データパイプラインの作成
データセットのアップロードが完了したので、次にそのデータセットを使用してデータパイプラインを作成します。
- 左メニューのDatasetsコンポーネントに移動します。データパイプラインを作成する方法は2つあります:
- データセットをクリックし、ページ右上のCreate Pipelineをクリックします。
- 以下の画像のように、データセット名の左側にあるペンアイコンをクリックします。
ここでは、前処理用にChurn_1データセットをアップロードしています。Churn_2は、以降の前処理ステップでこのデータセットに追加されます。
- パイプライン名を「Churn Prediction Data Pipeline」と入力し、Create Pipelineをクリックします。
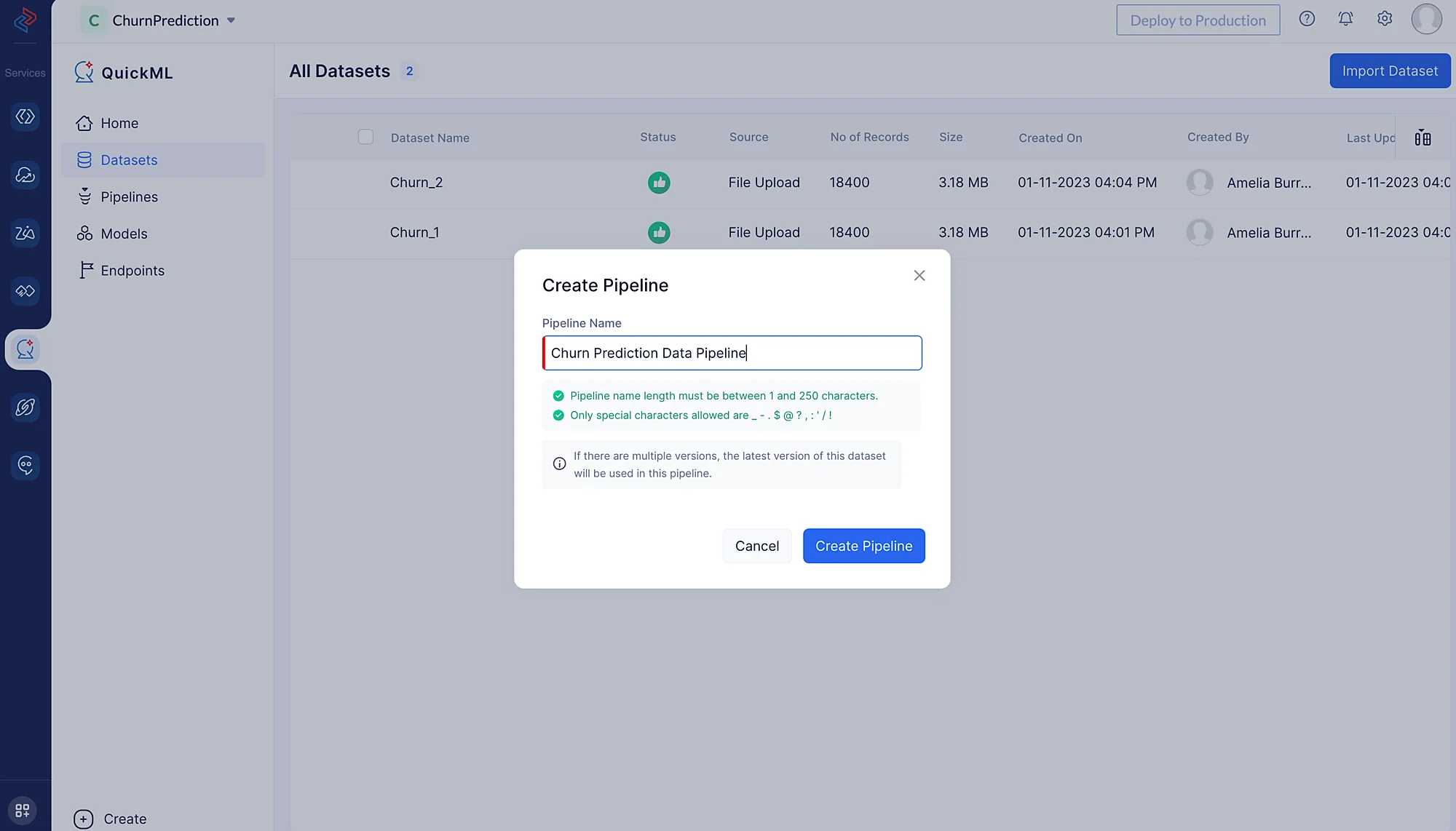
