Once the dataset is uploaded proceed with the below steps.
- Create a pipeline using the Create Pipeline button in details Page.
- We will be redirected into Pipeline builder page to preprocess the dataset.
- Drag and drop the operation node and configure.
- Make connection between nodes to execute the pipeline.
Data Preprocessing:
Data Preprocessing is the process of preparing data for analysis by removing or modifying the incorrect data. Data Preprocessing involves a lot of muscle work. In fact, 45% of data scientist’s time is spent on cleaning data rather than machine learning.
But with the help of QuickML, We can Preprocess data using simple drag and drop tools in Data Pipeline Builder. Profile and preview of the data will also available in Pipeline Builder to analyse and preprocess data.
Data Preprocessing creation with and without QuickML:
1. Combining the Tables:
With Python: Read and combine both given datasets into a single dataset using Python code.
copy
// create a spark session
spark = pyspark.sql.SparkSession.builder.appName("quickml").master("local[*]").getOrCreate()
clinic_A_Report_path = "/path_to_file/Cancer_detection_A.orc"
clinic_B_Report_path = "/path_to_file/Cancer_detection_B.orc"
// read orc data using pyspark and convert it to pandas DataFrame
clinic_A_Report = spark.read.orc(clinic_A_Report_path).toPandas()
clinic_B_Report = spark.read.orc(clinic_B_Report_path).toPandas()
// Combining Two Datasets
union_dataset = pd.concat(
[clinic_A_Report, clinic_B_Report],
axis=0,
ignore_index=True
)
With QuickML: Add another dataset Cancer_detection_B with the help of Add Datasetnode (Note: Make sure to upload the dataset you want to add before proceeding with this step). Combine these two provided datasets, Cancer_detection_A and Cancer_detection_B, into a single dataset using the Unionnode in QuickML’s drag and drop interface within the Pipeline Builder. Make sure to remove duplicate records during the process.
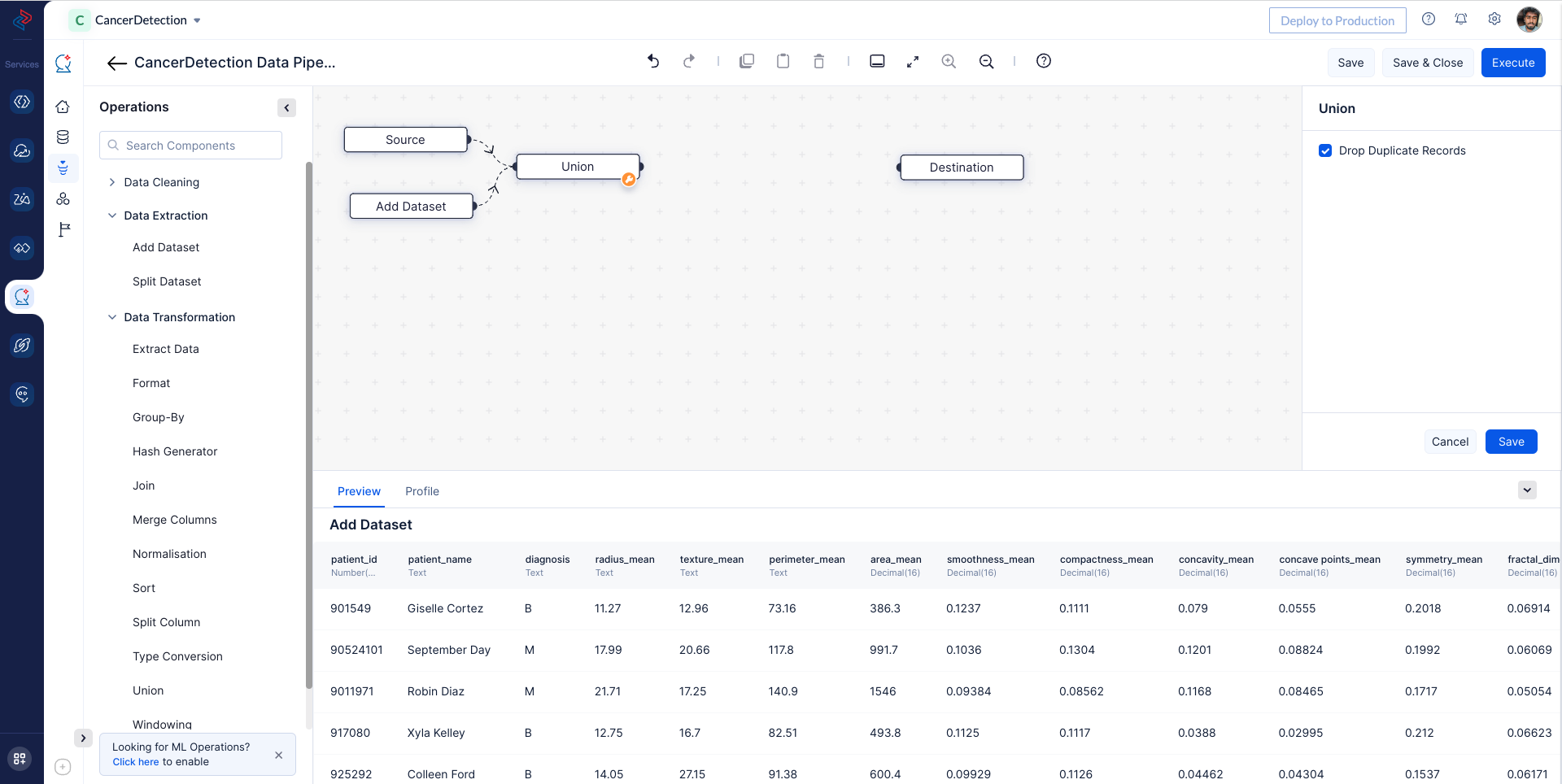
2. Selecting Required Fields for Model Training:
With Python: Use Python code to select the required fields from the dataset to train the model.
copy
columns_to_drop = ["patient_id", "patient_name", "_c33"]
// drop the above list of columns
