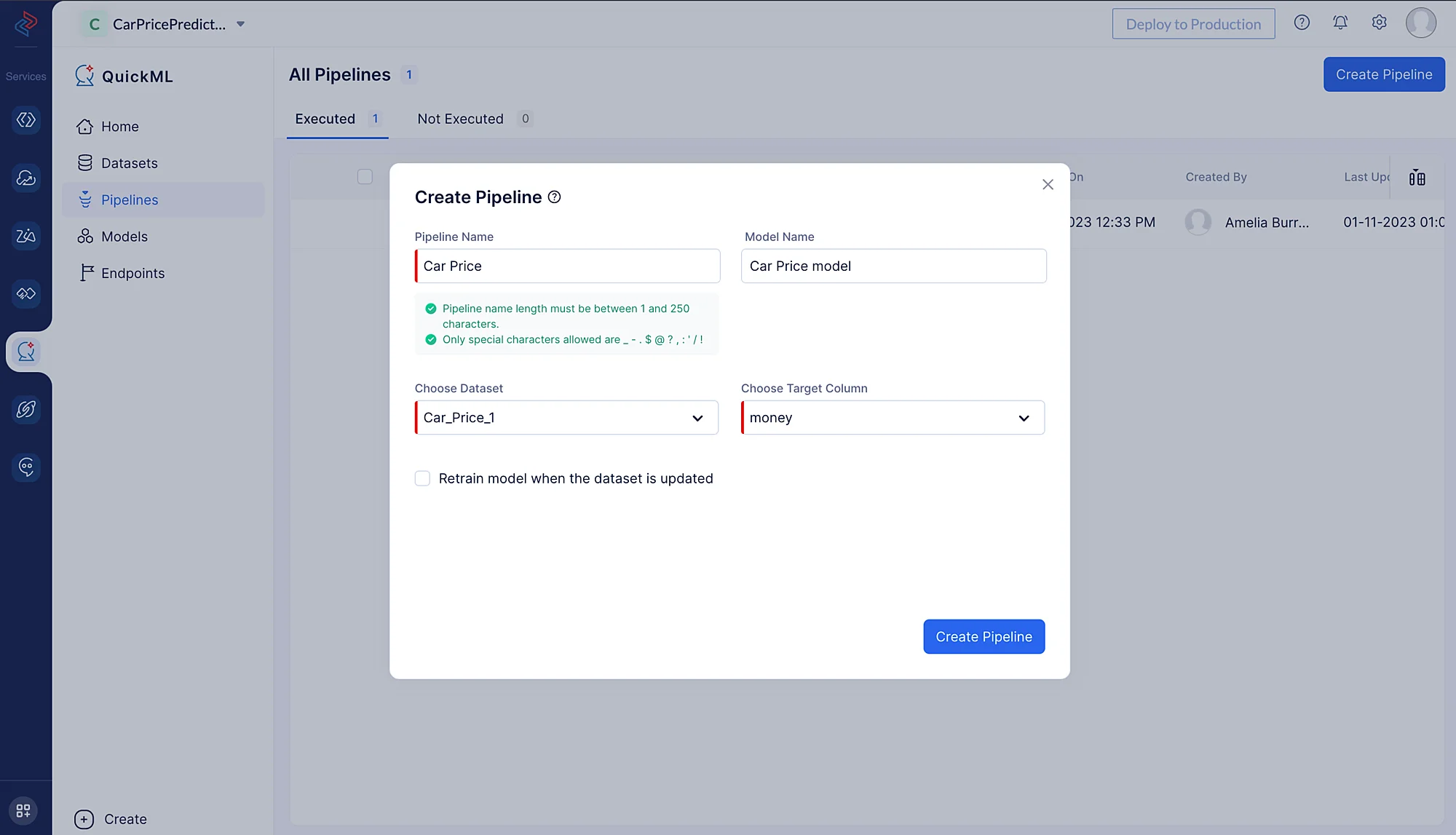
データセットを選択する際は、データパイプラインの構築で選択したソースデータセットを選択する必要があります。前処理済みデータはソースデータセットに反映されるためです。今回の場合、データの前処理とクリーニングにこのデータセットを選択したため、Car_Price_1 データセットをインポートします。
カテゴリカルカラムのエンコーディング
エンコーダは、カテゴリカルデータや非数値データを、機械学習アルゴリズムが効果的に処理できる数値形式に変換するために、さまざまなデータ前処理や機械学習タスクで使用されます。
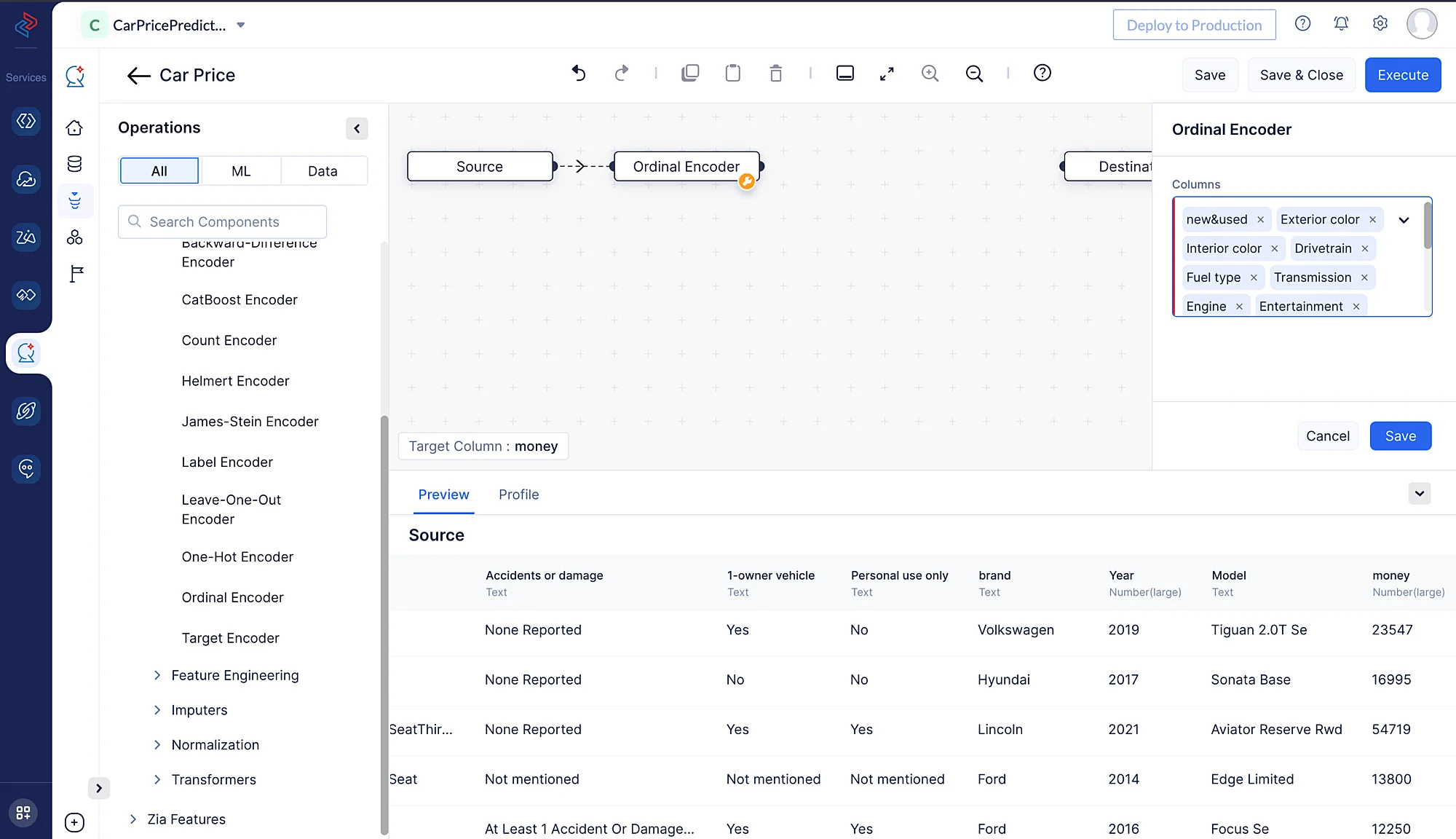