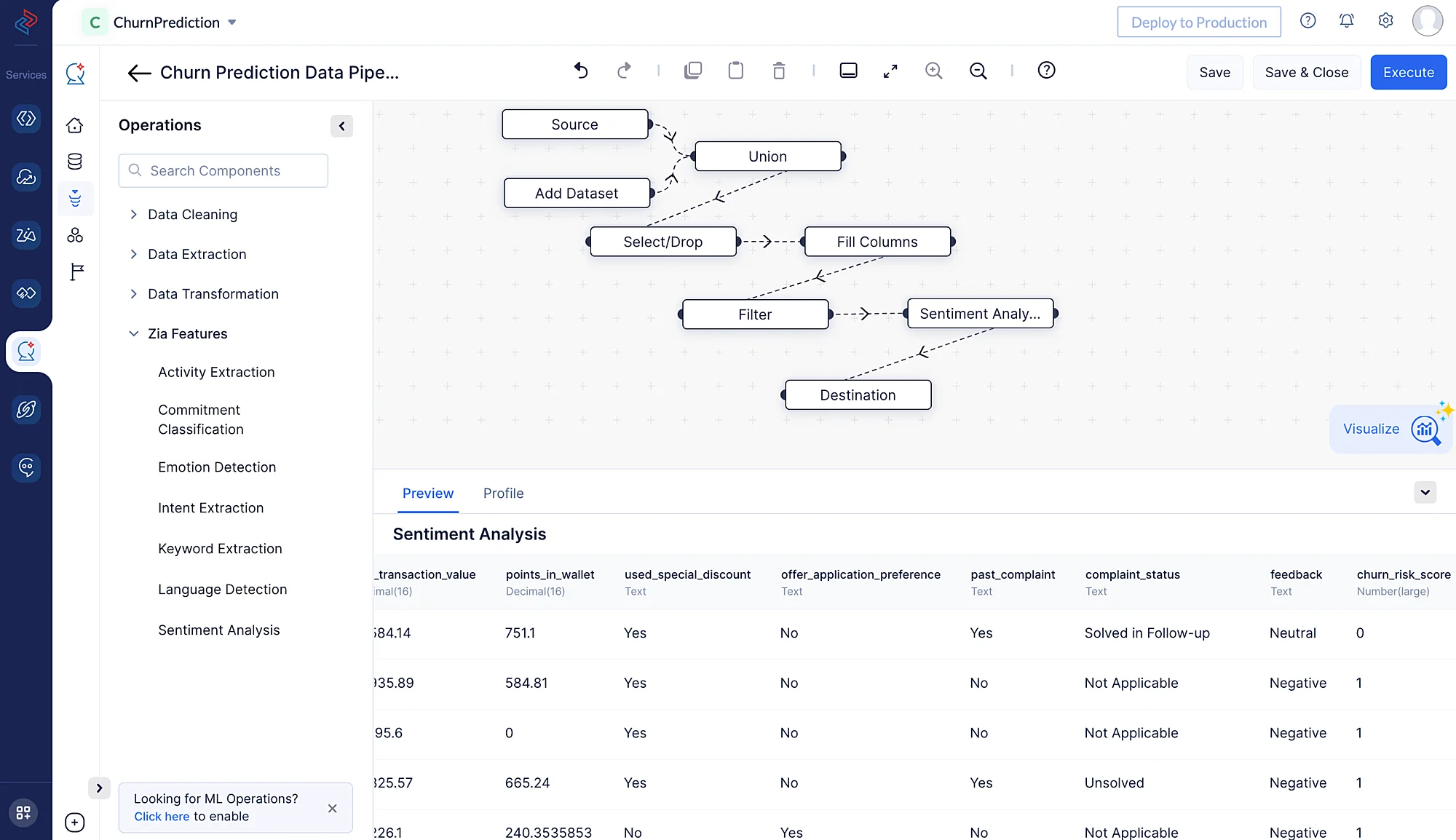
以下のスクリーンショットのように、パイプラインビルダーインターフェースが開きます。
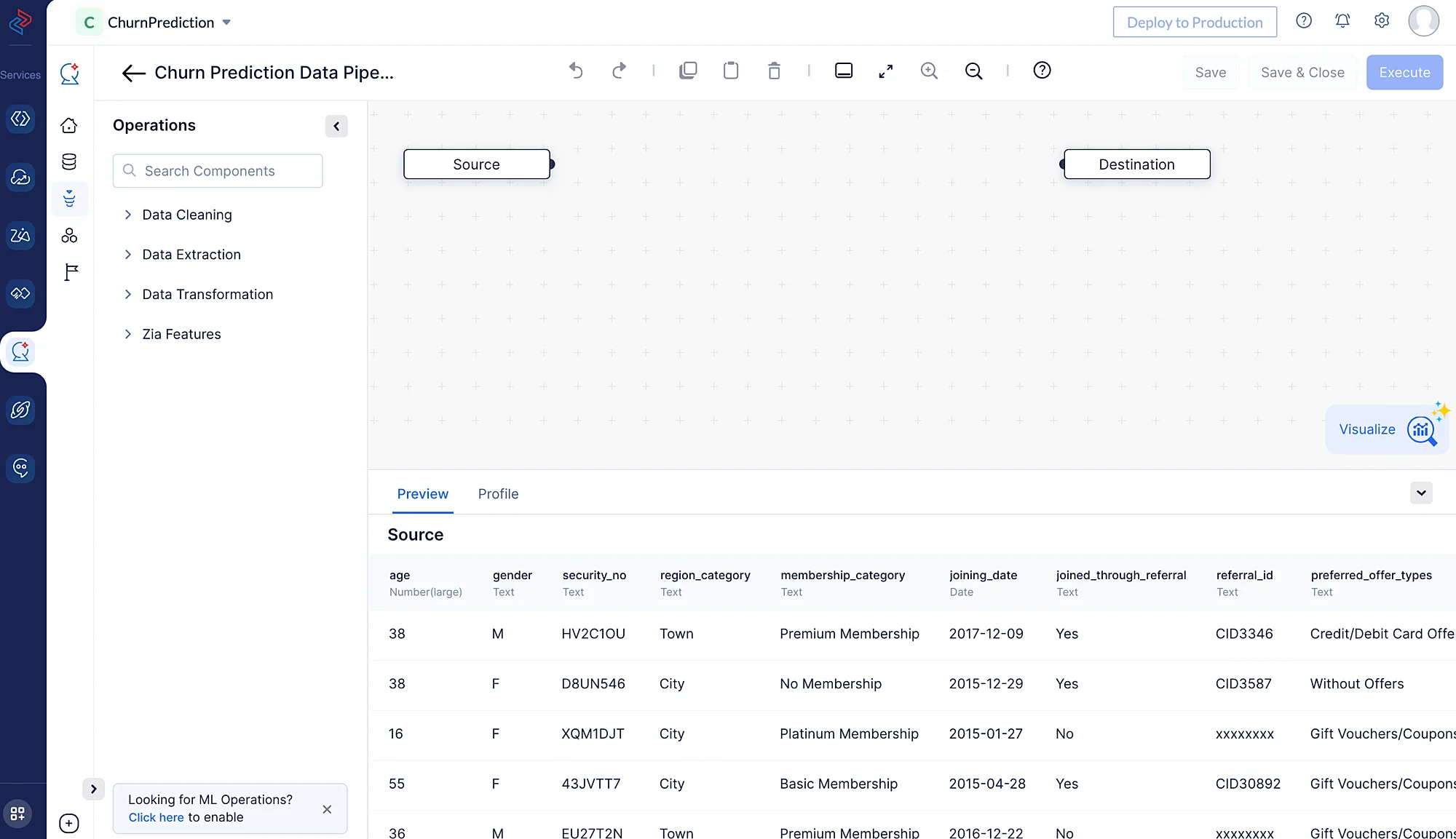
データセットのクリーニング、精製、変換を行い、データパイプラインを実行するために、以下の一連のデータ前処理操作を実行します。各操作には、パイプラインの構築に使用される個別のデータノードが含まれます。
QuickMLによるデータ前処理
-
2つのデータセットの結合
QuickMLのを使用して、新しいデータセットを追加できます(追加するデータセットは事前にアップロードしておく必要があります)。ここでは、既存のデータセットとマージするためにChurn_2データセットを追加します。Custom Nameセクションでノードのカスタム名を指定できますが、ここではデフォルト名のAdd datasetのままにしています。次に、Saveボタンをクリックします。
