データパイプラインの作成
データセットのアップロードが完了したので、次にそのデータセットを使用してデータパイプラインを作成します。
-
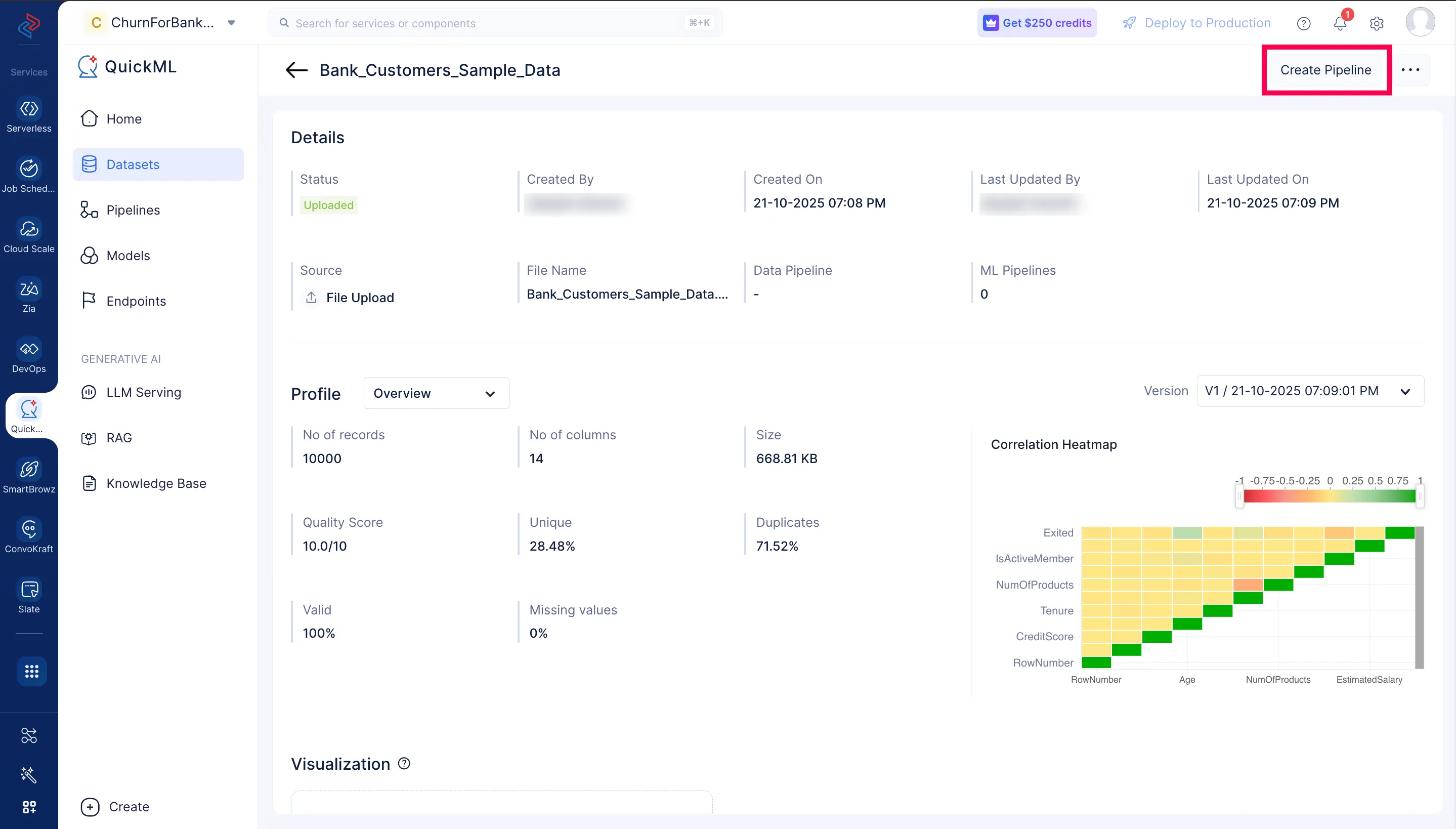
左メニューのDatasetsコンポーネントに移動します。データパイプラインを作成する方法は2つあります。
- データセットをクリックし、ページ右上のCreate Pipelineをクリックします。
- 下の画像に示すように、データセット名の左側にあるペンアイコンをクリックします。