union_dataset = union_dataset.drop(columns=columns_to_drop)
union_dataset.head(5)
With QuickML: Utilize QuickML to easily select the required fields from the dataset for model training using select-drop node, in our case the columns we don’t need for our model training are “patient_id”, “patient_name” and “_c33” in the given datasets.
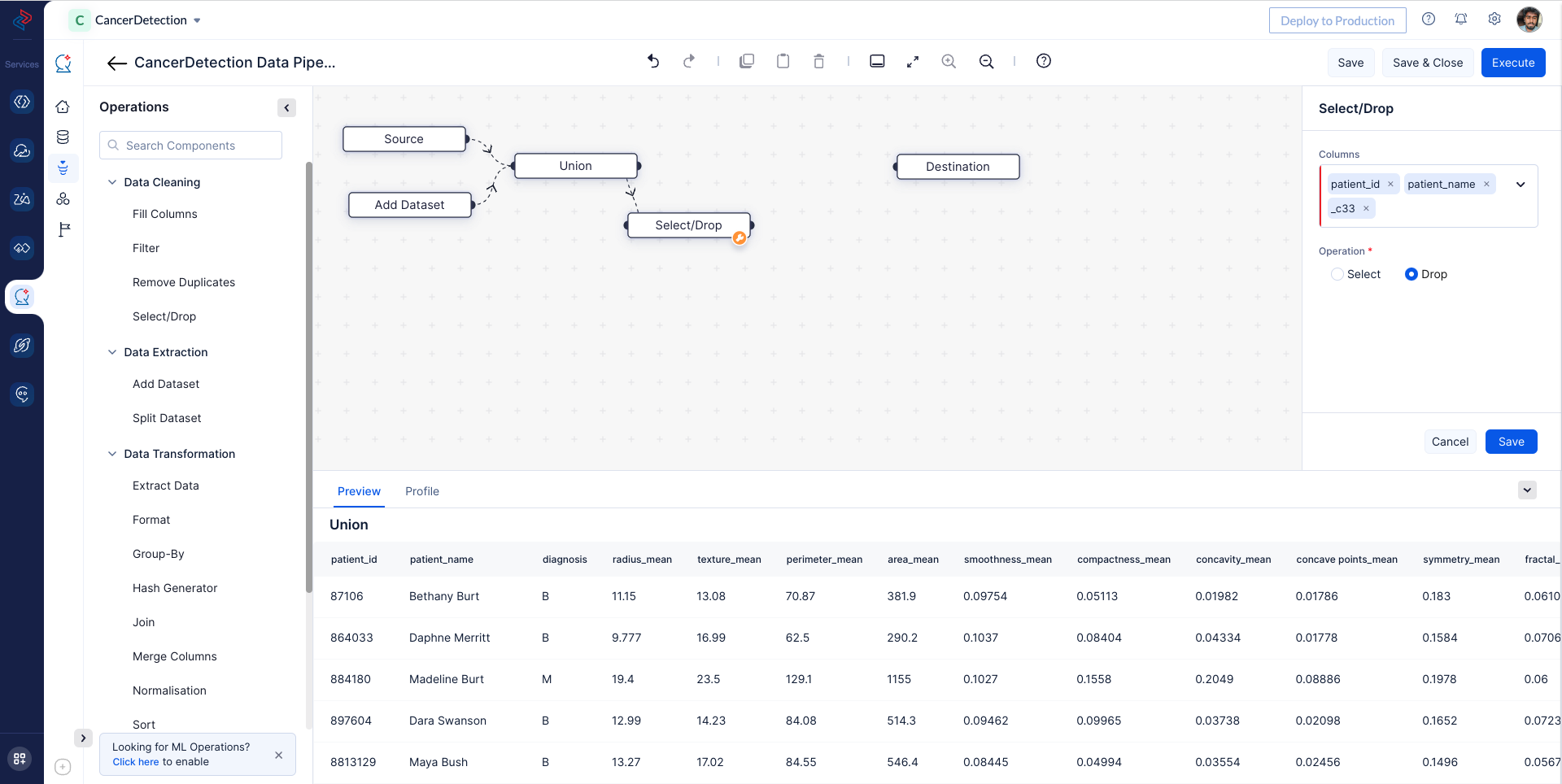
3. Converting Number in String Columns to Decimal Type:
With Python: Convert numerical values stored as strings to decimal type using Python code.
copy
string_columns = union_dataset.select_dtypes(include=["object", "string"]).columns
columns_to_type_convert = [col for col in string_columns if col != 'diagnosis']
for column in columns_to_type_convert:
union_dataset[column] = union_dataset[column].astype(float)
With QuickML: In QuickML, you can easily identify mismatched column types and numeric values stored as strings using the preview tab. To convert columns with numeric values stored as strings into decimal type in the Pipeline Builder we want to use Type-Conversion node, in our case we are changing the data type of “texture_mean” column into numerics.