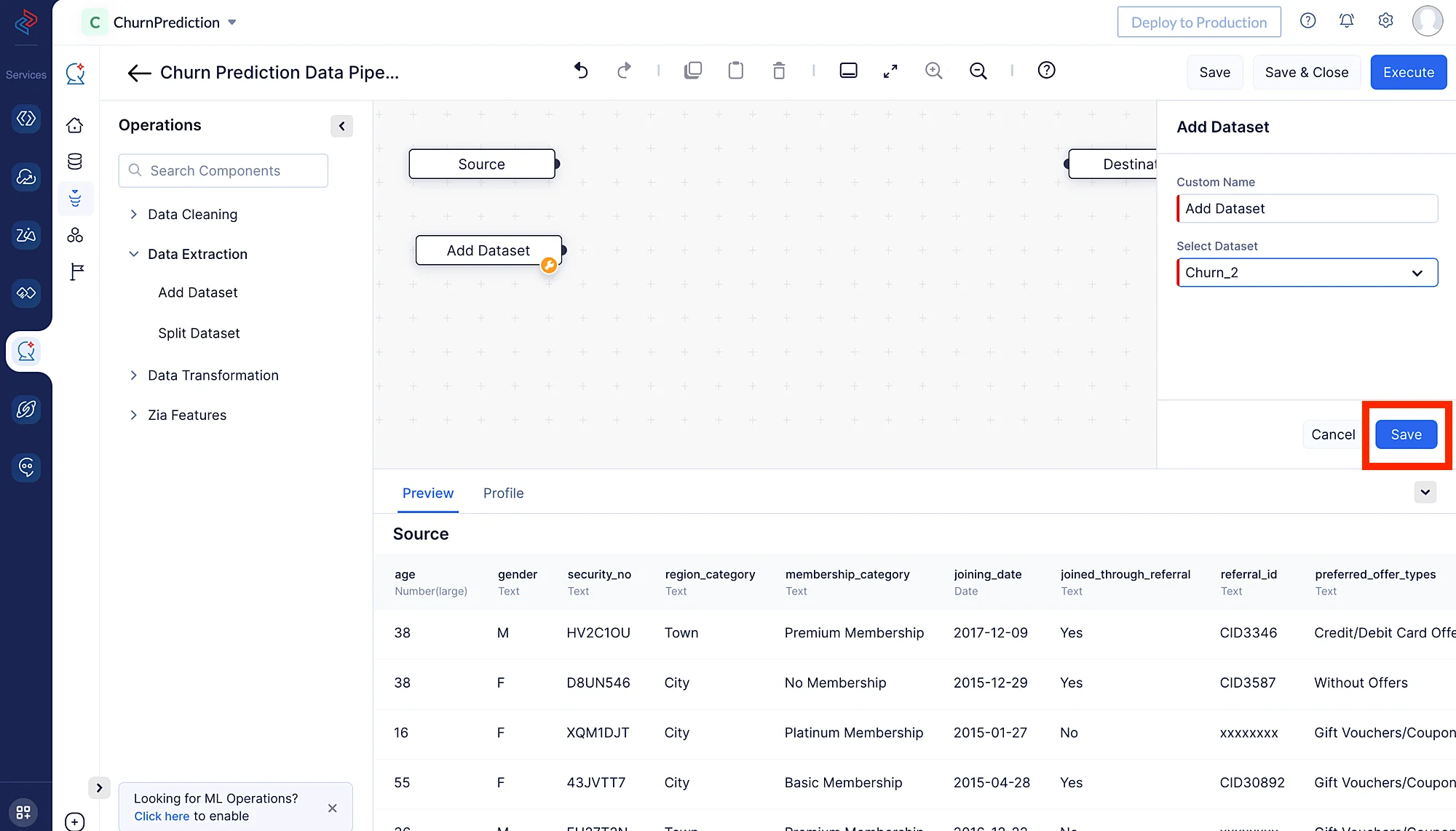
- 左パネルのData Extractionをクリックし、Add Dataset ノードを選択します。これにより、新しいデータセット(Churn_2)をパイプラインに追加できます。
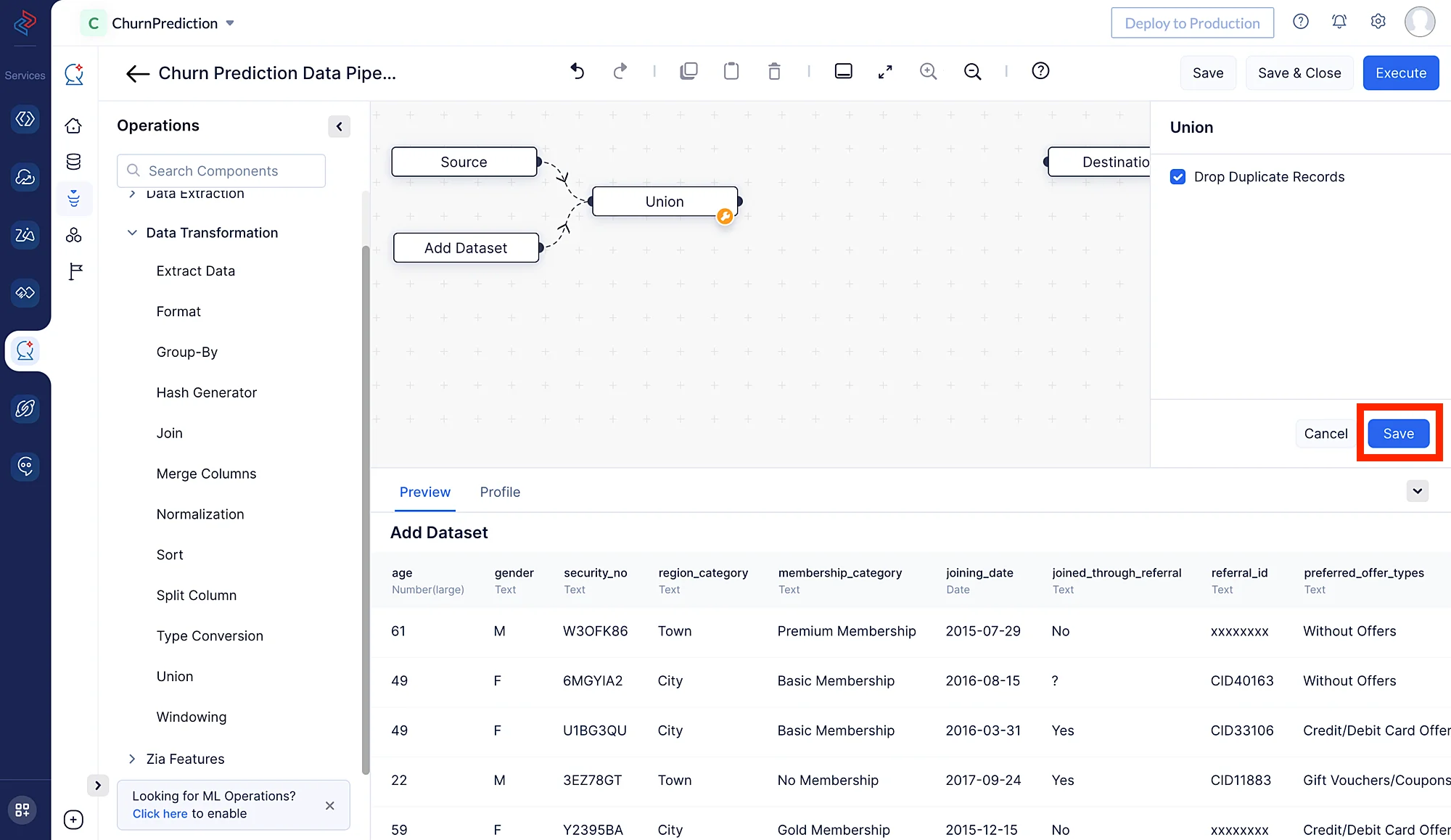
- 左パネルのData Transformationを選択し、Union ノードを選択します。次に、2つのノード間のリンクを接続してノード間の結合を行います。これにより、Churn_1とChurn_2の2つのデータセットが1つのデータセットに結合されます。
- いずれかのデータセットに重複レコードが存在する場合、操作実行時に「Drop Duplicate Records」のチェックボックスを必ずオンにしてください。次に、Saveボタンをクリックします。これにより、両方のデータセットから重複レコードが削除されます。