ここでは、すべてのカテゴリカル特徴量のエンコーディングにOrdinal Encoding を使用します。Ordinal Encoding は、カテゴリに順序に基づいた整数を割り当て、機械学習アルゴリズムがデータの順序性を捉えられるようにします。
QuickML の ML Operations > Encoding > Ordinal Encoder から Ordinal Encoder ノードを使用して、カテゴリカルカラムを数値カラムに変換できます。ここでは、モデルトレーニングのためにカラムの元の順序とデータを維持しながら、すべてのカテゴリカルカラムを数値形式に変換しています。
Imputer(欠損値補完)
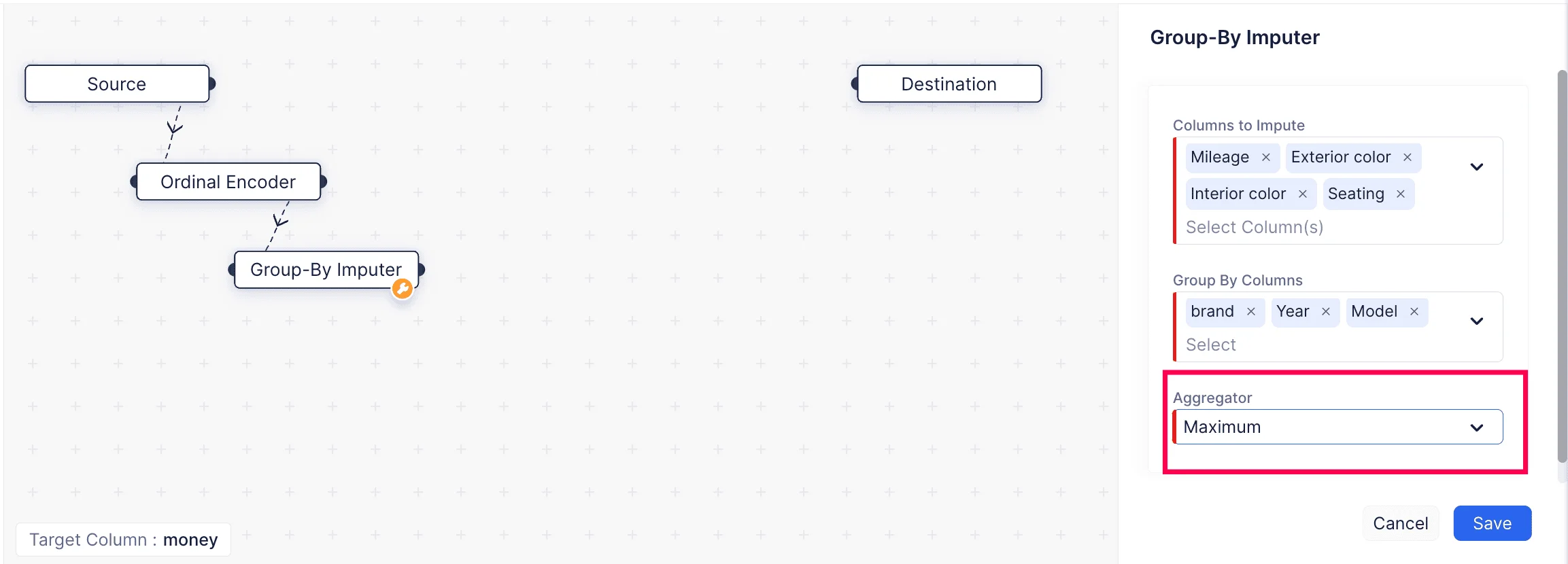
Imputer は、欠損データや不完全なデータを処理するために、データ分析、統計、機械学習などのさまざまな分野で使用されます。ここでは、ML operations > Imputers > Group-By Imputer からGroup By Imputer を使用して、データセット内の欠損値を補完します。
Group by Imputing とは、選択したカラムのグループ化やカテゴリ分けに基づいて欠損値を補充するデータ補完手法です。特定のカラムが別のカラム値の組み合わせを考慮して補完できる場合、この補完手法を使用できます。
