MLパイプラインの作成
予測モデルを構築するために、前処理済みデータセットをMLパイプラインビルダーで使用します。MLパイプラインの構築における最初のステップは、予測対象のカラムであるターゲットカラムを選択することです。
MLパイプラインを作成するには、まずPipelinesコンポーネントに移動し、Create Pipelineオプションをクリックします。
表示されるポップアップで、パイプラインタイプとしてPredictionを選択し、パイプライン名を入力します。ここではパイプライン名をFraud Detection ML pipeline、モデル名をFraud Detection ML pipeline Modelとします。次に、適切なデータセットとターゲットのカラム名を選択します。
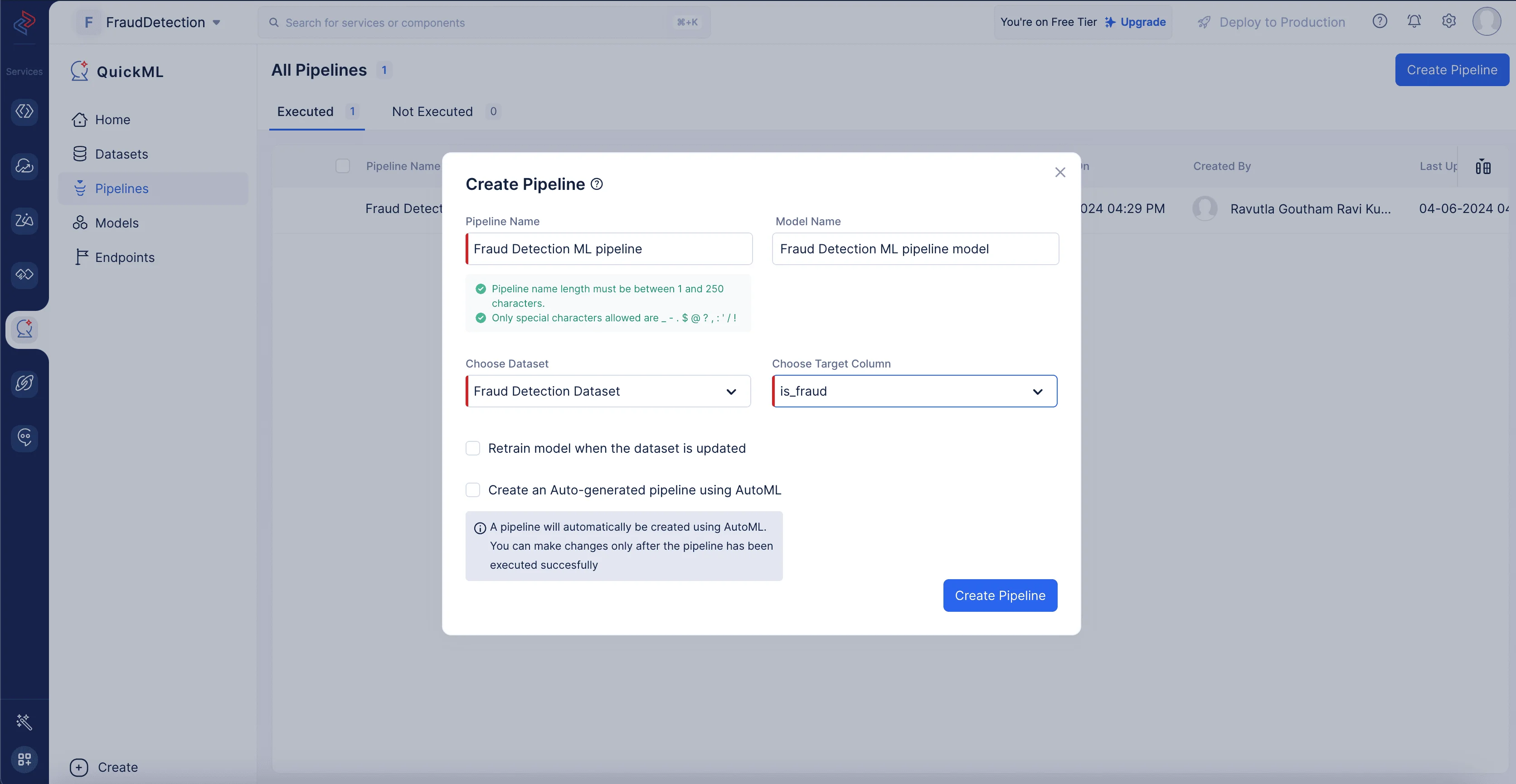
データパイプラインの構築用に選択したソースデータセットを選択する必要があります。前処理済みデータはソースデータセットに反映されているためです。今回のケースでは、前処理とクリーニング用に選択したFraud Detection Datasetをインポートし、ターゲットはis_fraudという名前のカラムです。
-
カラムの正規化
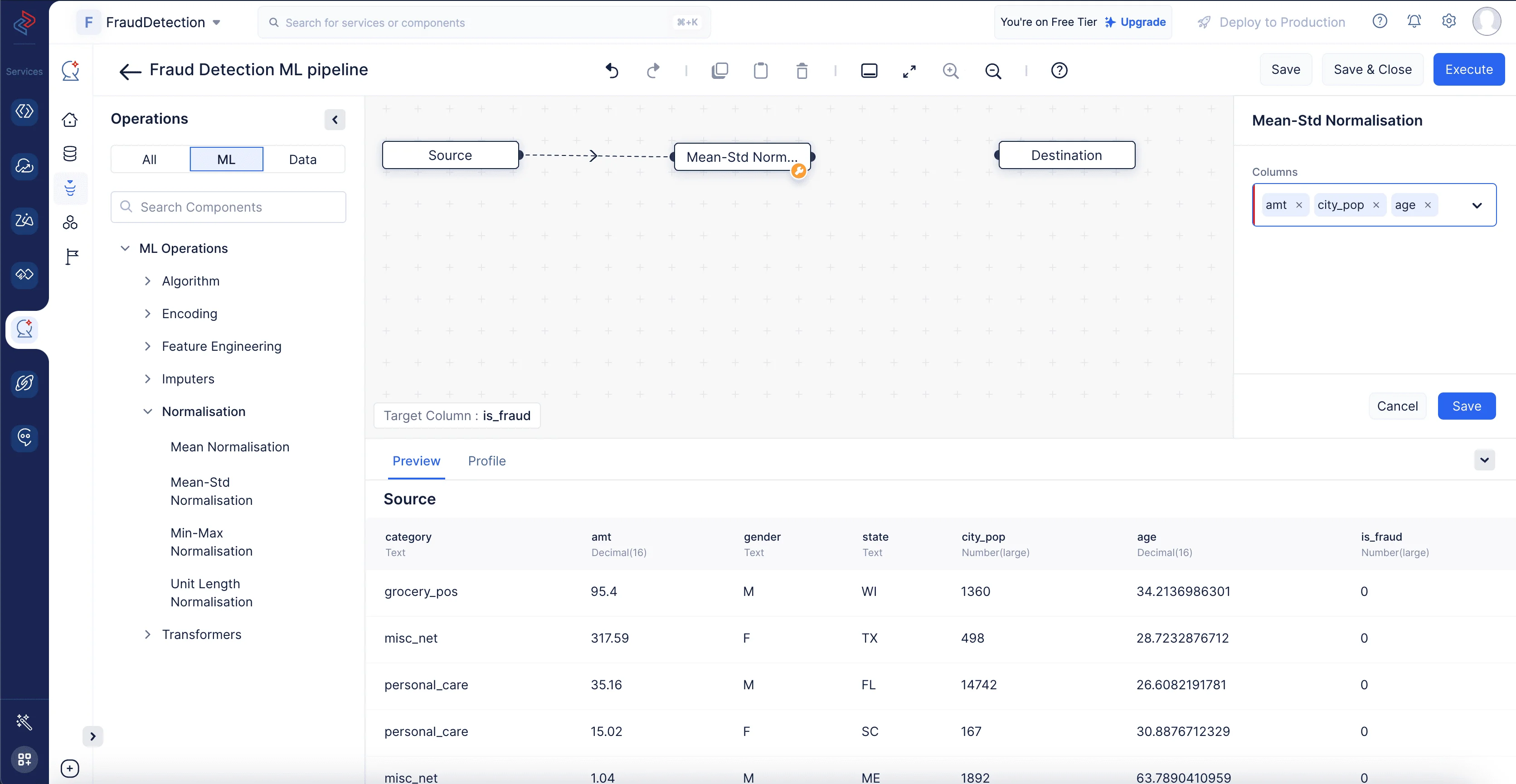