-
列の選択/削除
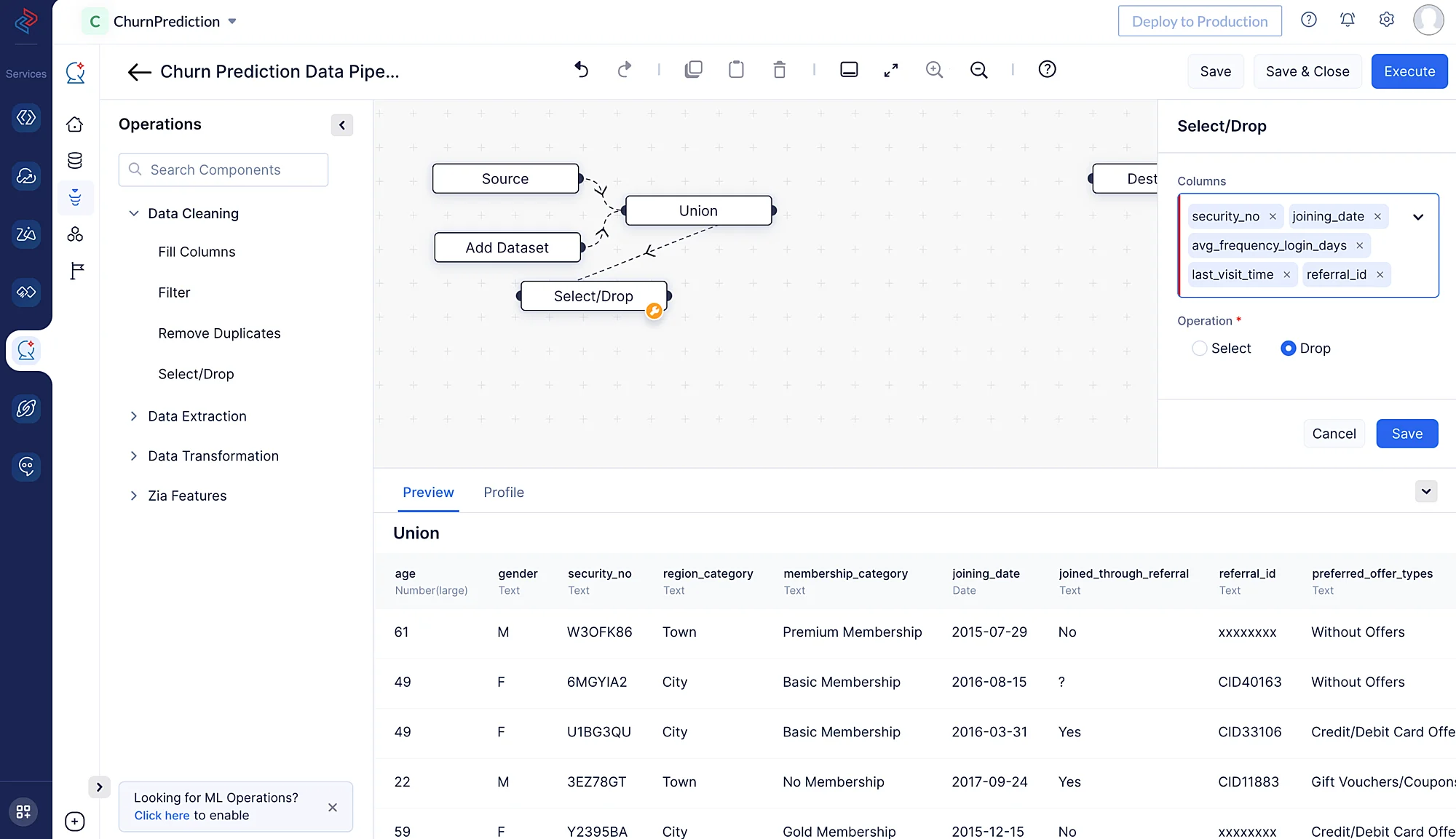
データセットから列を選択または削除することは、データ分析や機械学習における一般的なデータ前処理ステップです。列の選択や削除は、分析やモデリングタスクの具体的な目的と要件に応じて判断します。 このデータセットからモデル学習に不要な列は、「security_no」、「joining_date」、「avg_frequency_login_days」、「last_visit_time」、「referral_id」です。QuickMLでは、Data CleaningコンポーネントのSelect/Drop ノードを使用して、モデル学習に必要なフィールドをデータセットから素早く選択できます。
-
