MLパイプラインの作成
予測モデルを構築するために、前処理済みのデータセットをMLパイプラインビルダーで使用します。MLパイプラインの構築における最初のステップは、予測対象となるターゲット列を選択することです。
MLパイプラインを作成するには、まずPipelinesコンポーネントに移動し、Create Pipelineオプションをクリックします。
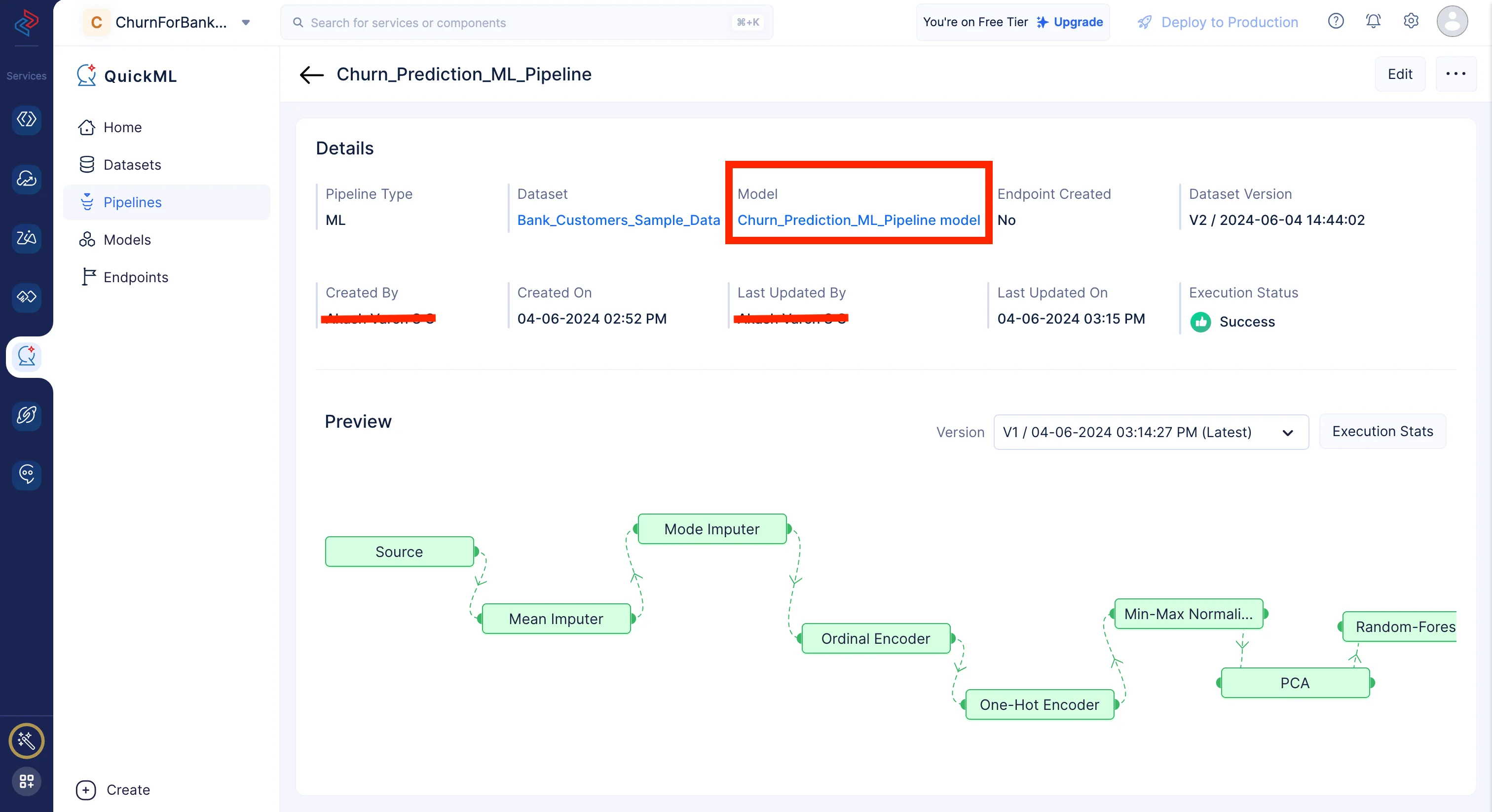
表示されるポップアップで、パイプラインタイプとしてPredictionを選択し、パイプライン名を入力します。ここではパイプライン名をChurn_Prediction_ML_Pipeline、モデル名をChurn_Prediction_ML_Pipeline Modelとします。次に、適切なデータセットとターゲットの列名を選択します。