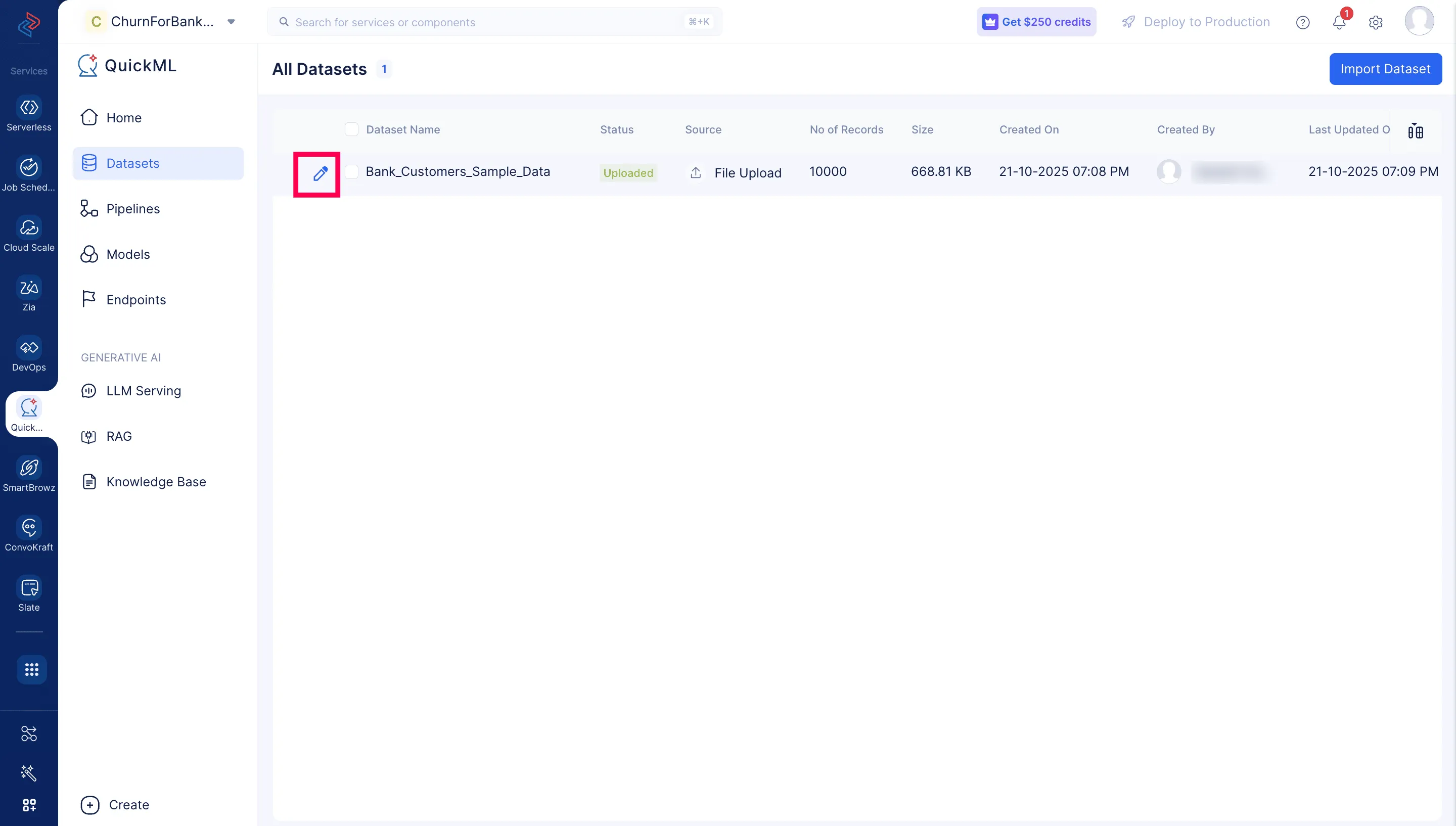
ここでは、前処理用にBank_Customers_Sample_Dataデータセットをアップロードしています。
- データセットをクリックし、ページ右上のCreate Pipelineをクリックします。
-
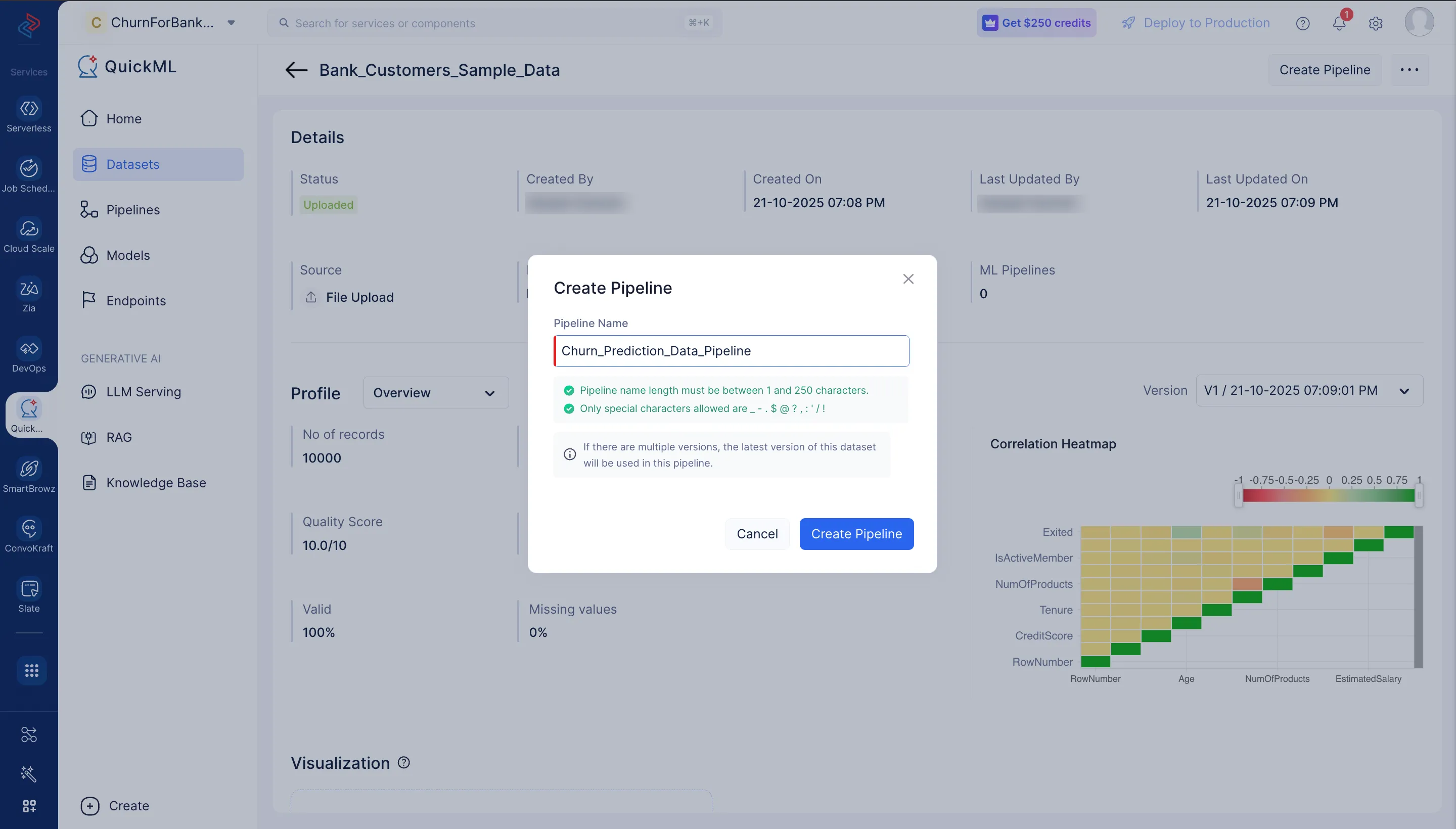
パイプラインに「Churn_Prediction_Data_Pipeline」と名前を付け、Create Pipelineをクリックします。
下のスクリーンショットに示すように、パイプラインビルダーインターフェースが開きます。