データセットの列に値を補填する
QuickMLのFill Columns ノードを使用すると、特定の条件に基づいて列の値を簡単に補填できます。要件に応じて、null値や非null値を補填できます。ここでは、「joined_through_referral」と「medium_of_operation」の列について、「?」が含まれる行をカスタム値「Not mentioned」で補填します。「points_in_wallet」列については、空の値をカスタム値「0」で置換します。
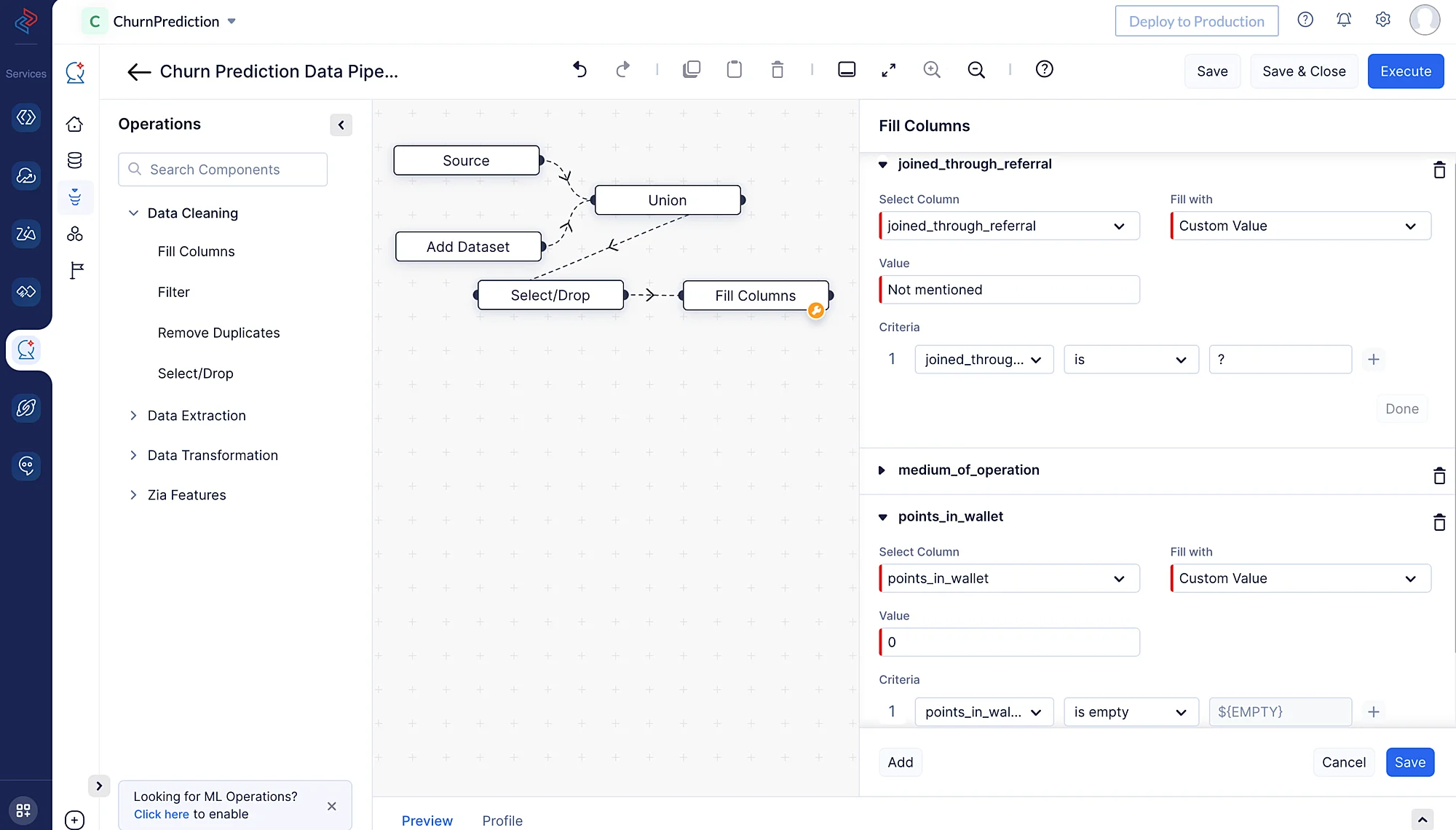
ドロップダウンメニューから、列に適したデータ型を選択します。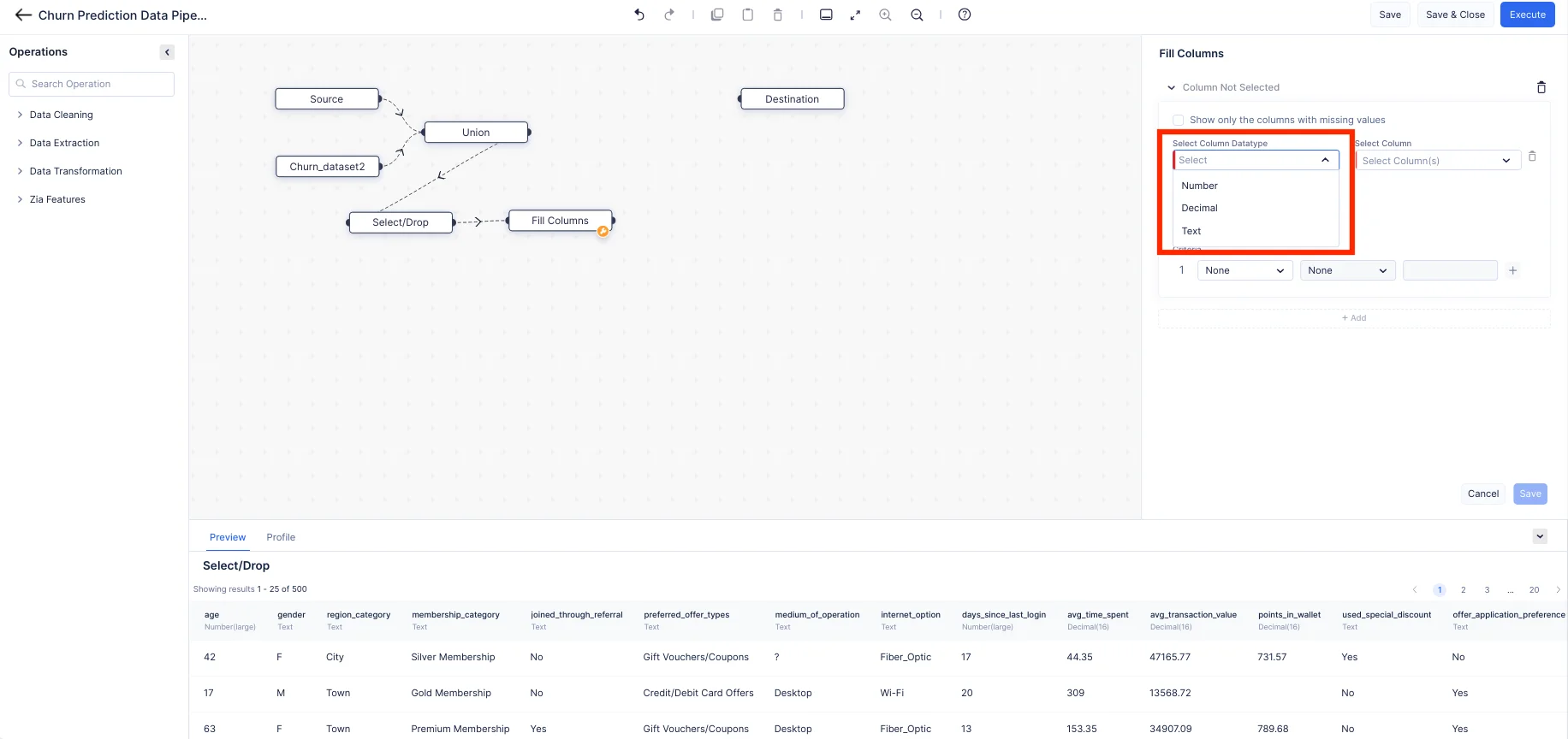
“+”ボタンをクリックして複数の条件を追加し、条件を選択した後にSaveボタンをクリックします。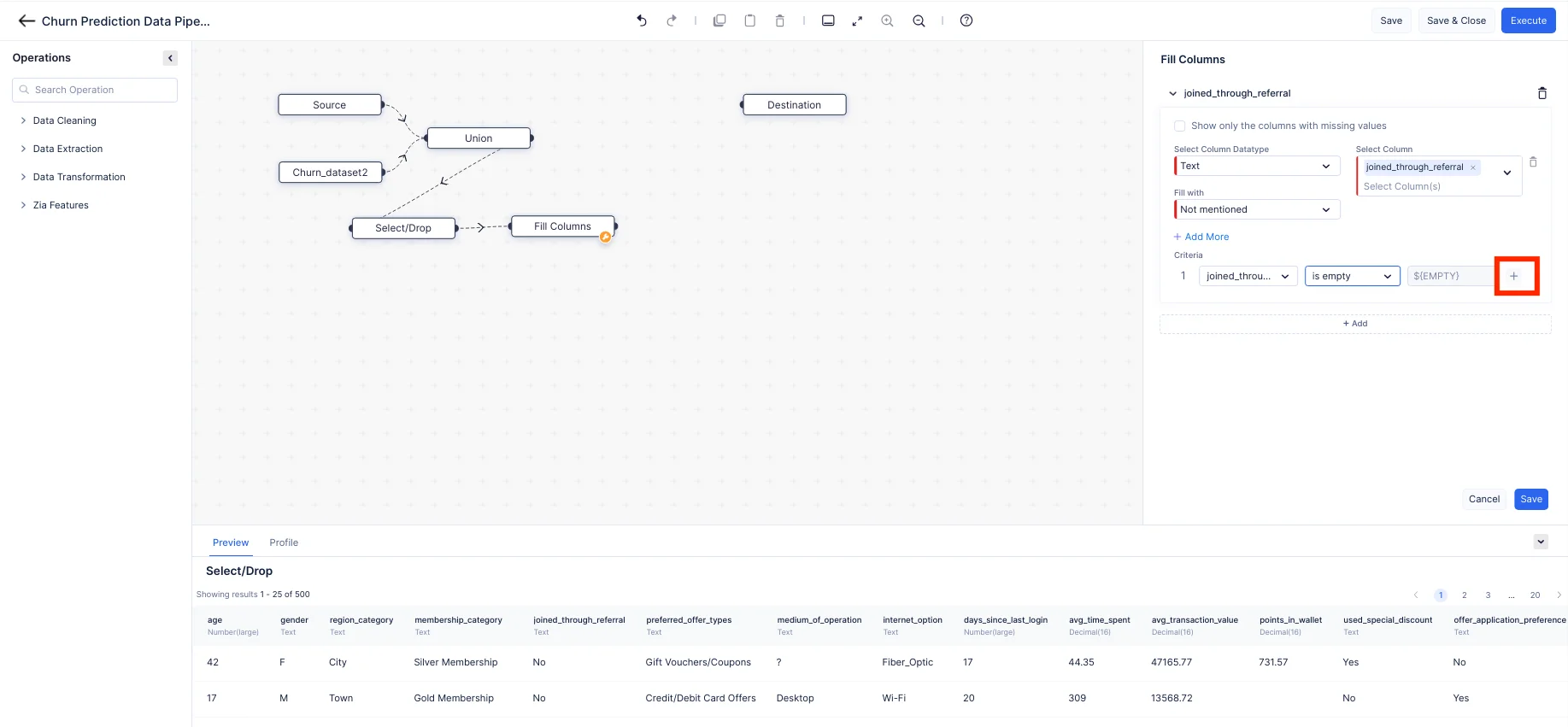