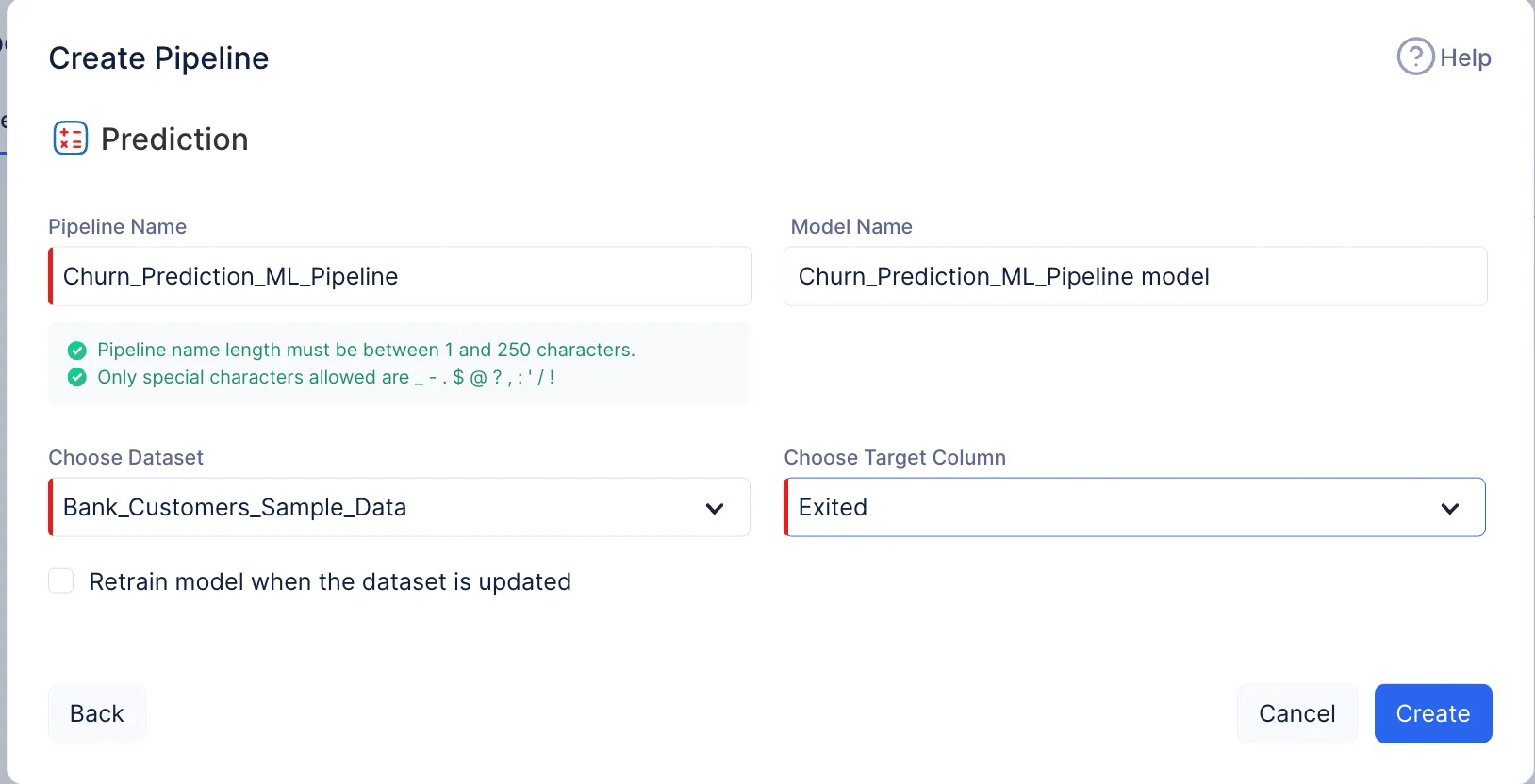
データパイプラインの構築用に選択したソースデータセットを選択する必要があります。前処理済みのデータはソースデータセットに反映されるためです。今回は、前処理とクリーニング用に選択したBank_Customers_Sample_Dataデータセットをインポートし、ターゲットはExitedという列名を使用します。
-
Imputers
Imputerは、データ分析、統計、機械学習などの分野で、欠損データや不完全なデータを処理するために使用されます。ここでは、ML operations > Imputers > Mean ImputerからインポートしたMean Imputer(平均値補完)を使用して、データセット内の欠損値を補完します。 