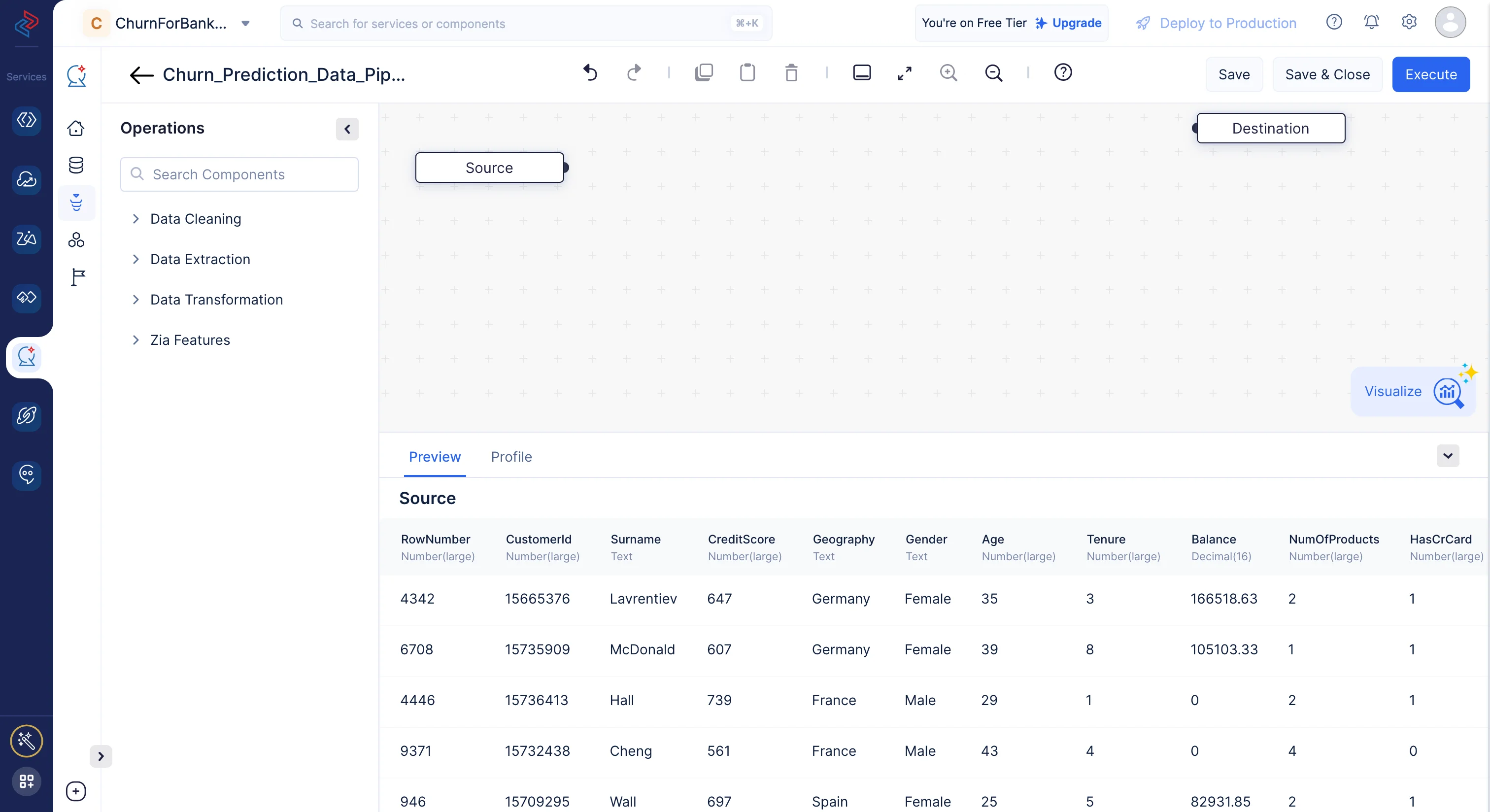
データセットのクリーニング、精製、変換を行い、データパイプラインを実行するために、以下の一連のデータ前処理操作を実行します。これらの各操作は、パイプラインの構築に使用される個別のデータノードで構成されています。
QuickMLによるデータ前処理
-
列の選択/削除
データセットから列を選択または削除することは、データ分析や機械学習における一般的なデータ前処理ステップです。列の選択や削除は、分析やモデリングタスクの目的と要件に応じて決定します。 