-
データのフィルタリング
データセットのフィルタリングとは、特定の基準や条件を満たす行のサブセットをDataFrameから選択することです。ここでは、Data CleaningセッションのFilter ノードを使用して、「days_since_last_login」、「avg_time_spent」、「points_in_wallet」列の値が「0」以上のものをフィルタリングし、「preferred_offer_types」と「region_category」列については空でない値を持つものをフィルタリングします。
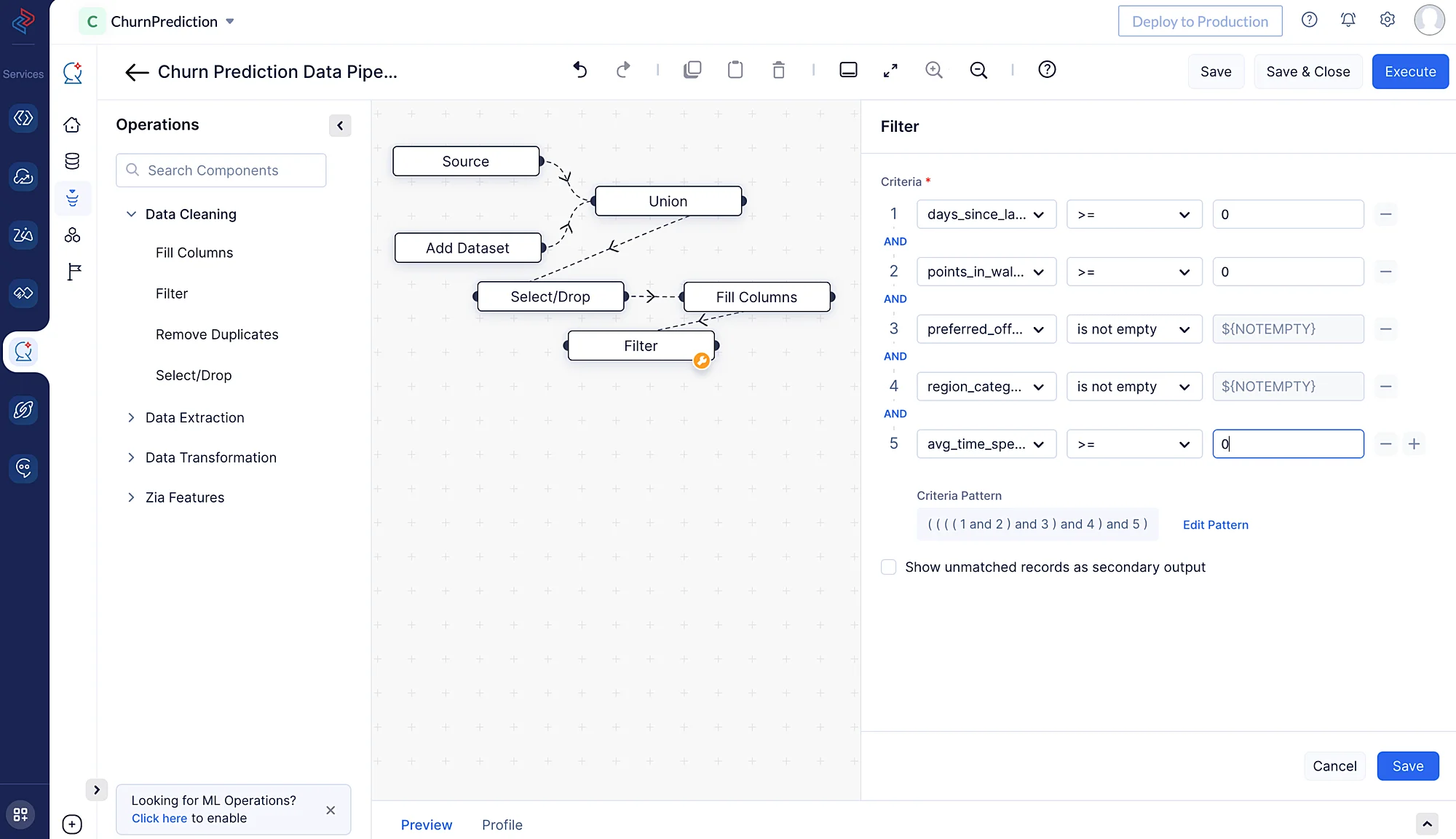
-
感情分析
感情分析は、顧客フィードバックやレビューなどのテキストに含まれる感情や感情的なトーンを判定するための手法です。