データパイプラインの作成
データセットのアップロードが完了したので、次にデータセットを使用してデータパイプラインを作成します。
-
左側メニューのDatasetsコンポーネントに移動します。データパイプラインを作成するには2つの方法があります:
- データセットをクリックし、ページ右上のCreate Pipelineをクリックします。
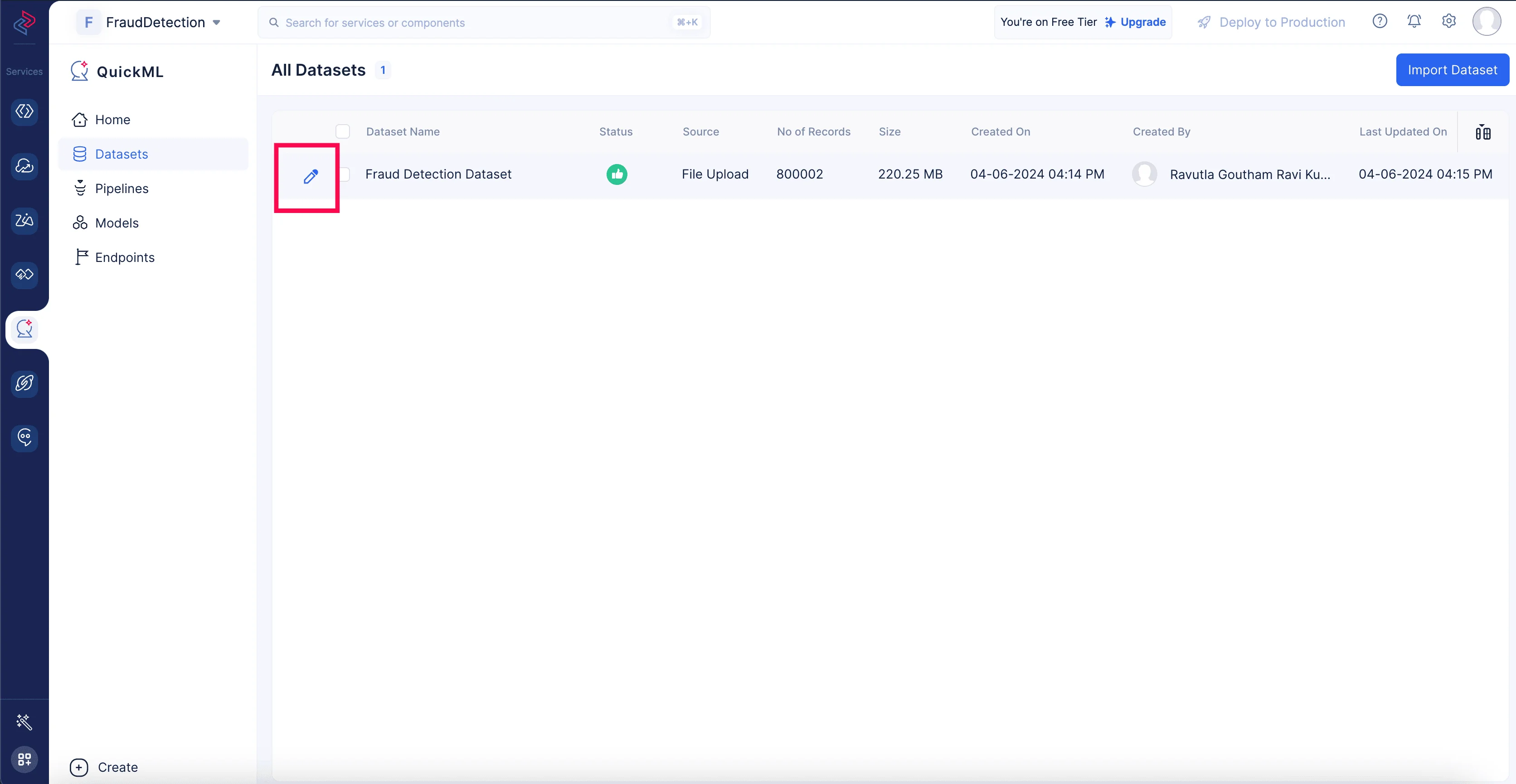
- 下の画像に示すように、データセット名の左側にあるペンアイコンをクリックします。
- データセットをクリックし、ページ右上のCreate Pipelineをクリックします。