このデータセットでモデルのトレーニングに不要な列は、「RowNumber」、「CustomerId」、「Surname」です。QuickMLでは、Data CleaningコンポーネントのSelect/Drop ノードを使用して、モデルトレーニングに必要なフィールドをデータセットからすばやく選択できます。

-
データセットの列への値の補填
Data CleaningのFill Columns ノードを使用すると、特定の条件に基づいて列の値を簡単に補填できます。要件に応じて、null値または非null値を補填できます。「EstimatedSalary」と「Balance」の列については、空の値をカスタム値「0」で置き換えます。
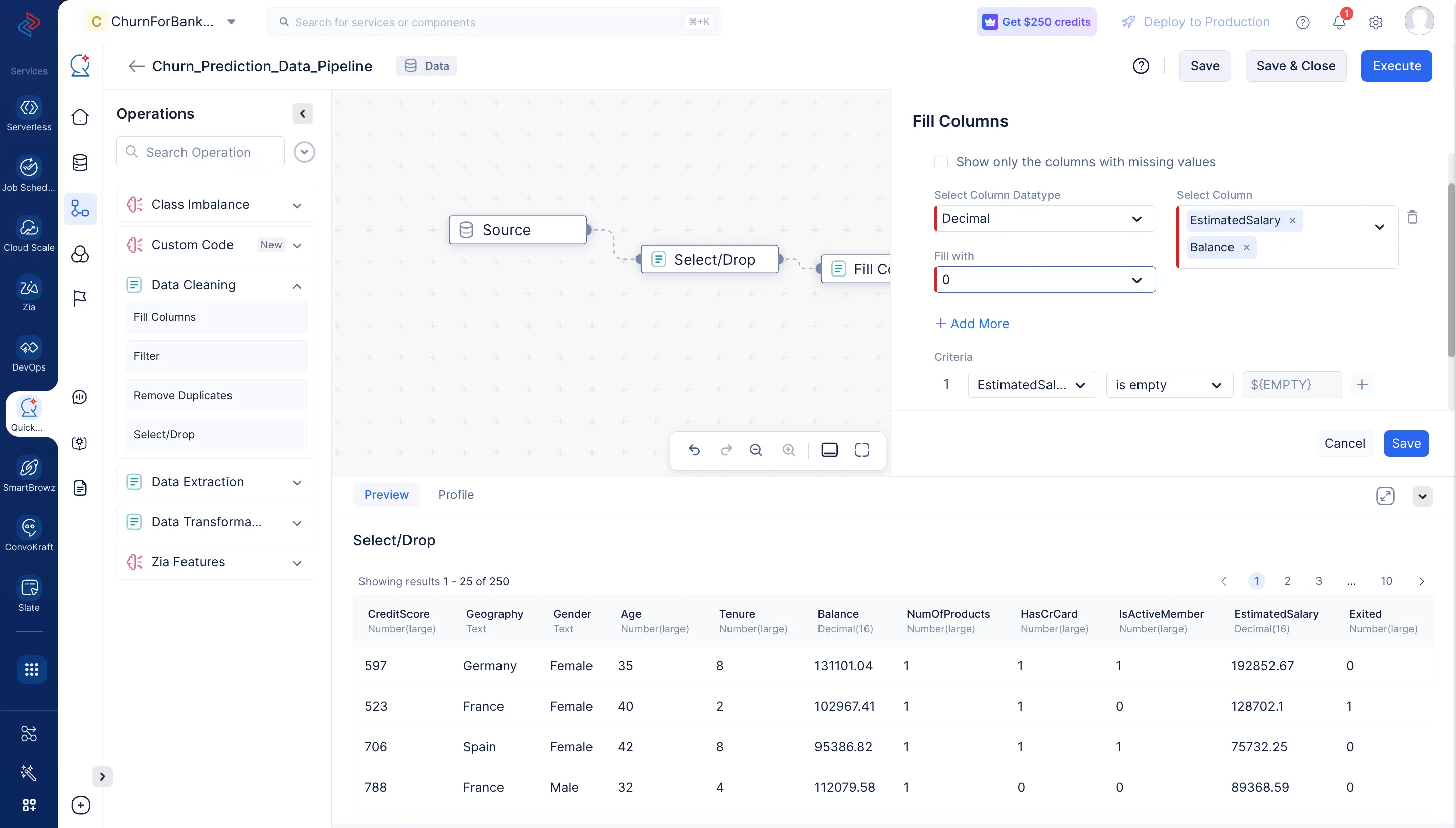
-
データのフィルタリング
データセットのフィルタリングとは、特定の条件を満たす行のサブセットをDataFrameから選択することを意味します。ここでは、Data CleaningセッションのFilterノードを使用して、「CreditScore」、「Geography」、「Gender」、「Age」、「Tenure」、「Exited」のすべての列で空でない値を持つデータをフィルタリングします。