感情分析の目的は、テキストが伝える感情や意見に基づいて、ポジティブ、ネガティブ、またはニュートラルに分類することです。 ここでは、商品に関するフィードバックが含まれている「feedback」という列があります。Zia Features配下のSentiment Analysis ノードを使用して、列の値をポジティブ、ネガティブ、またはニュートラルに分類できます。 「feedback」列の値をSentiment Analysisノードの結果で置換する場合は、Replace in placeの横にあるチェックボックスをオンにしてください。
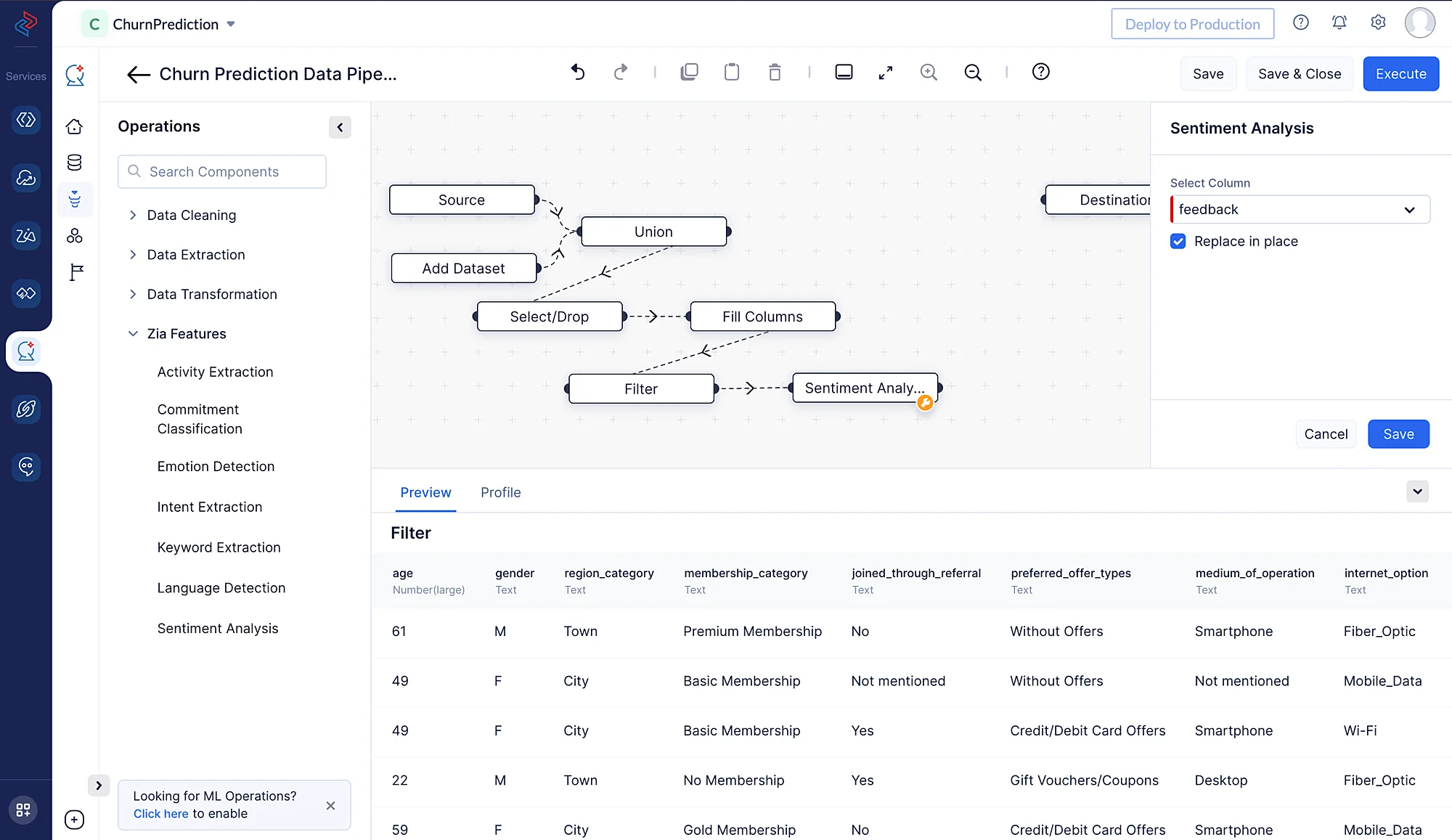
-
保存と実行
次に、Sentiment Analysis ノードをDestinationノードに接続します。すべてのノードが接続されたら、Saveボタンをクリックしてパイプラインを保存します。その後、Executeボタンをクリックしてパイプラインを実行します。