-
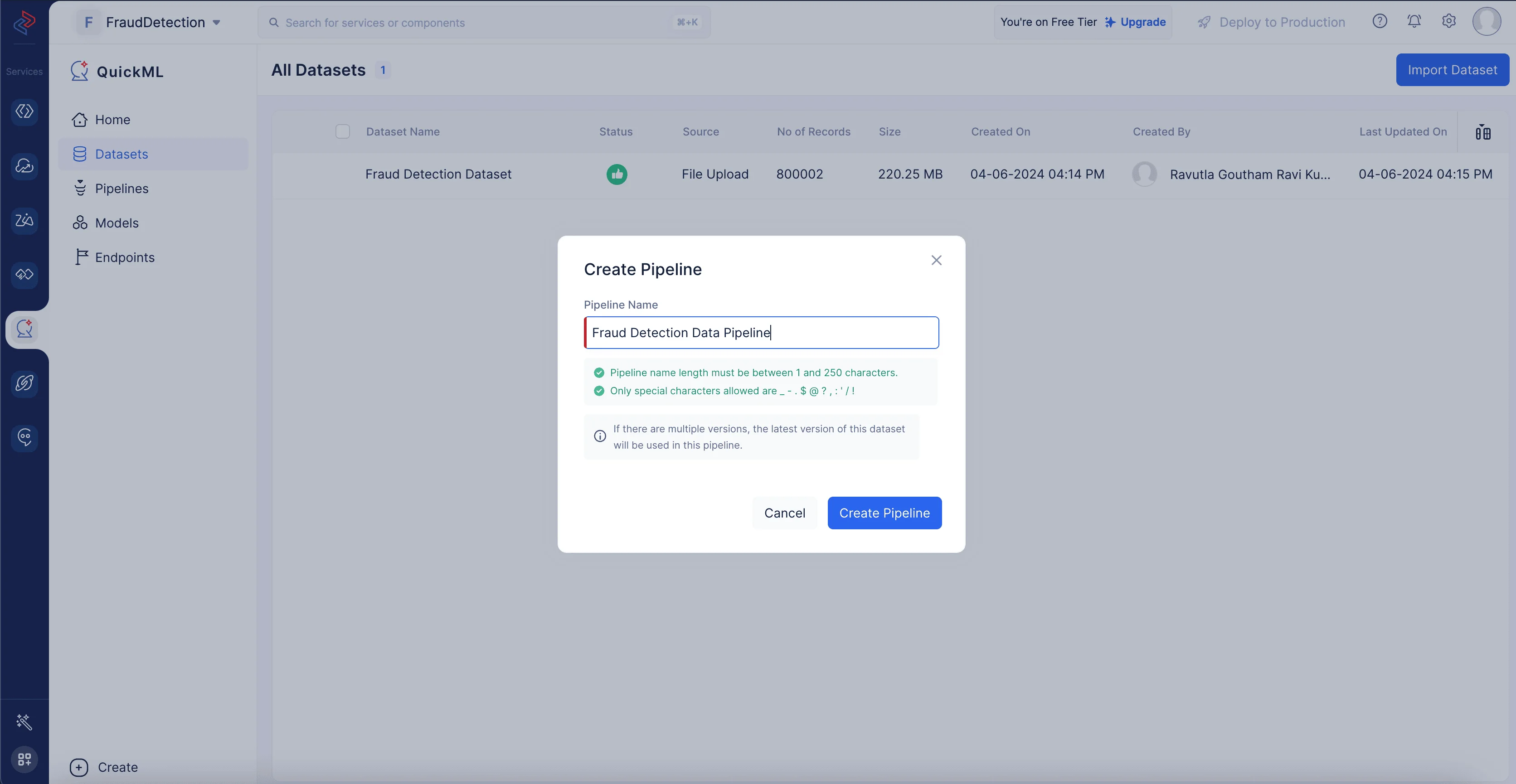
パイプライン名を「Fraud Detection Data Pipeline」と入力し、Create Pipelineをクリックします。
以下のスクリーンショットのように、パイプラインビルダーインターフェースが開きます。
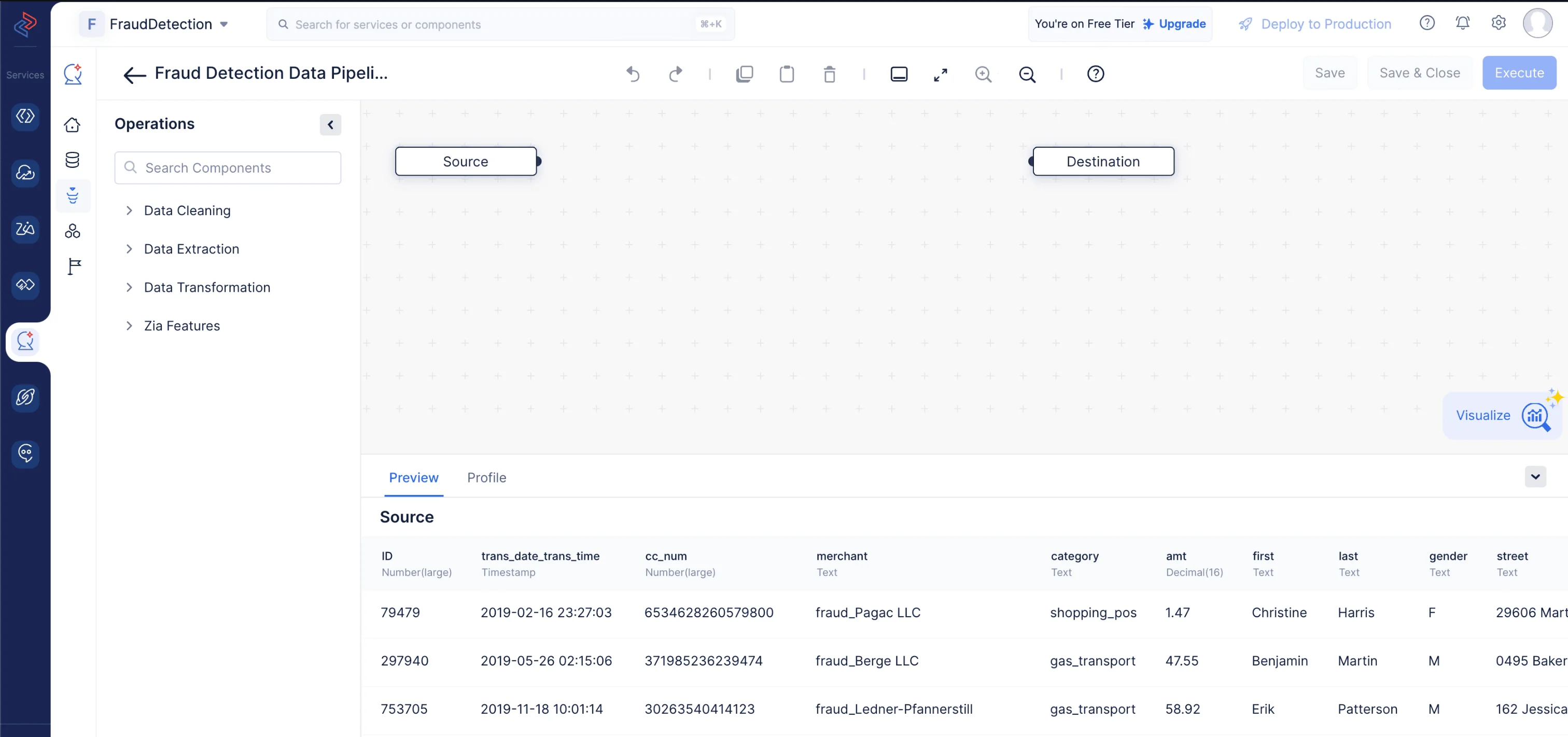
データセットのクリーニング、精製、変換を行い、データパイプラインを実行するために、以下の一連のデータ前処理操作を実施します。各操作には、パイプラインを構成するための個別のデータノードが使用されます。