Data CleaningセッションのFilter ノードを使用します。
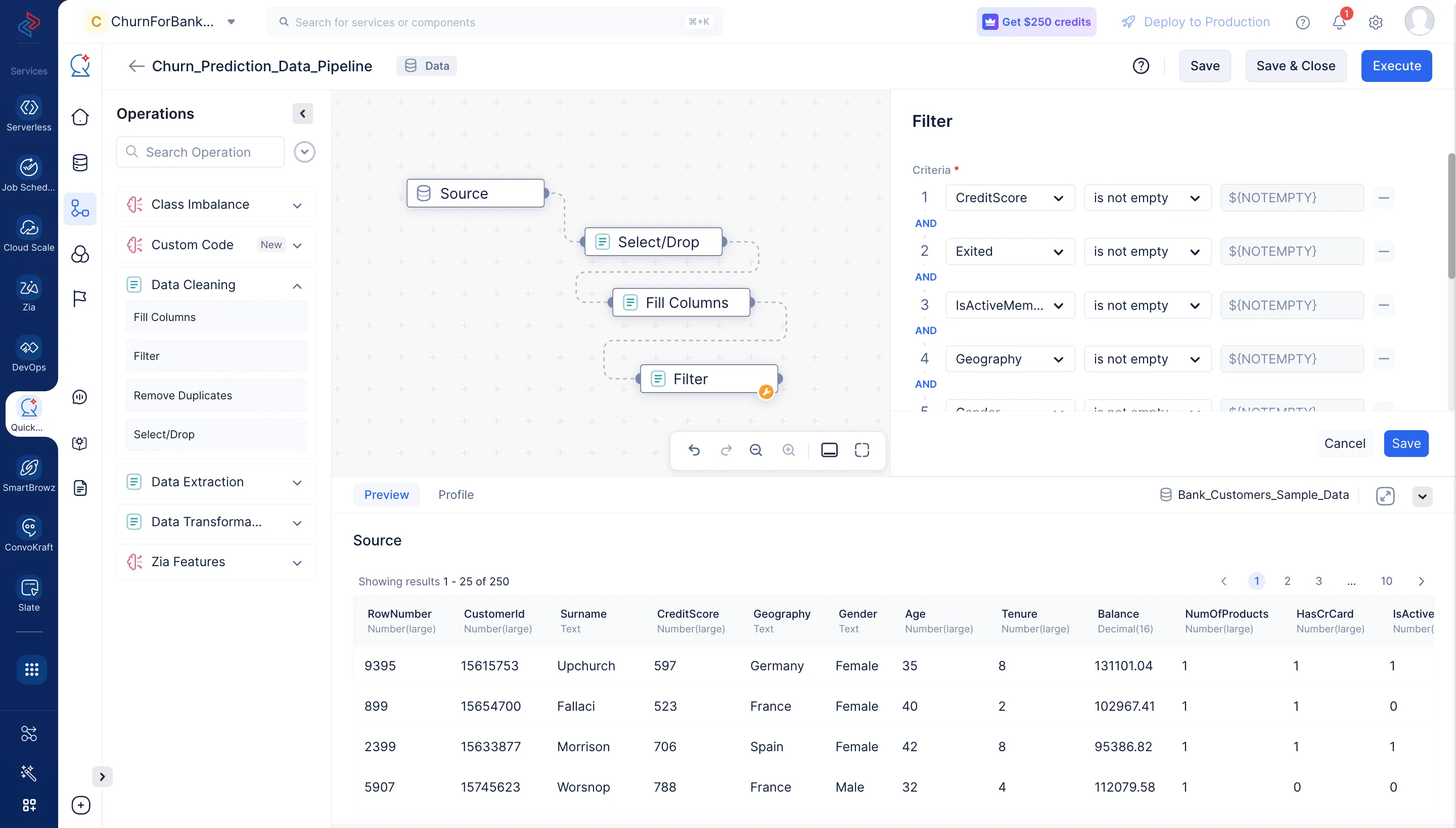
-
保存と実行
すべてのノードが接続されたら、Saveボタンをクリックしてパイプラインを保存します。次に、Executeボタンをクリックしてパイプラインを実行します。

下記のページにリダイレクトされ、実行ステータスとともに実行済みのパイプラインが表示されます。パイプラインの実行が成功したことを確認できます。