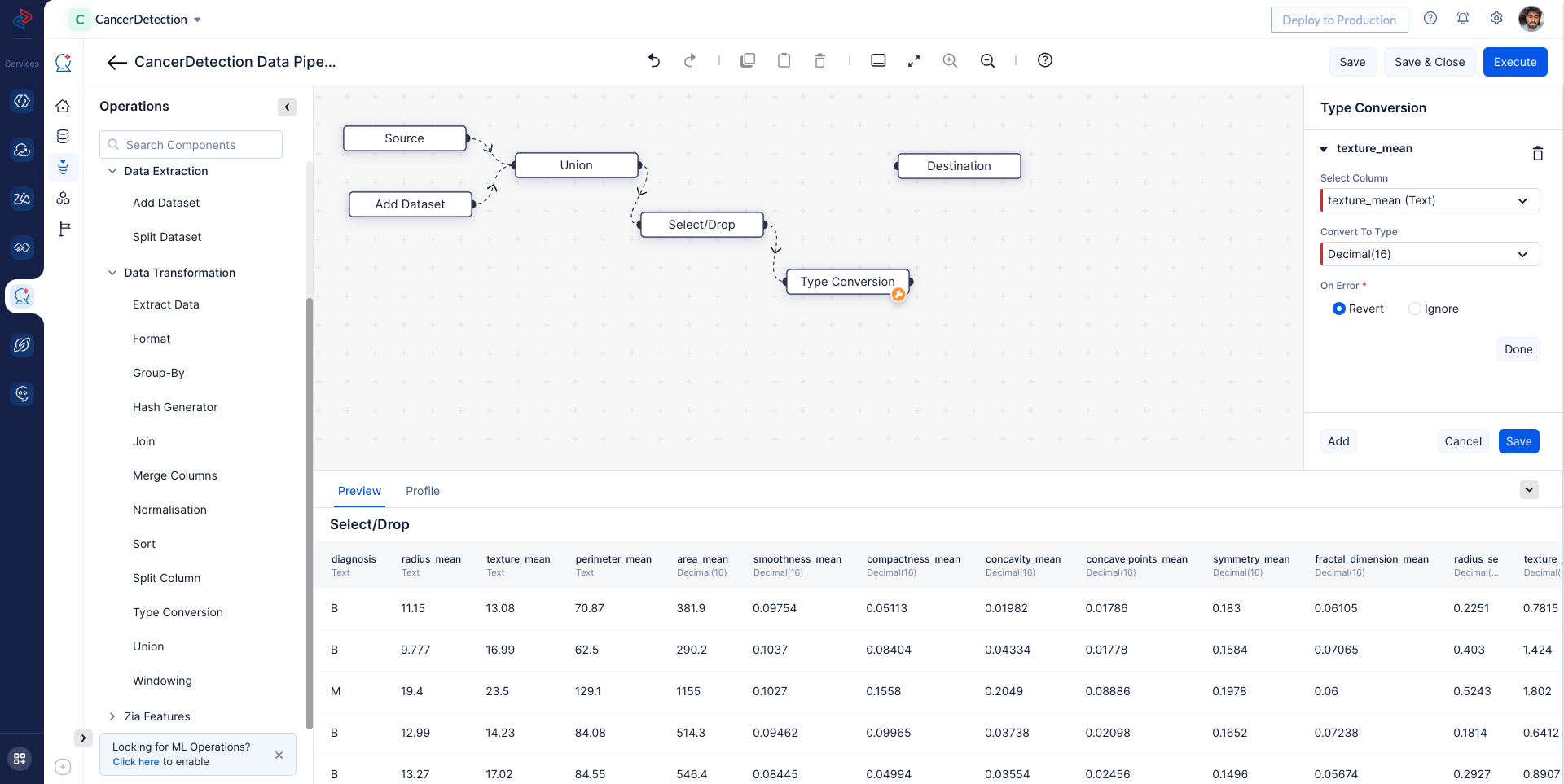
4. Handling Missing Values in the Data:
With Python: Implement Python code to find and fill missing values in the dataset.