特徴量「amt」、「city_pop」、「age」の値はさまざまな範囲にあるため、Mean-Std Normalizationコンポーネントを使用して、特徴量の値を一般的に0から1の範囲に縮小します。ML operations->Normalizationに移動します。Mean-Std NormalizationノードをMLパイプラインビルダーインターフェースにドラッグ&ドロップします。右側パネルの設定ボックスで、「is_fraud」以外のすべてのカラムを選択し、Saveをクリックします。
-
カテゴリカラムのエンコーディング
エンコーダーは、カテゴリカルデータや非数値データを機械学習アルゴリズムが効果的に処理できる数値形式に変換するために、さまざまなデータ前処理や機械学習タスクで使用されます。
-
One-hotエンコーダー
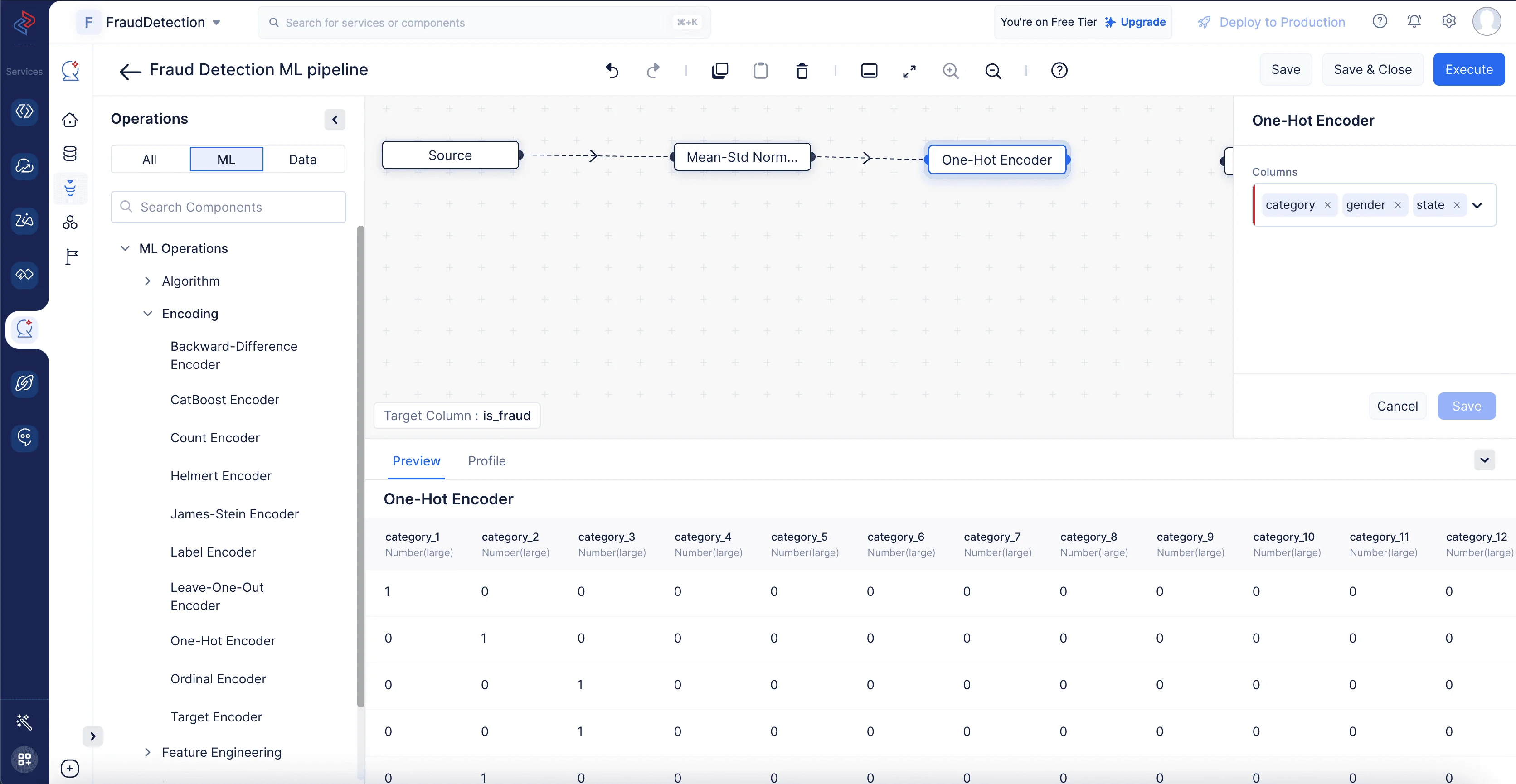
One-hotエンコーディングは、通常、データセットのカテゴリカラムに適用されます。各カテゴリは個別のクラスまたはグループを表します。この方法では、一意のカテゴリごとに新しいバイナリカラムが作成されるため、データセットの次元数が増加します。バイナリカラムの数は、一意のカテゴリ数から1を引いた数に等しくなります。他のすべてのカテゴリが存在しないことから、最後のカテゴリの存在を推測できるためです。
ここでは、One-Hot Encoderノードを使用して、「category」、「gender」、「state」のカラムをエンコードします。