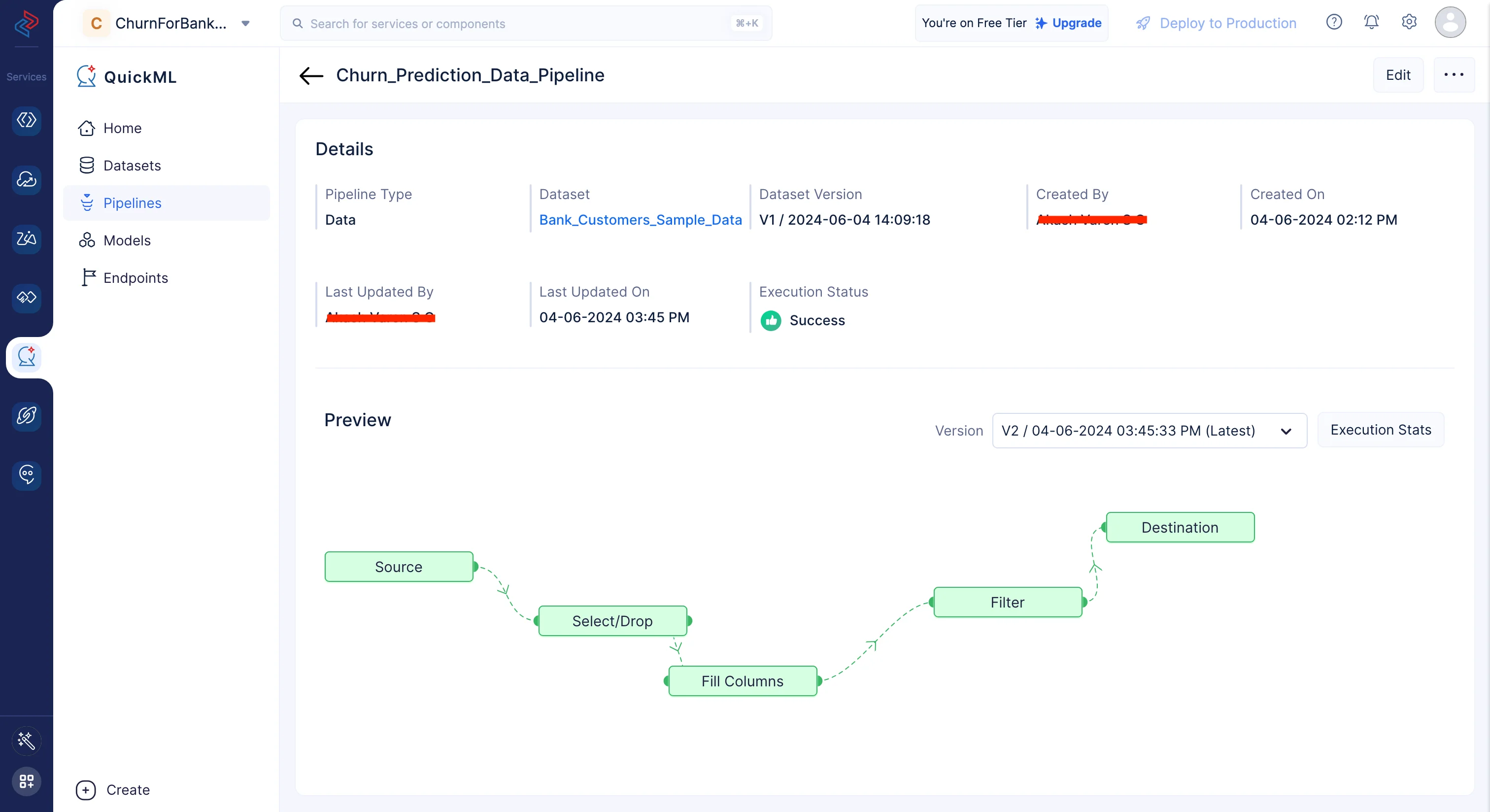
Execution Statsをクリックすると、下記のようにコンピューティング使用量に関する詳細情報を確認できます。

このパートでは、QuickMLを使用したデータ処理の方法を確認しました。機械学習モデルの作成に向けてデータを準備するためのさまざまな効果的な方法を紹介しました。このデータパイプラインは、Catalystプロジェクト内のさまざまなユースケースに対して、複数のML実験を作成するために再利用できます。
最終更新日 2026-03-05 11:43:24 +0530 IST