copy
// find the count of columns with null values
isnull_count = union_dataset.isnull().sum()
// extract the column names of the columns with null values
columns_with_null_values = list(isnull_count[isnull_count > 0].index)
// fill the missing data in the column
for column in columns_with_null_values:
# find the mean of the column
column_mean = union_dataset[column].mean()
union_dataset[column] = union_dataset[column].fillna(column_mean)
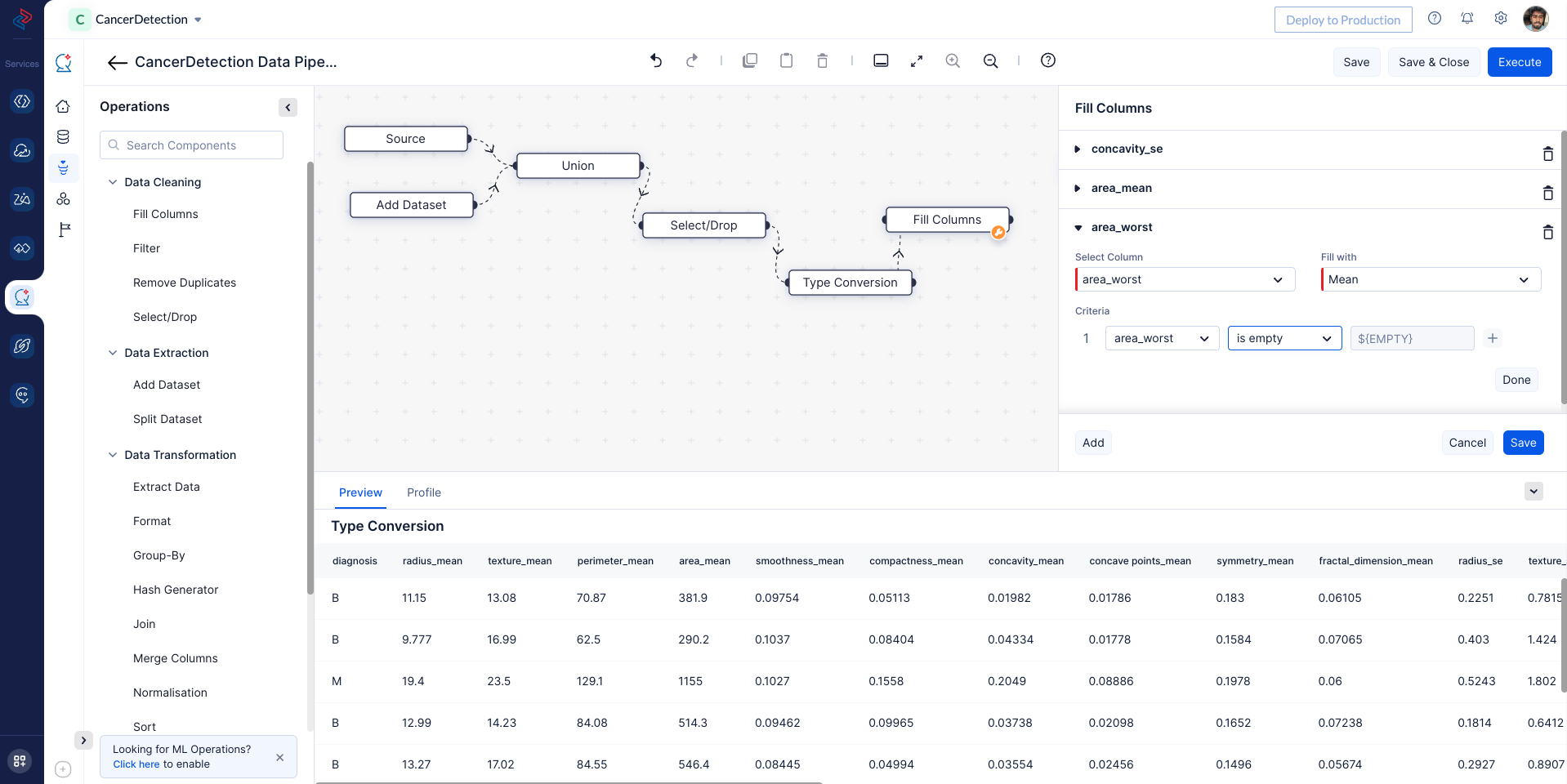
With QuickML: By using profiling in QuickML, you can easily identify columns with missing values and handle them efficiently in the data preprocessing pipeline with Fill-column node, in our dataset we are filling the “concavity_se”, “area_mean” and “area_worst” column’s empty cells with the mean value of that particular column.
Once all the node are connected, Saveand Execute the pipeline.