QuickMLによるデータ前処理
-
カラムの選択/削除
データセットからカラムを選択または削除することは、データ分析や機械学習における一般的なデータ前処理のステップです。カラムの選択または削除は、分析やモデリングタスクの具体的な目的と要件に応じて判断します。 このデータセットからモデルトレーニングに不要なカラムは、「ID」、「trans_date_trans_time」、「cc_num」、「Merchant」、「First」、「Last」、「Street」、「City」、「Zip」、「Lat」、「Long」、「job」、「dob」、「Trans_num」、「Unix_Time」、「merch_lat」、「merch_long」です。QuickMLを使用すると、Data CleaningコンポーネントのSelect/Dropノードを使用して、モデルトレーニングに必要なフィールドをデータセットからすばやく選択できます。

-
データのフィルタリング
データセットのフィルタリングとは、特定の基準や条件を満たすDataFrameの行のサブセットを選択することを指します。ここでは、Data CleaningセッションのFilterノードを使用して、「state」カラムの値が空でないものをフィルタリングします。
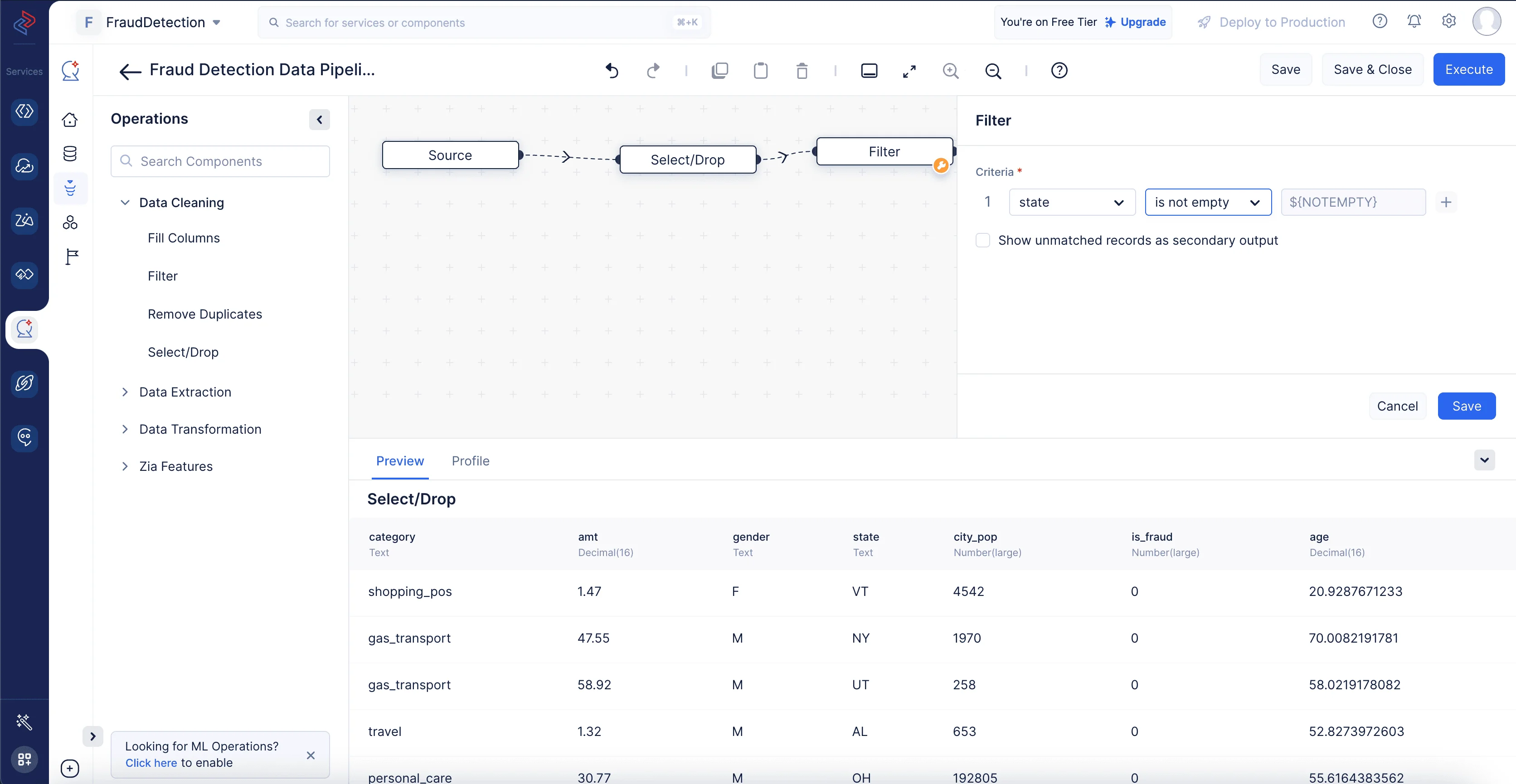
-
保存と実行
次に、Filter ノードをDestinationノードに接続します。すべてのノードが接続されたら、Saveボタンをクリックしてパイプラインを保存します。次に、Executeボタンをクリックしてパイプラインを実行します。

以下のページにリダイレクトされ、実行ステータス付きの実行済みパイプラインが表示されます。パイプラインの実行が成功したことが確認できます。
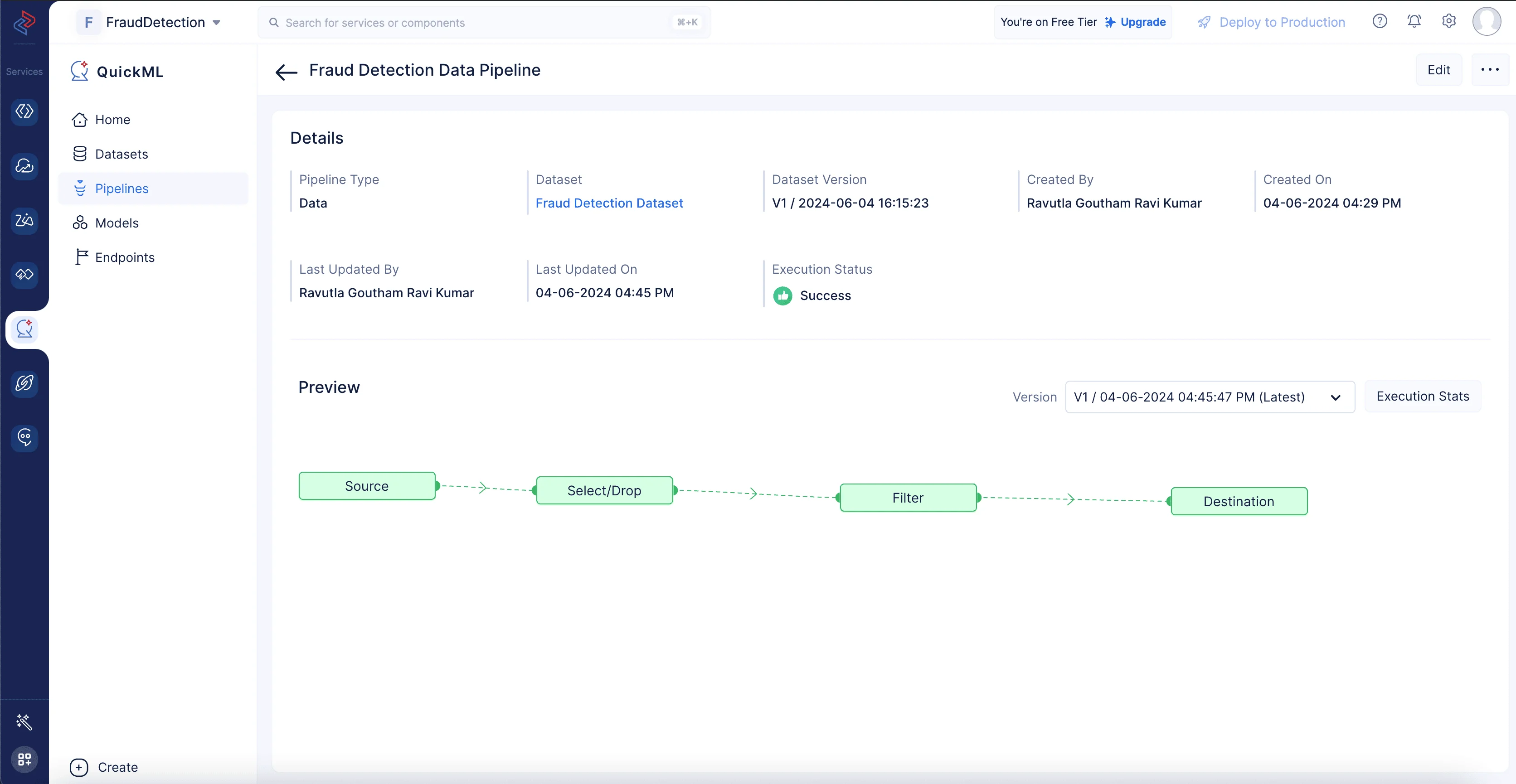