QuickMLでML operationsに移動し、Encodingコンポーネントを選択し、One-Hot Encoderを選択して、選択したカテゴリカラムを数値カラムに変換します。
-
-
MLアルゴリズム:
MLパイプライン構築の次のステップは、前処理済みデータのトレーニングに適切なアルゴリズムを選択することです。ここでは、XGBoost分類アルゴリズムを使用してデータをトレーニングします。
XGBoost(Extreme Gradient Boosting)は、分類タスクに広く使用されている人気のある強力な機械学習アルゴリズムです。複数の決定木の予測を組み合わせて強力な予測モデルを作成するアンサンブル学習手法です。XGBoostは、その速度、スケーラビリティ、複雑なデータセットを処理する能力で知られています。
QuickMLのMLパイプラインビルダーで、ML operationsからXGBoost Classificationノードをドラッグ&ドロップして、XGBoost分類手法をすばやく構築できます。Algorithmを選択し、Classificationをクリックし、XGBoost Classificationを選択します。
特定のデータセットに最適化するためにチューニングパラメータを調整することもできます。今回のケースでは、デフォルト設定のままで問題ありません。すべての設定が完了したら、パイプラインを保存してさらなるテストとデプロイに備えます。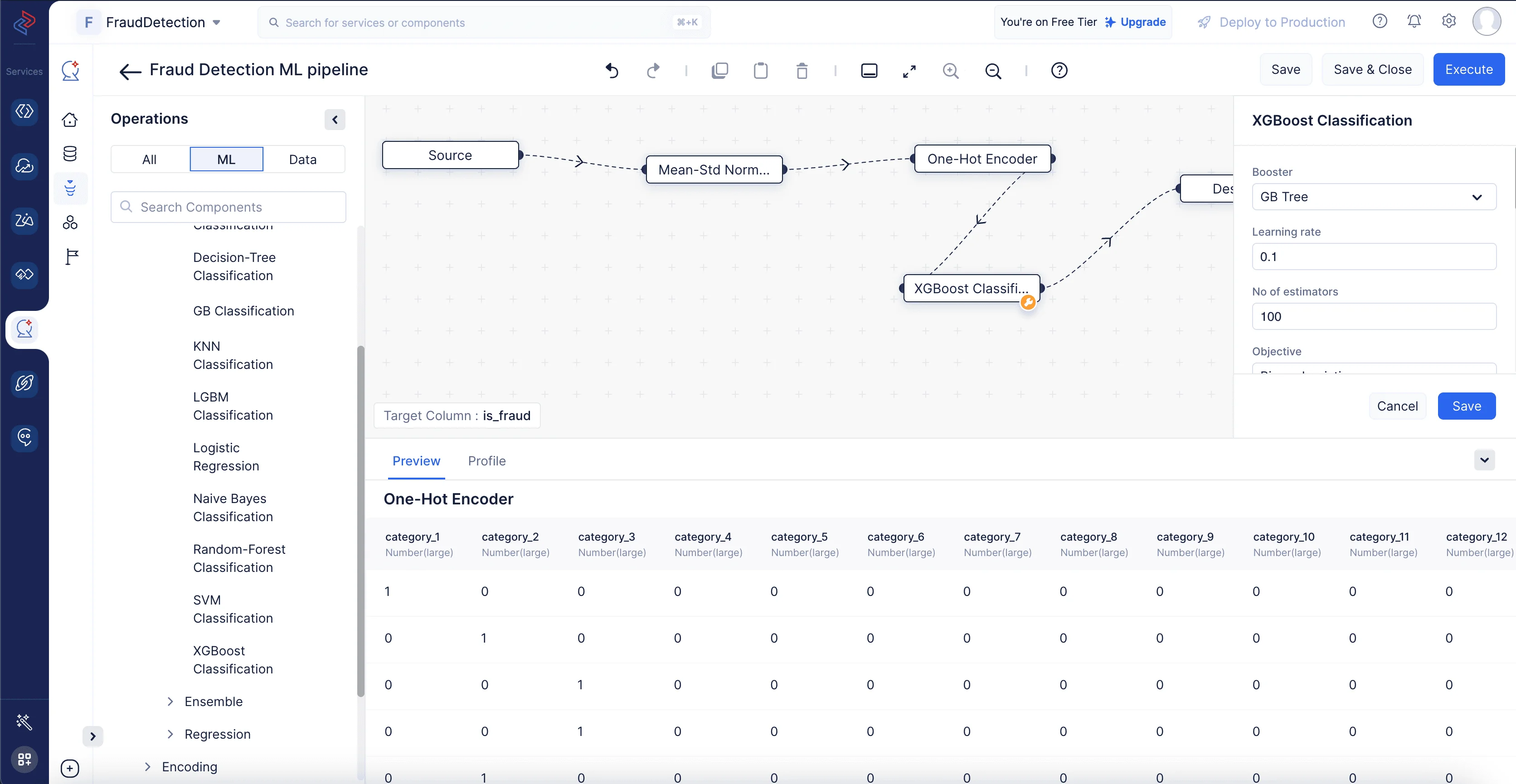