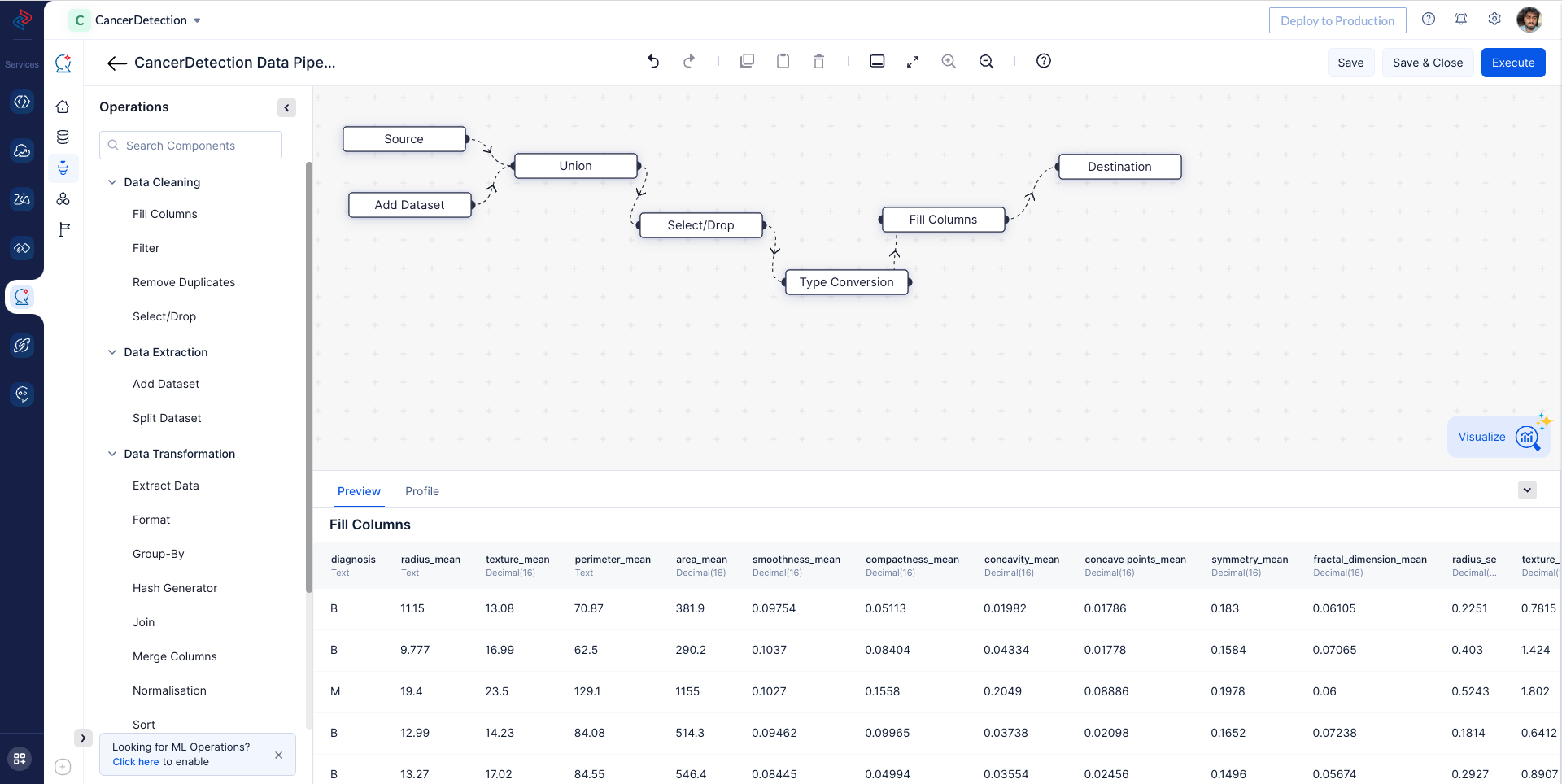
Here you can see the executed Pipeline with execution status.