Execution Statsをクリックすると、以下のようにコンピュート使用量の詳細を確認できます。
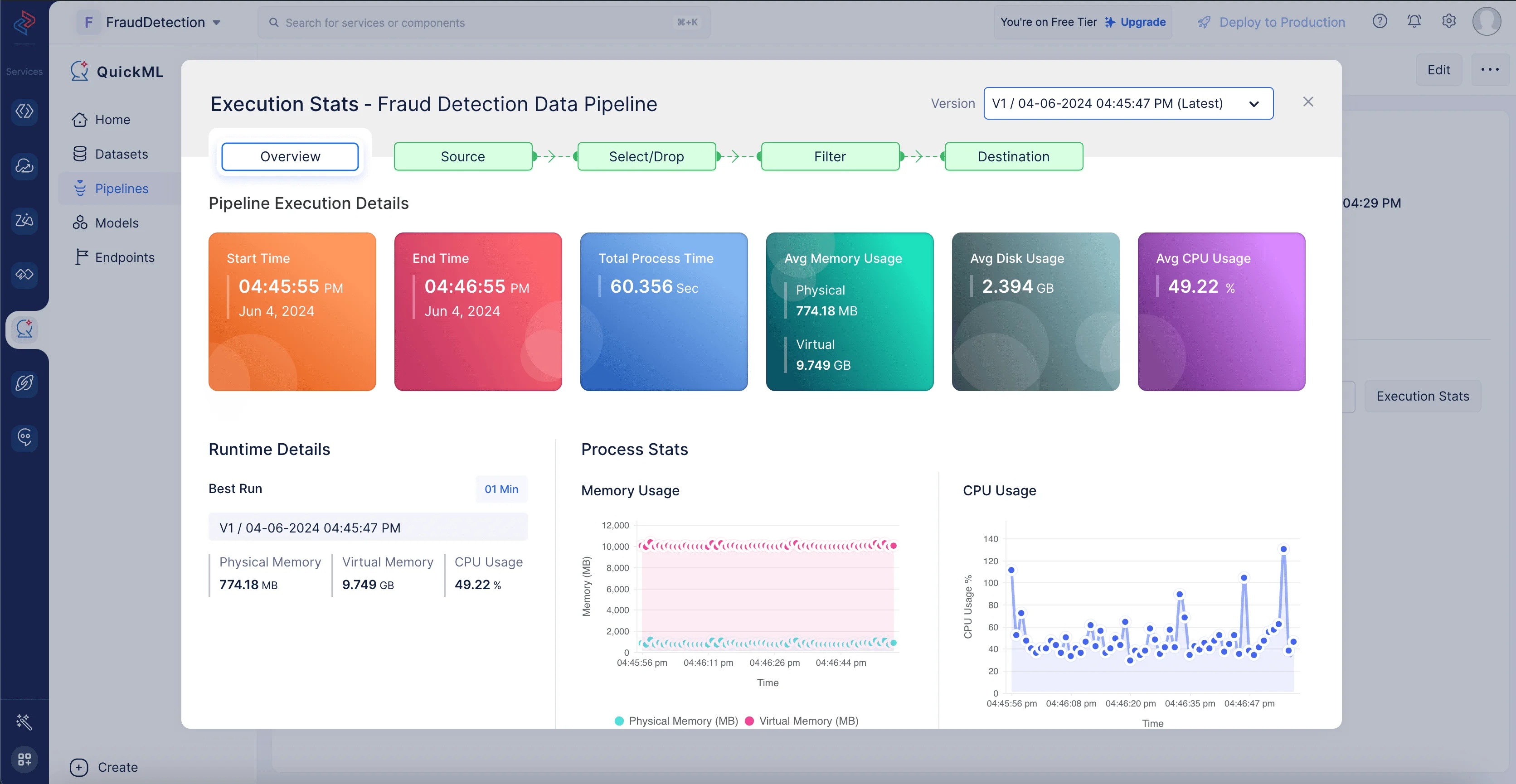
このパートでは、QuickMLを使用したデータ処理方法を確認しました。機械学習モデルの作成に向けてデータを準備するためのさまざまな効果的な方法を提供しています。このデータパイプラインは、Catalystプロジェクト内のさまざまなユースケースに対応する複数のML実験の作成に再利用できます。
最終更新日 2026-03-05 11:43:24 +0530 IST