アルゴリズムノードをドラッグ&ドロップすると、その終端ノードが自動的にDestinationノードに接続されます。Saveをクリックしてパイプラインを保存し、パイプラインビルダーページの右上にあるExecuteボタンをクリックしてパイプラインを実行します。 以下のページにリダイレクトされ、実行ステータス付きの実行済みパイプラインが表示されます。パイプラインの実行が成功したことが明確に確認できます。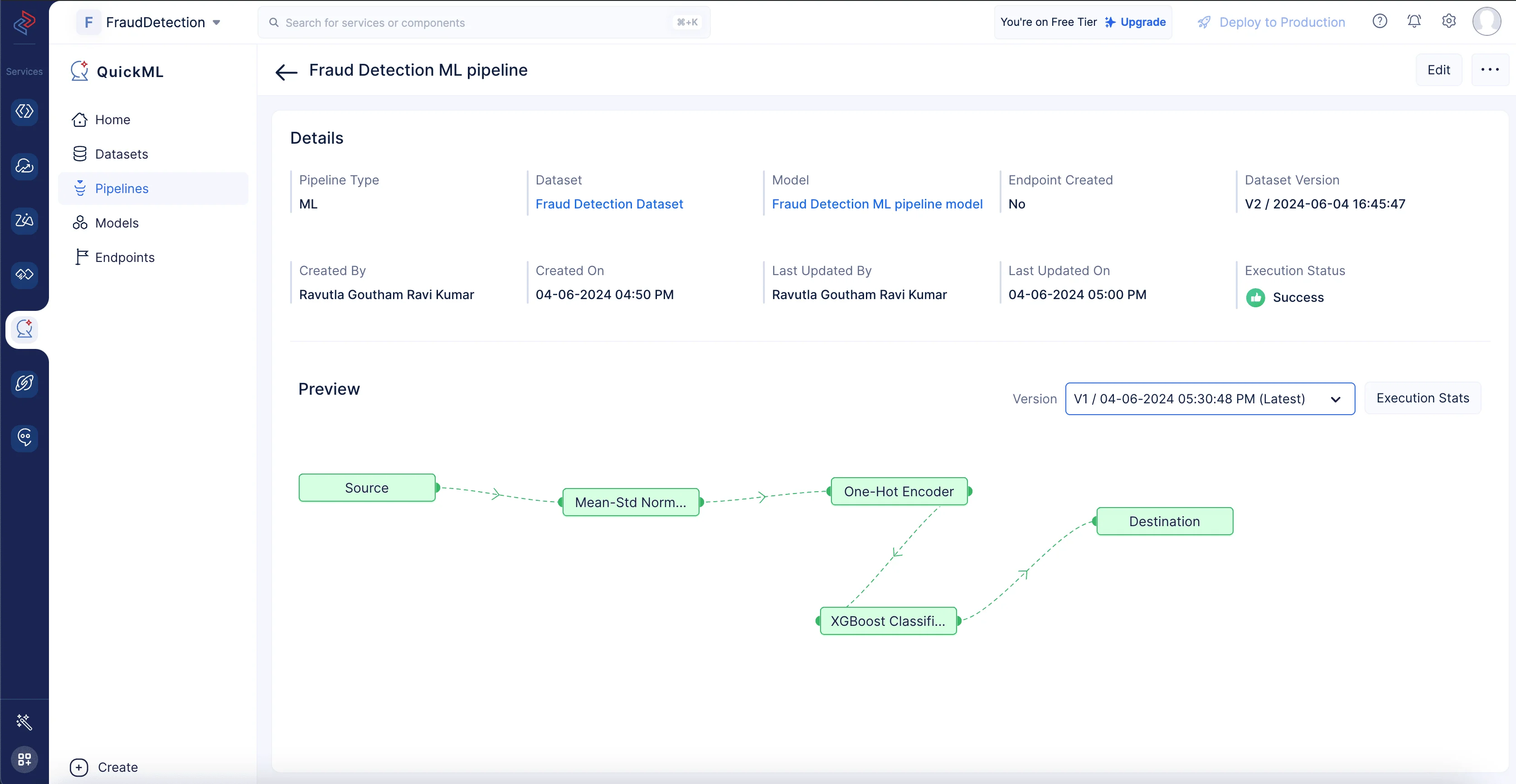