ここでは、欠損値を持つカラムは「Mileage」、「Exterior Color」、「Interior Color」、および「Seating」です。欠損値を補充するために、「brand」、「Year」、「Model」のカラムでグループ化しています。
特徴量エンジニアリング
既存のデータから新しい特徴量(変数)を作成する行為をFeature Generation(特徴量生成)と呼びます。これらの追加特徴量は、機械学習モデルの性能向上や、基礎となるデータからより深い洞察を得るために活用できます。特徴量生成はデータ前処理パイプラインの重要な部分であり、生データをモデリングに適した形式に変換し、有用な情報を抽出するのに役立ちます。
ここでは、「Autolearn」特徴量生成手法を使用して特徴量を生成しています。この手法は、既存のカラムから特徴量を生成します。ML Operations > Feature Engineering > Feature Generation > Autolearn からこのノードを選択できます。
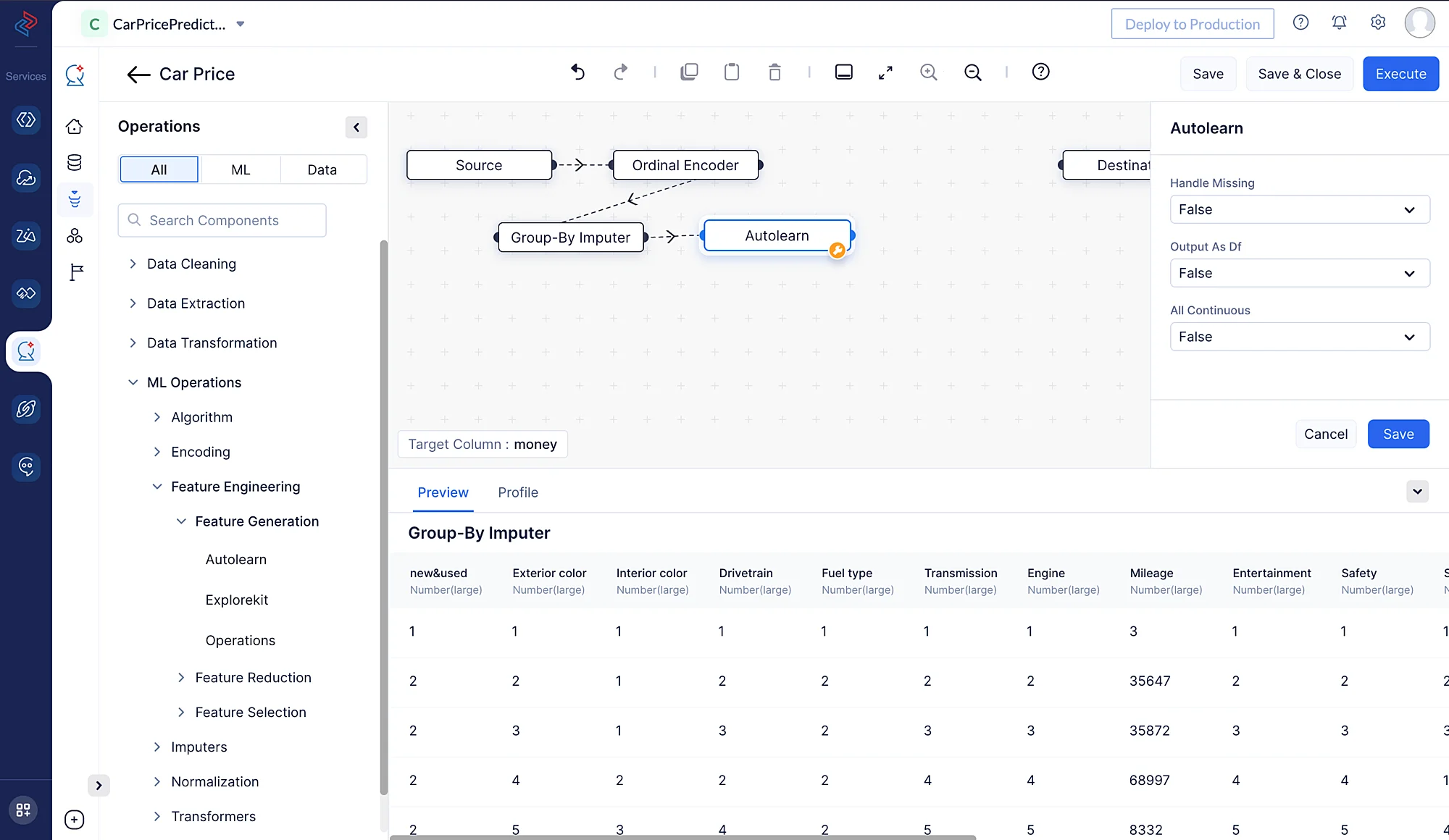
アルゴリズムの選択とモデルフィッティング
ML パイプライン構築の次のステップは、前処理済みデータをトレーニングするための適切なアルゴリズムの選択です。ここでは、データのトレーニングにLightGBM Regressor Algorithm を使用します。