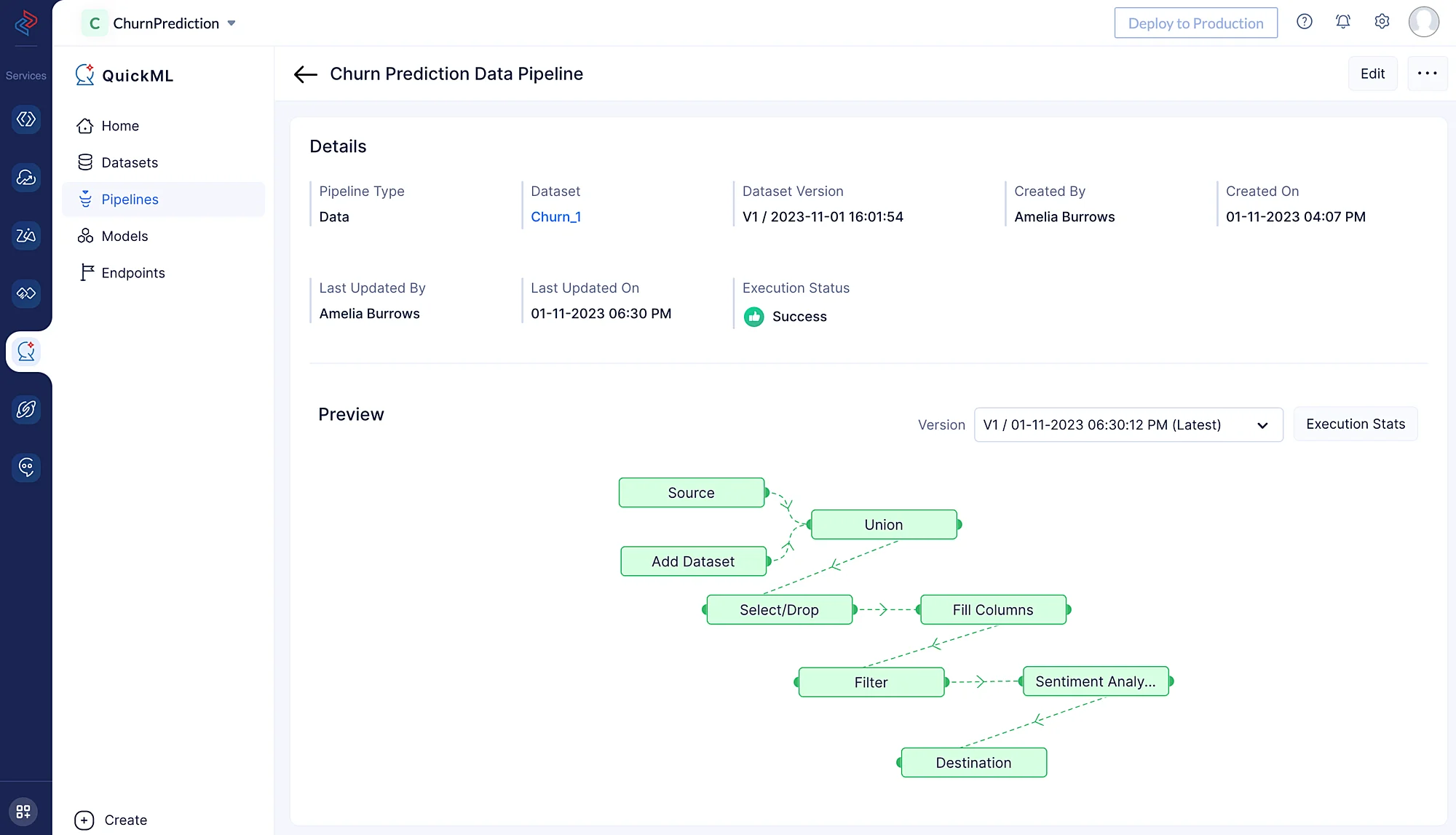
以下のページにリダイレクトされ、実行ステータスとともに実行されたパイプラインが表示されます。パイプラインの実行が成功したことが確認できます。
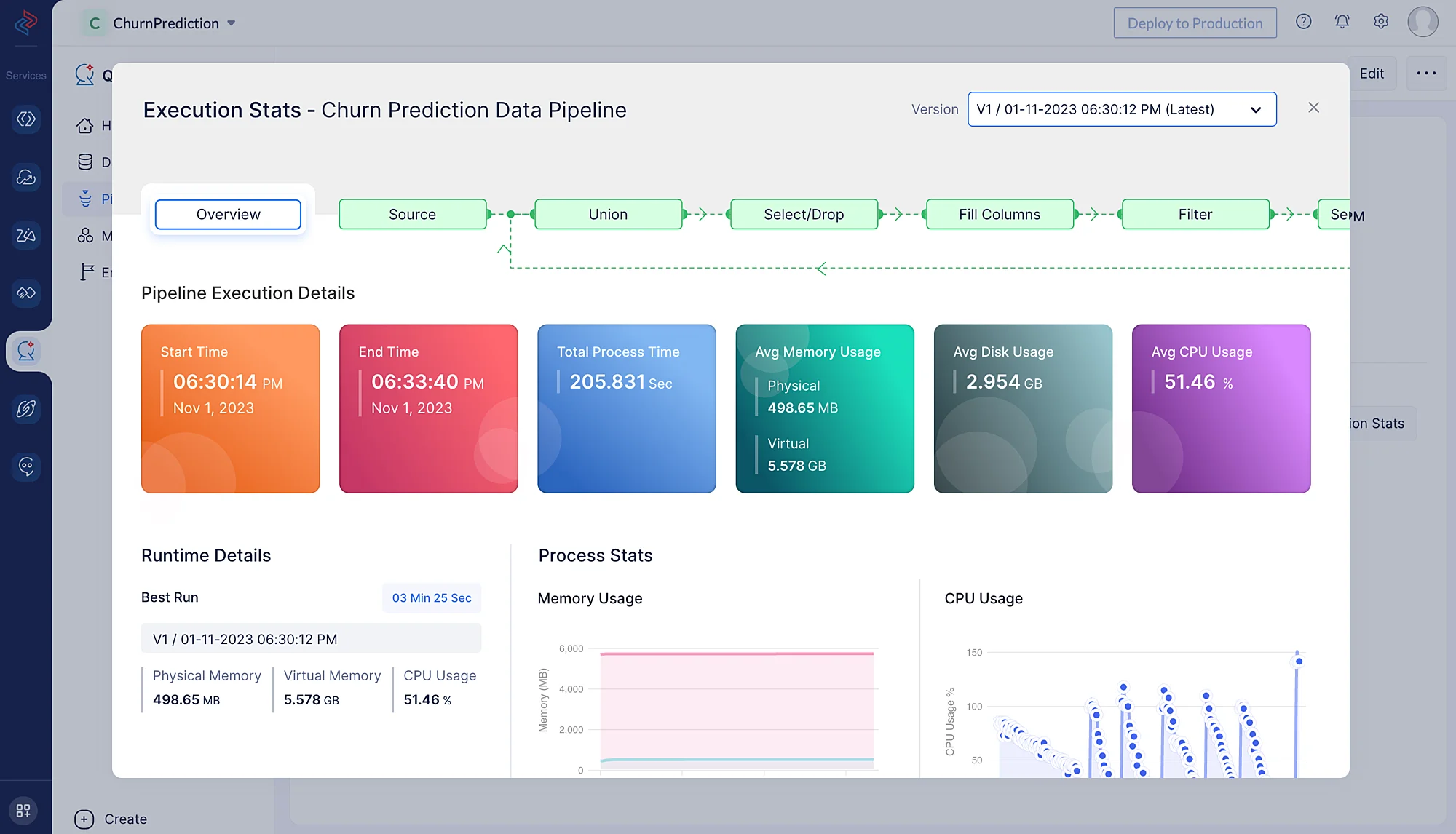
Execution Statsをクリックすると、以下のようにコンピュート使用量の詳細を確認できます。
このパートでは、QuickMLを使用したデータ処理方法について説明しました。機械学習モデルの構築に向けてデータを準備するためのさまざまな効果的な手法を紹介しました。このデータパイプラインは、Catalystプロジェクト内のさまざまなユースケースに対して、複数のML実験を作成するために再利用できます。
最終更新日 2026-03-05 11:43:24 +0530 IST