Execution Statsをクリックすると、モデル実行の各ステージに関するコンピュートの詳細を確認できます。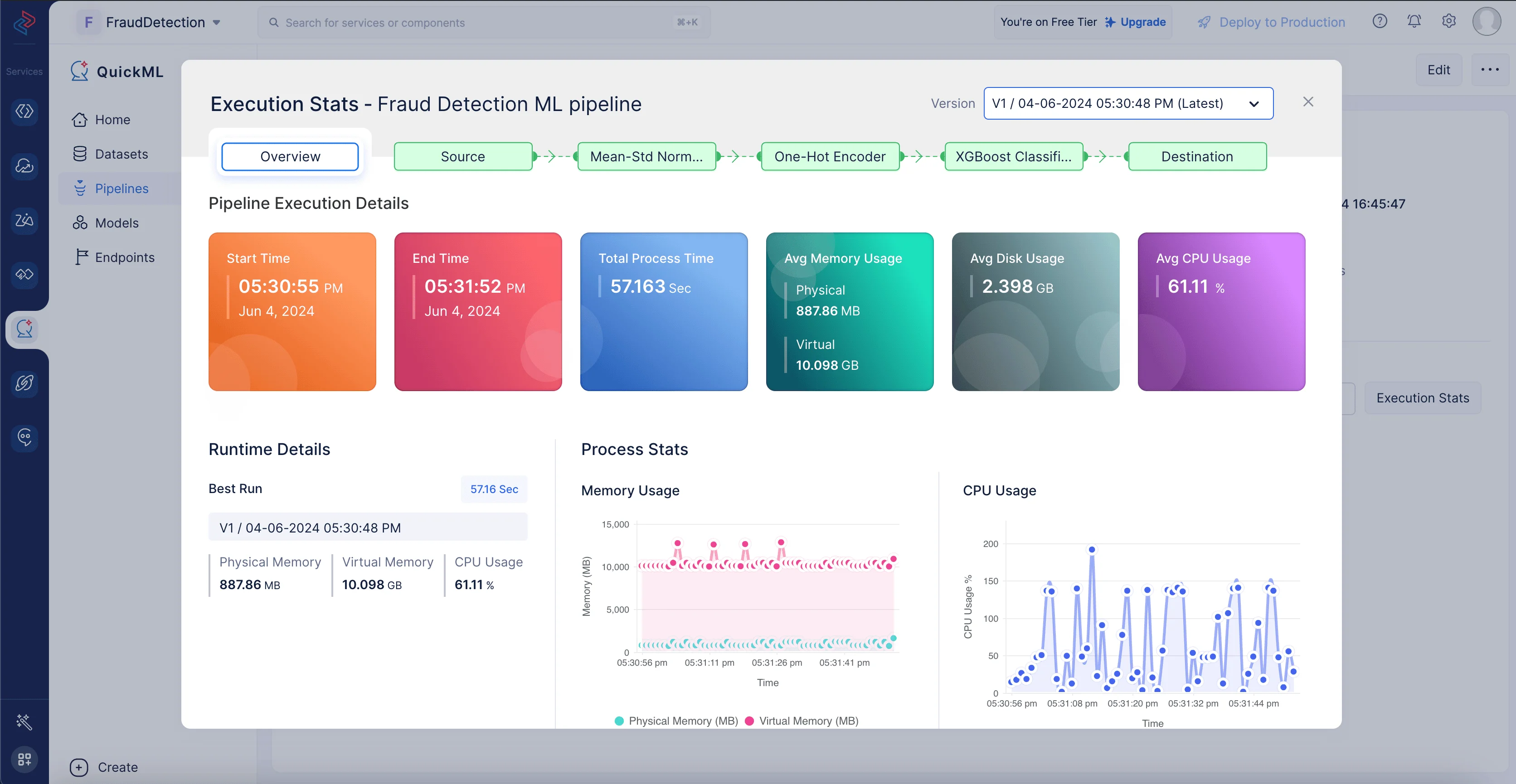
MLワークフローが正常に完了すると、予測モデルが作成され、Modelセクション(Fraud Detection ML pipeline modelをクリック)で確認できます。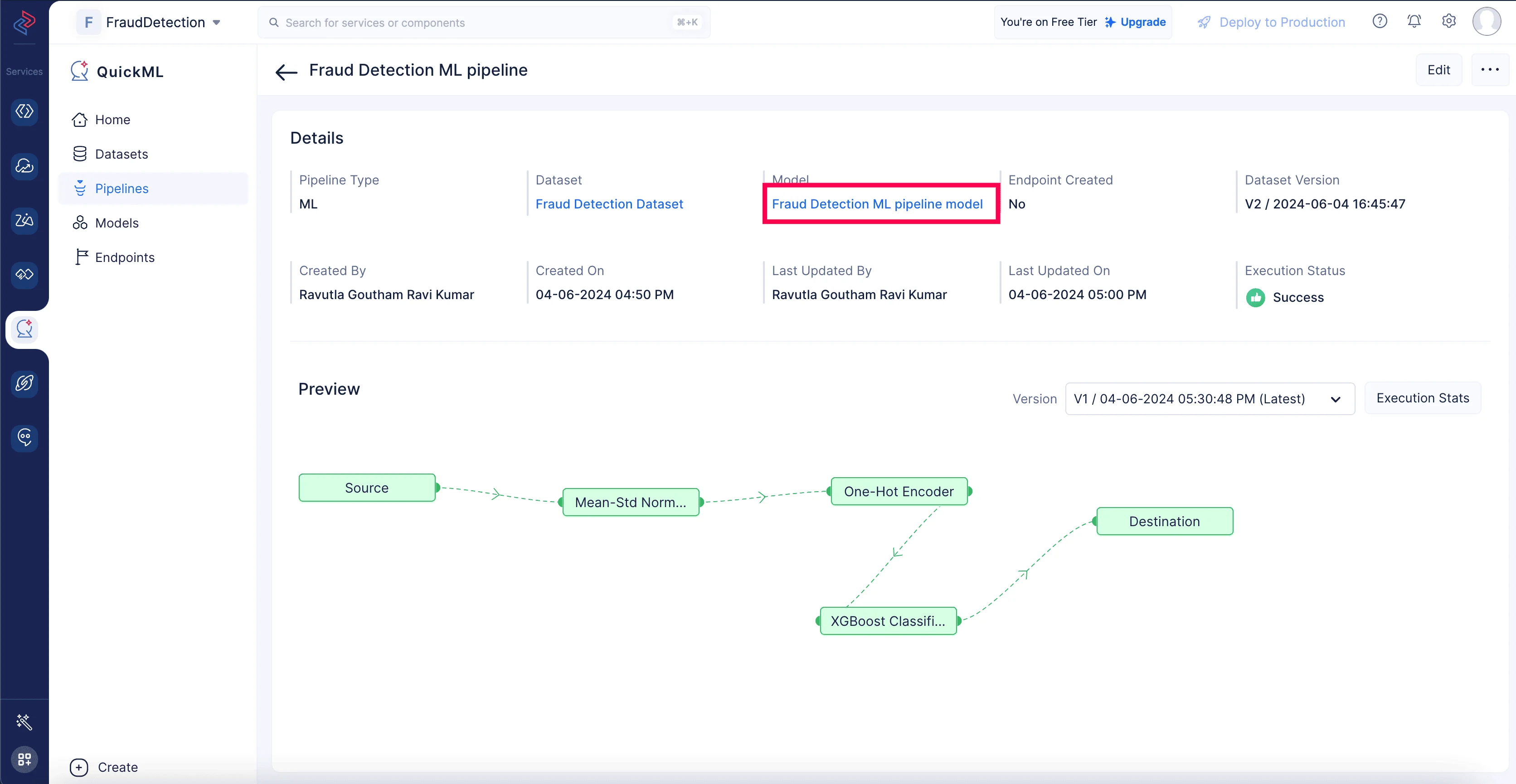
これにより、データに基づいて予測を行う際のモデルの効率性とパフォーマンスに関する有用な知見が得られます。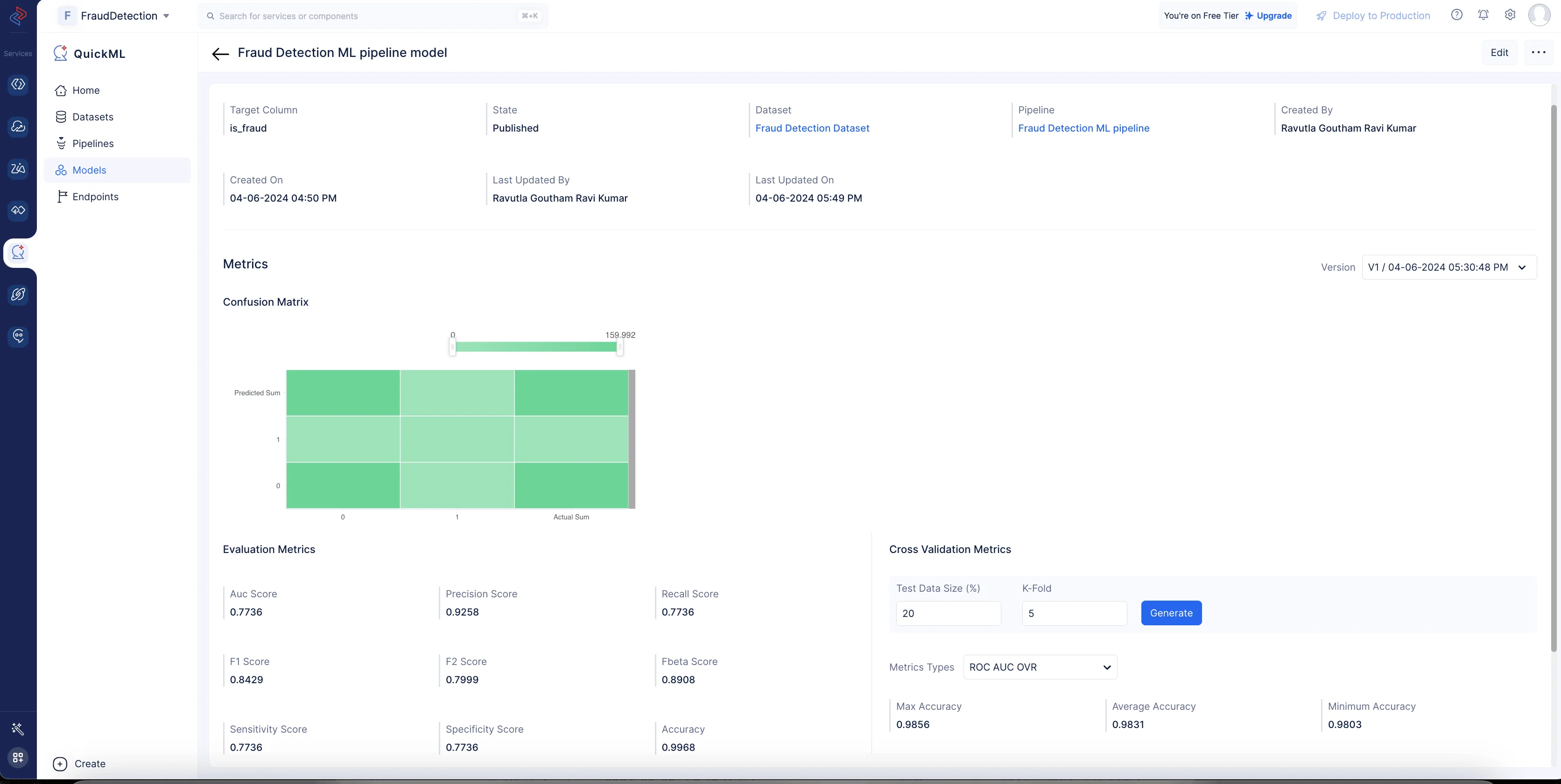
最終更新日 2026-03-05 11:43:24 +0530 IST