Mean Imputing(平均値補完)とMode Imputing(最頻値補完)は、選択した列の平均値または最頻値に基づいて欠損値を補填するデータ補完手法です。
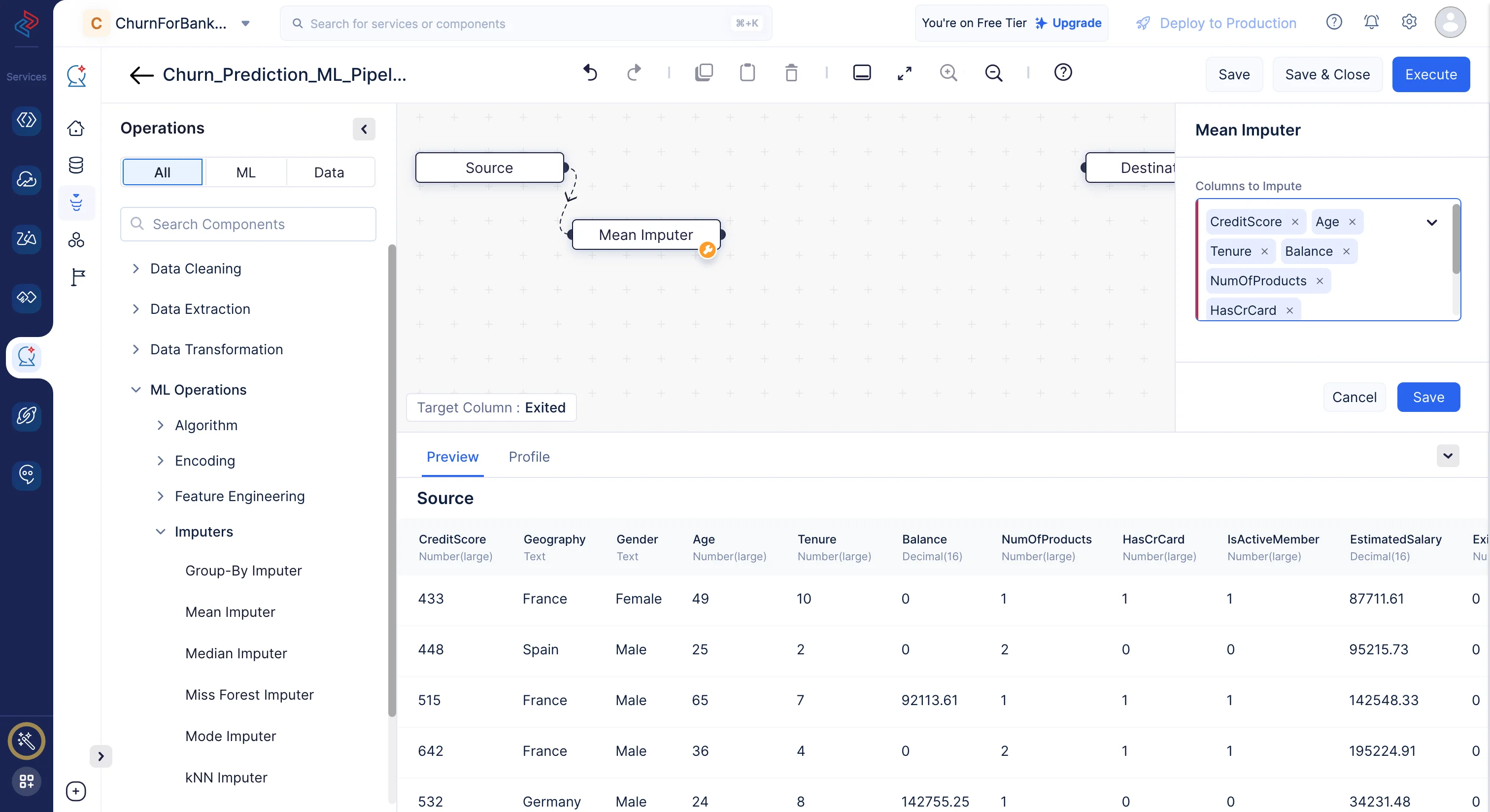
ここでは、最適なモデル予測のために空の値を含むべきでない列として、「CreditScore」、「Age」、「Tenure」、「Balance」、「NumOfProducts」、「HasCrCard」、「IsActiveMember」、「EstimatedSalary」をそれぞれの平均値で補完し、「Gender」、「Geography」の列は最頻値で補完します。
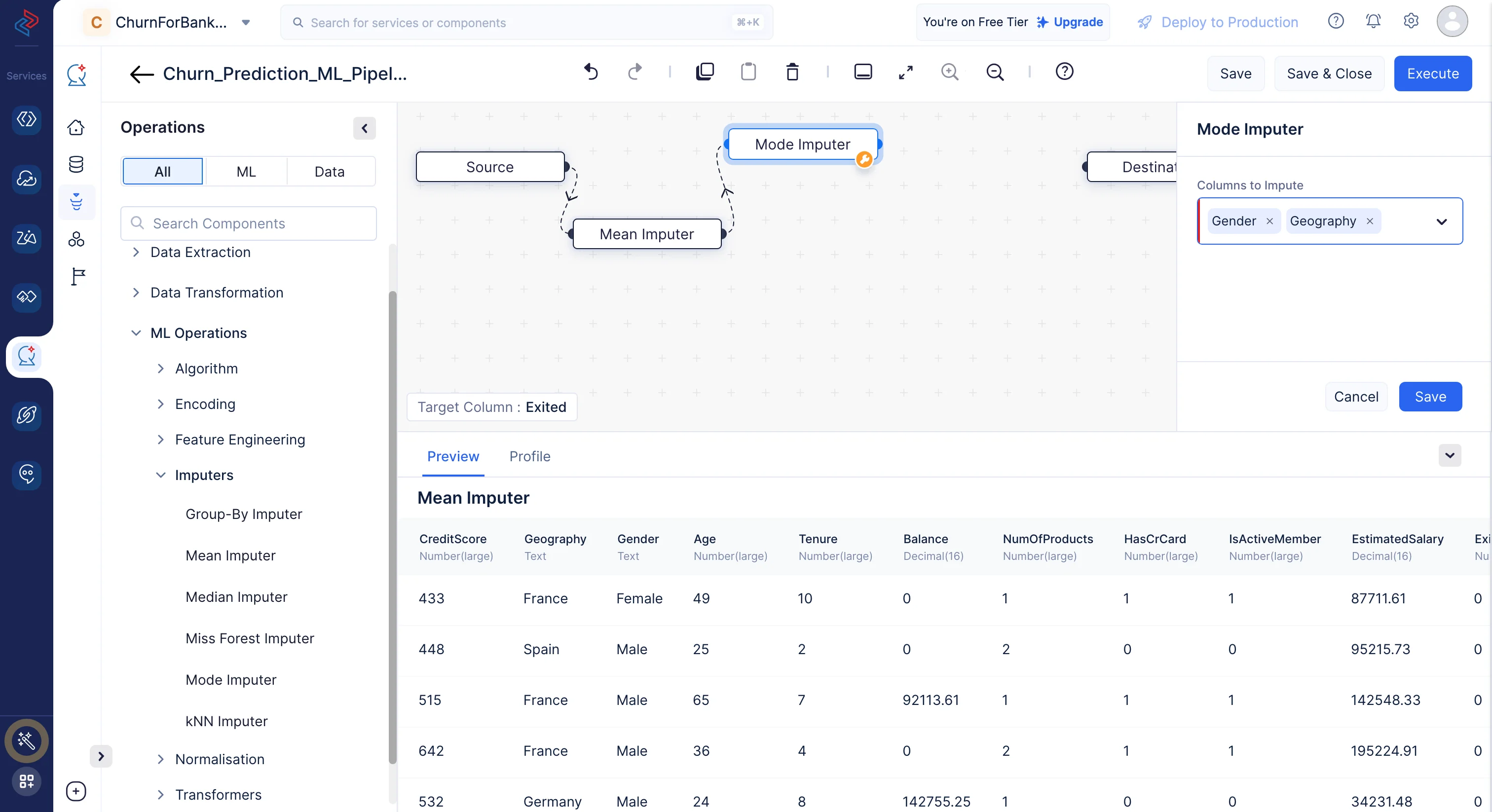