LightGBM(Light Gradient Boosting Machine)は、回帰問題を含むさまざまな機械学習タスクに使用される人気の勾配ブースティングフレームワークです。トレーニングの効率性と速度に優れており、大規模データセットでよく選ばれています。
QuickML の ML Pipeline Builder で ML Operations > Algorithm > Regression > LGBM Regression から関連する LightGBM Regression ノードをドラッグ&ドロップすることで、LightGBM 回帰手法をすばやく構築できます。
特定のデータセットに最適化されたモデルにするため、チューニングパラメータの調整も可能です。今回の場合は、デフォルト設定のまま使用します。すべての設定が完了したら、パイプラインを保存して、さらなるテストとデプロイに備えます。
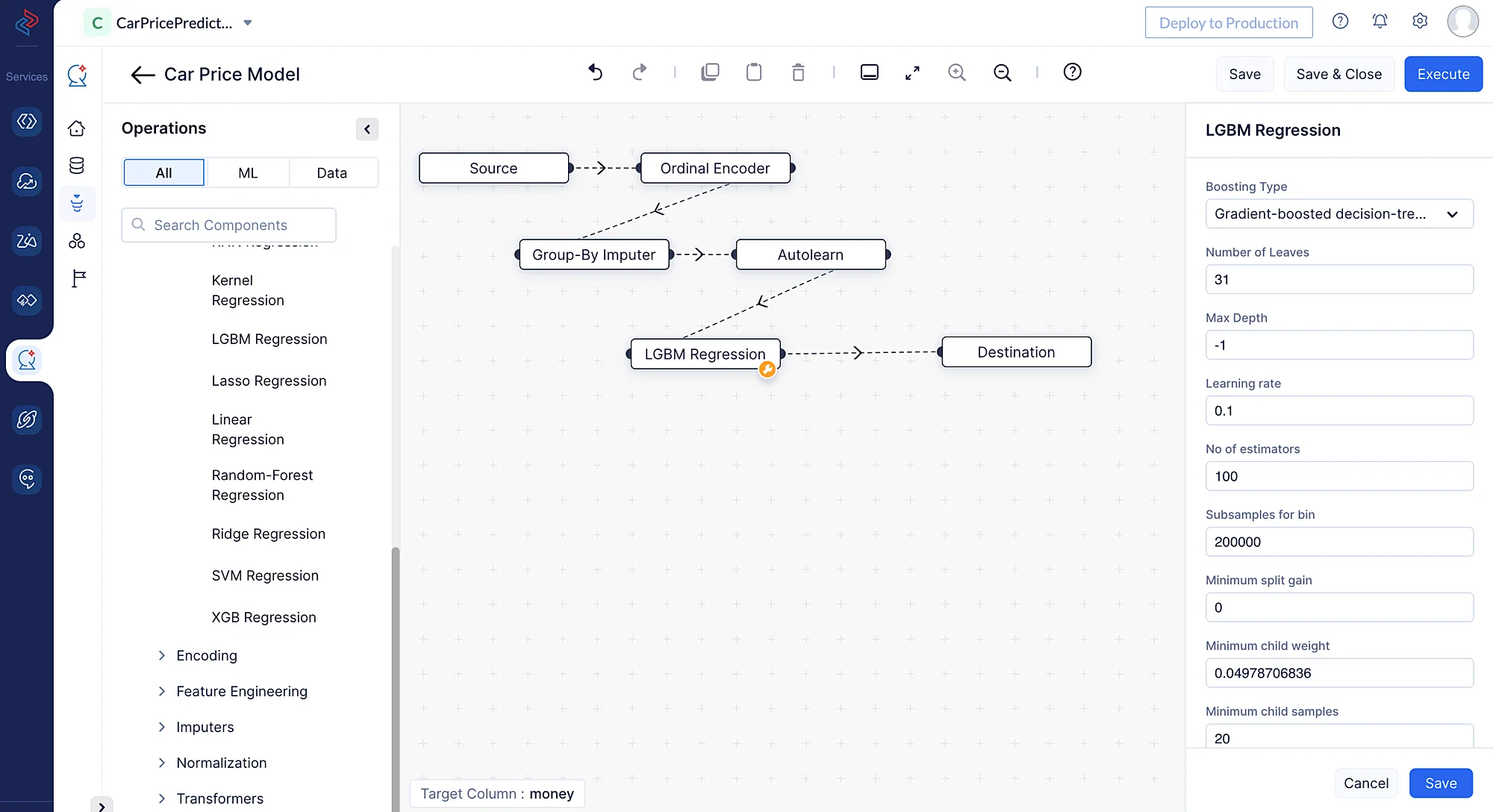
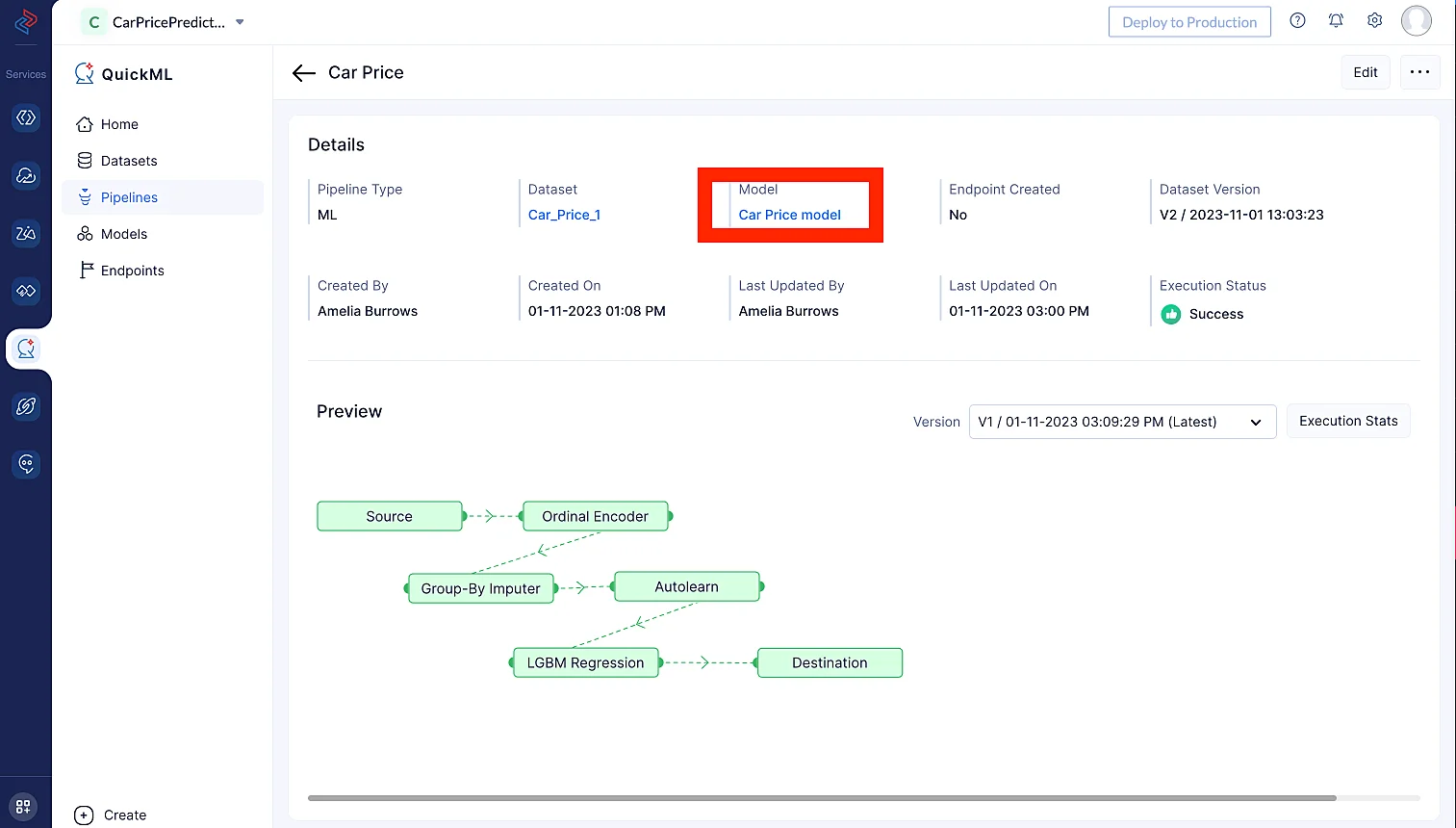
アルゴリズムノードをドラッグ&ドロップすると、その終端ノードが自動的に Destination ノードに接続されます。パイプラインを保存後、パイプラインページの右上にある Execute をクリックしてパイプラインを実行できます。
execution ページにリダイレクトされ、パイプラインの実行状況を確認できます。
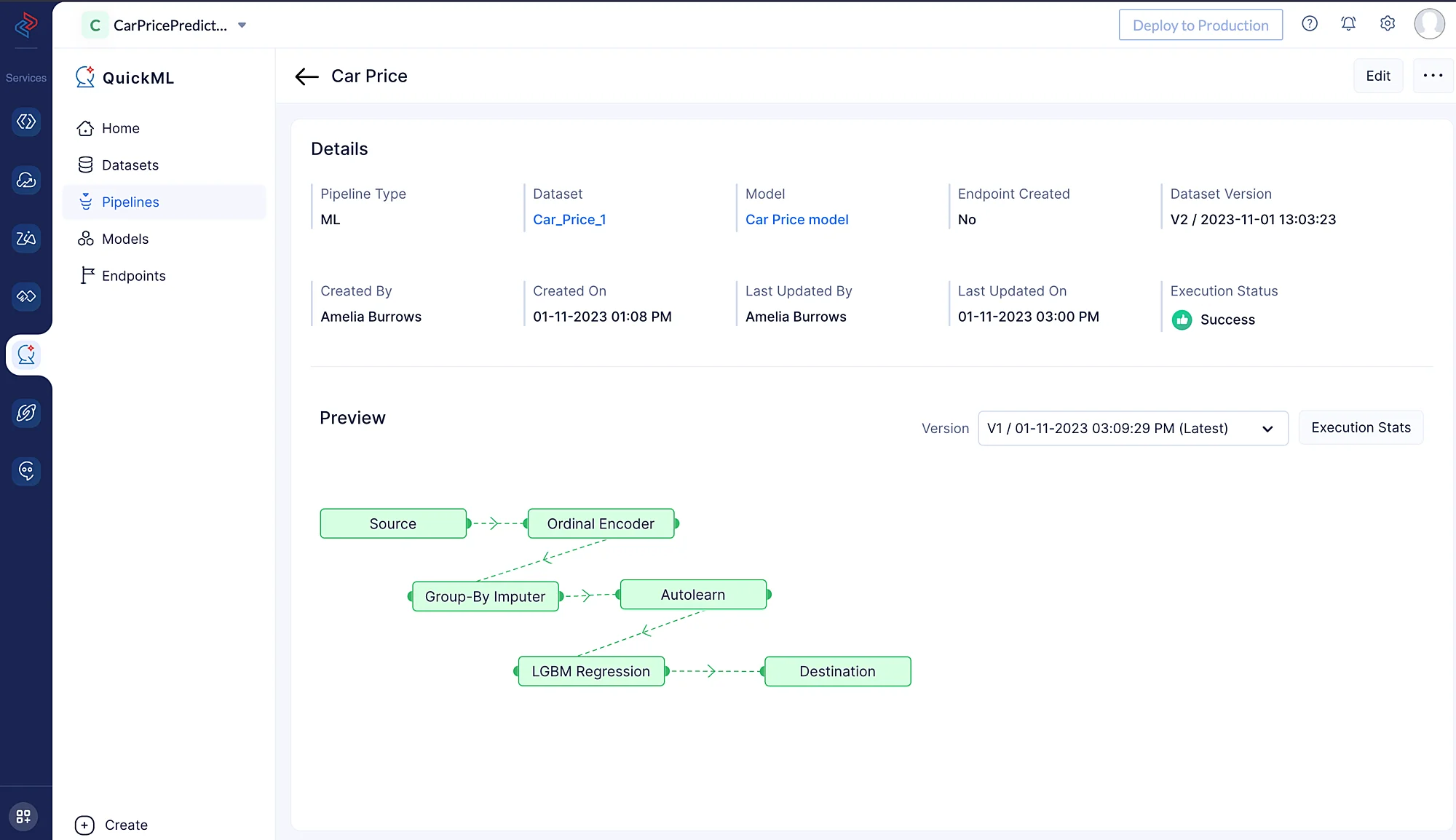