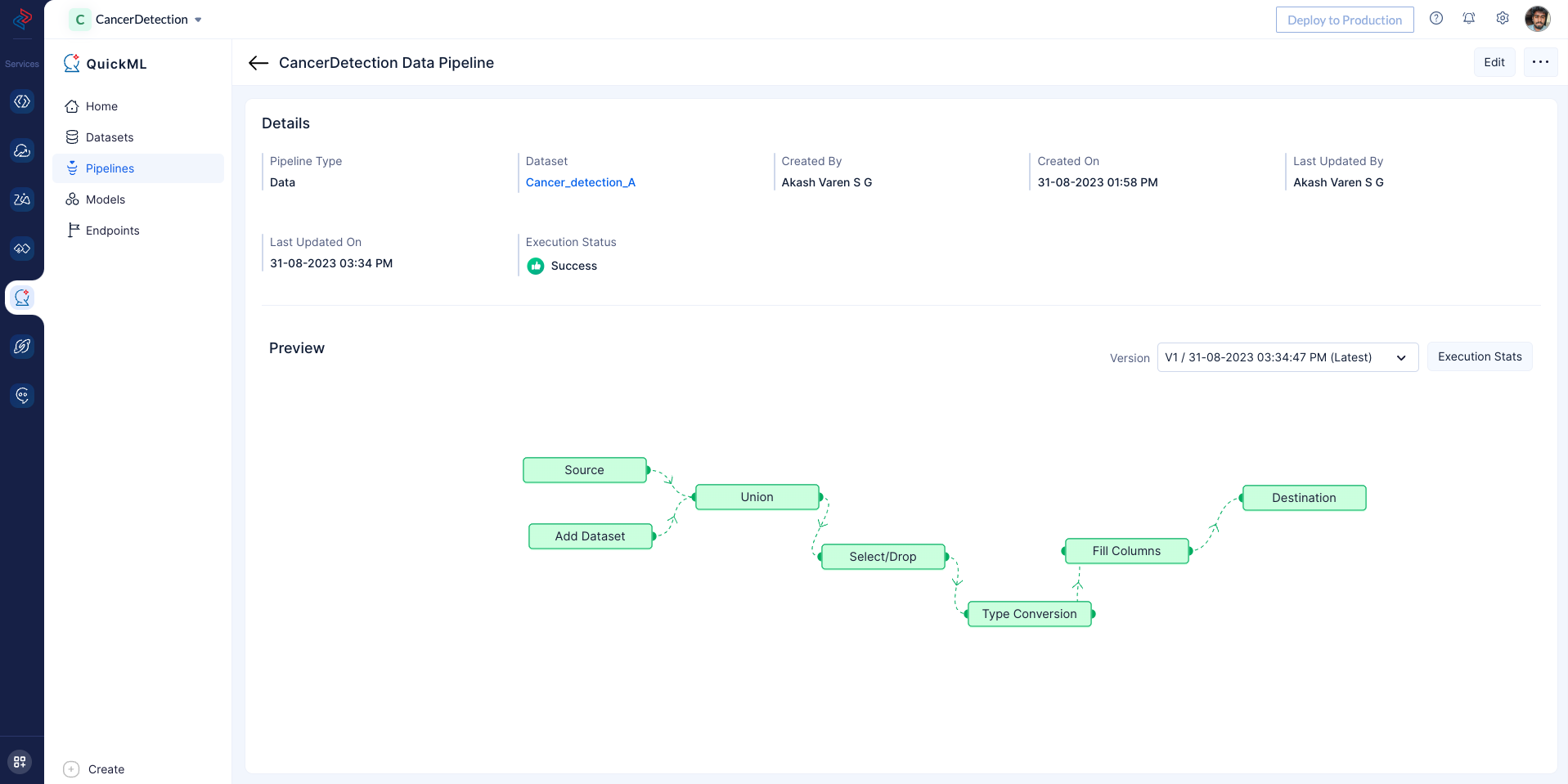
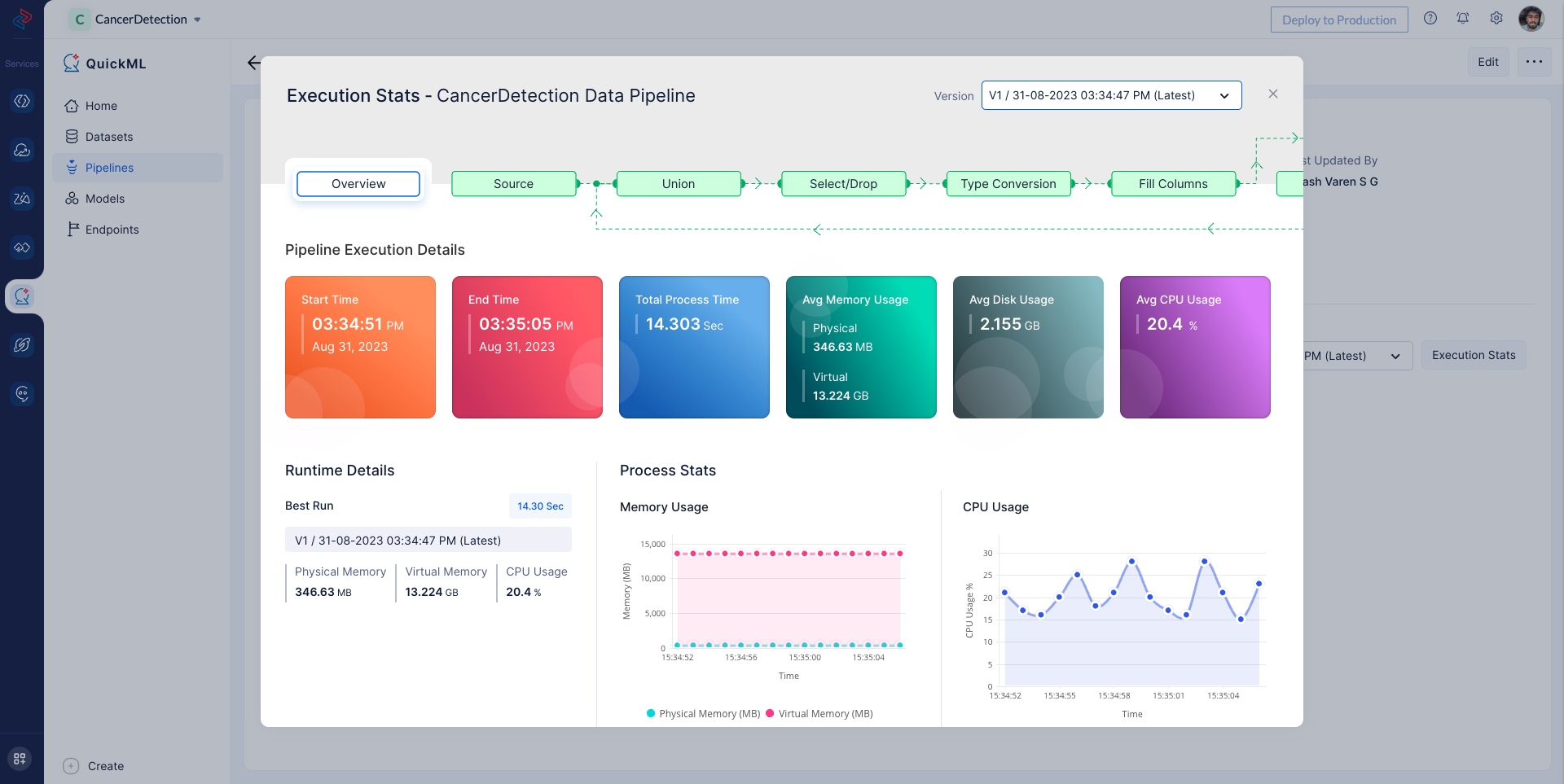
On Successful pipeline execution, You can view execution information for more details about the preprocess execution as shown below by clicking on Execution Stats.
In this section, we will explore how to perform data preprocessing tasks using both Python code and QuickML, providing you with versatile and efficient methods for preparing your data for machine learning model development. This data pipeline can be reused to create multiple ML experiments for our usecase going forward.
Last Updated 2023-09-04 20:02:30 +0530 +0530