Execution Stats をクリックして、ML パイプラインの各実行ステージの詳細を確認します。
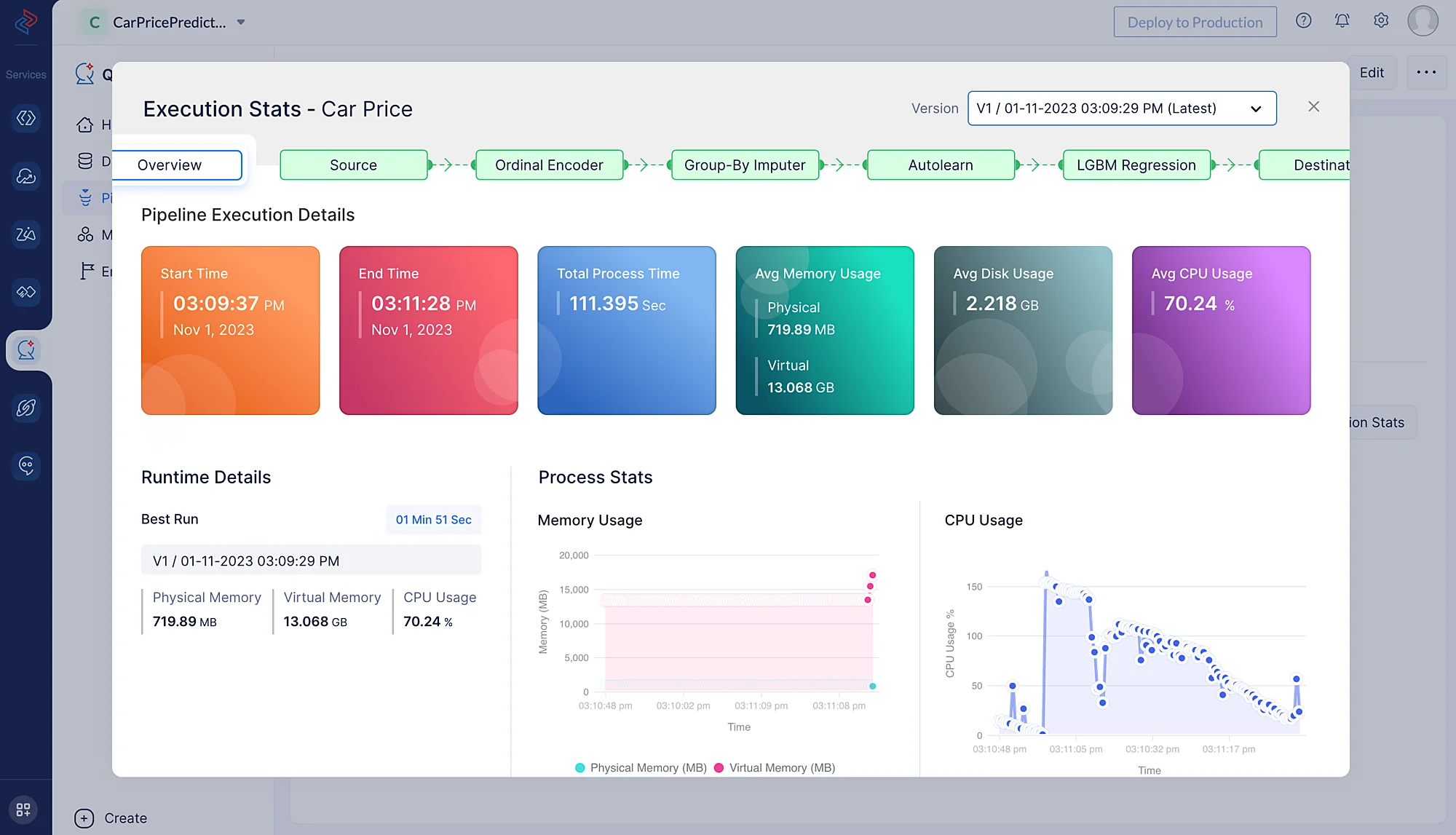
ML ワークフローの実行が正常に完了すると、予測モデルが作成され、Model セクション(Car Price Model model をクリック)で確認できます。
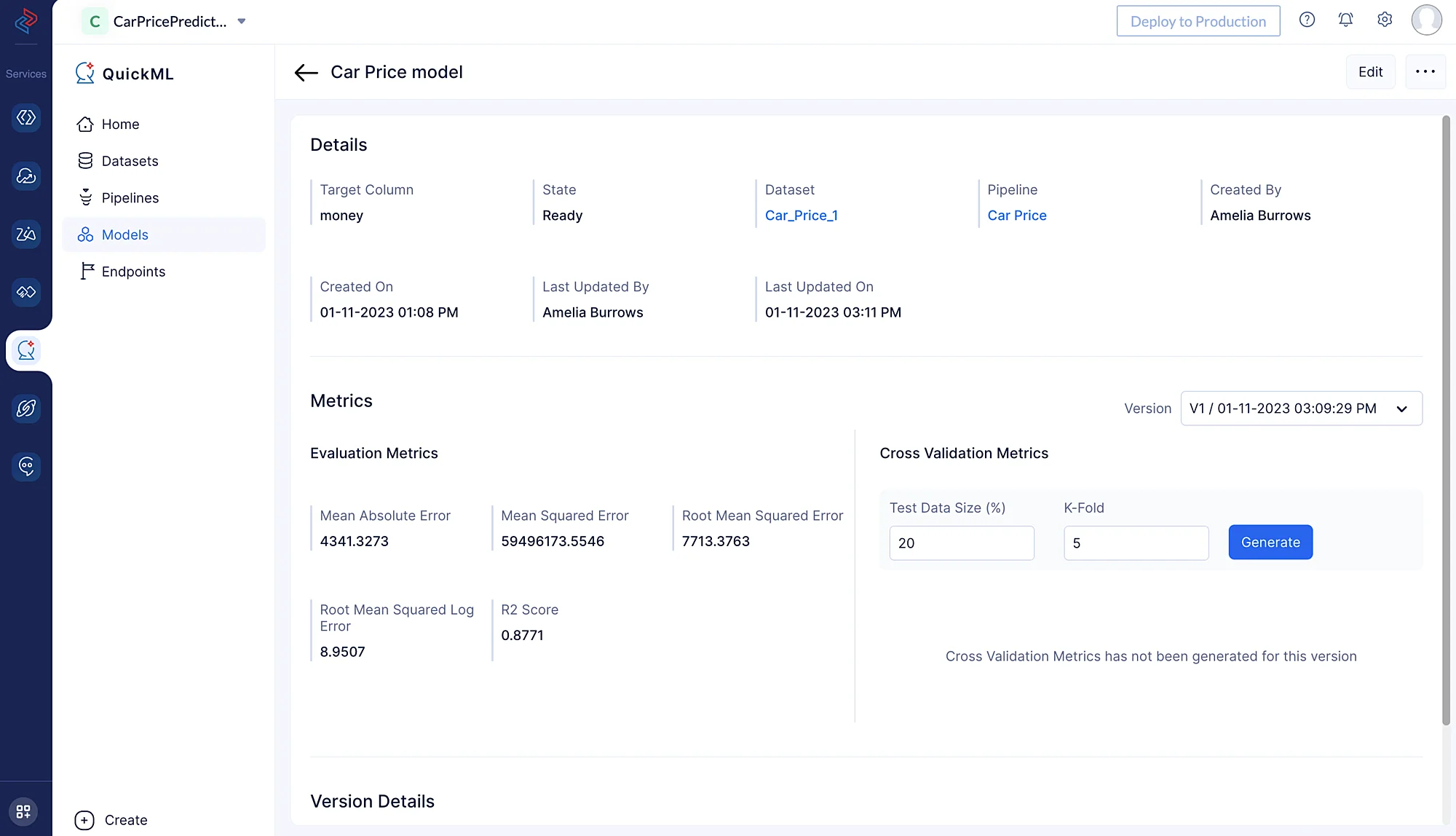
以下のメトリクスは、データに基づいた予測を行う際のモデルの効率性とパフォーマンスに関する有用な洞察を提供します。
最終更新日 2026-03-05 11:43:24 +0530 IST