-
Encoding
エンコーダーは、カテゴリカルデータや非数値データを、機械学習アルゴリズムが効果的に処理できる数値形式に変換するために、さまざまなデータ前処理や機械学習タスクで使用されます。
順序エンコーディング
ここでは、順序エンコーディングを使用して、カテゴリカル特徴量「gender」をエンコードします。カテゴリに順序に基づいて整数を割り当てることで、機械学習アルゴリズムがデータの順序的な性質を捉えることが可能になります。QuickMLでOrdinal Encoderノードを使用するには、ML operationsに移動し、->Encoding componentをクリックして、-> Ordinal Encoderを選択し、選択したカテゴリ列を数値列に変換します。
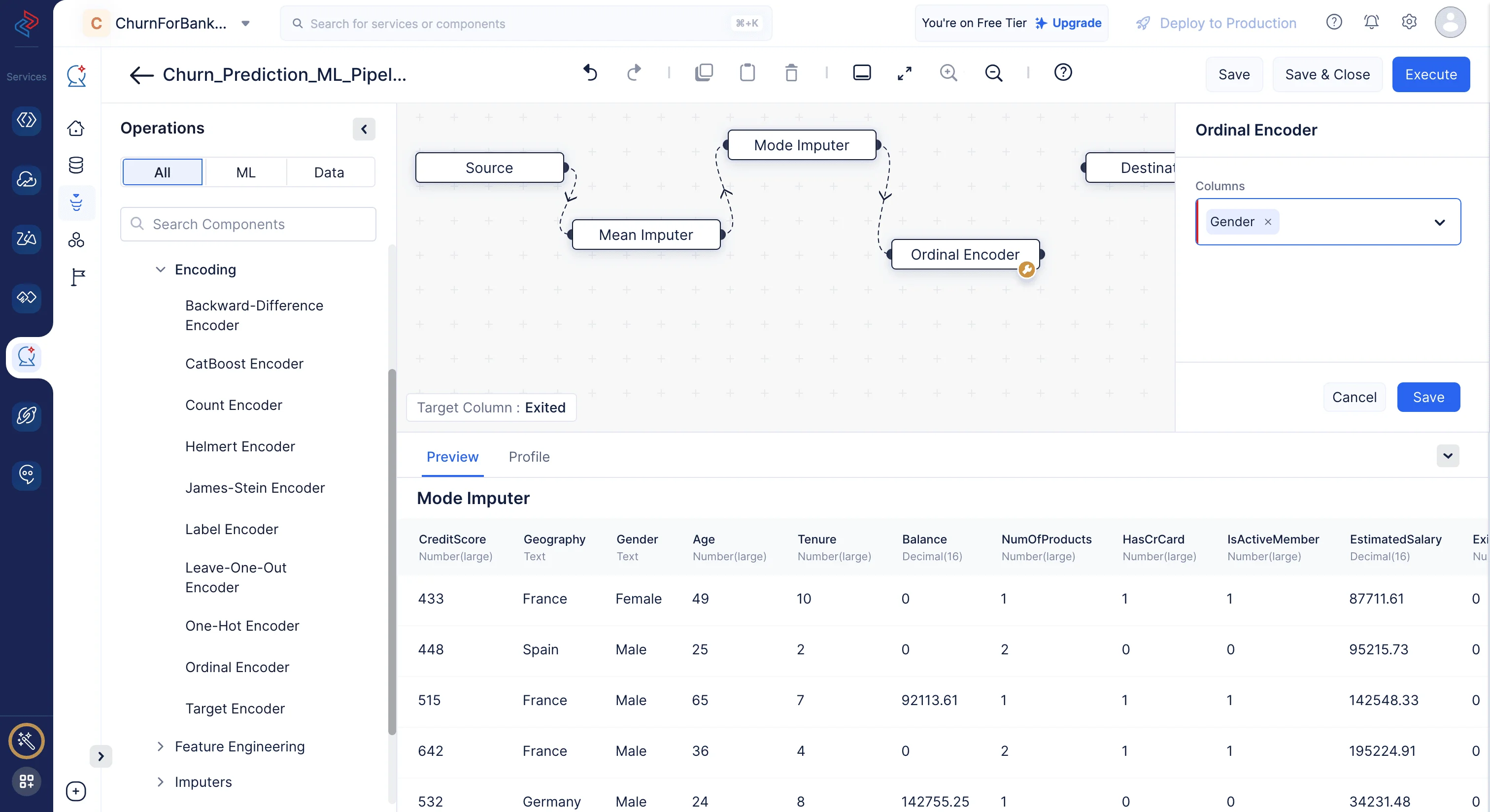
Ordinal Encoder
Ordinal Encodingは、各一意のラベルを整数値にマッピングする手法です。このタイプのエンコーディングは、カテゴリ間に既知の関係がある場合にのみ適しています。データに順序性がある場合は、順序エンコーディングを使用できます。
ここでは、Ordinal Encoderノードを使用してGender列をエンコードします。QuickMLのML Operations > Encoding > Ordinal EncoderからOrdinal Encoderノードを使用して、カテゴリ列を数値列に変換できます。ここでは、モデルトレーニングのために列の元の順序とデータを保持しつつ、すべてのカテゴリ列を数値形式に変換しています。
-
One-hotエンコーディング
One-hotエンコーディングは、データセット内のカテゴリ列に適用される手法で、各カテゴリは個別のクラスまたはグループを表します。この手法は、一意のカテゴリごとに新しいバイナリ列を作成するため、通常データセットの次元数が増加します。バイナリ列の数は、一意のカテゴリ数から1を引いた数に等しくなります。これは、他のすべてのカテゴリが存在しないことから最後のカテゴリの存在を推測できるためです。
ここでは、One-Hot Encoderノードを使用して、「Geography」列をエンコードします。QuickMLでML operationsに移動し、-> Encodingコンポーネントを選択して、-> One-Hot Encoderを選択し、選択したカテゴリ列を数値列に変換します。
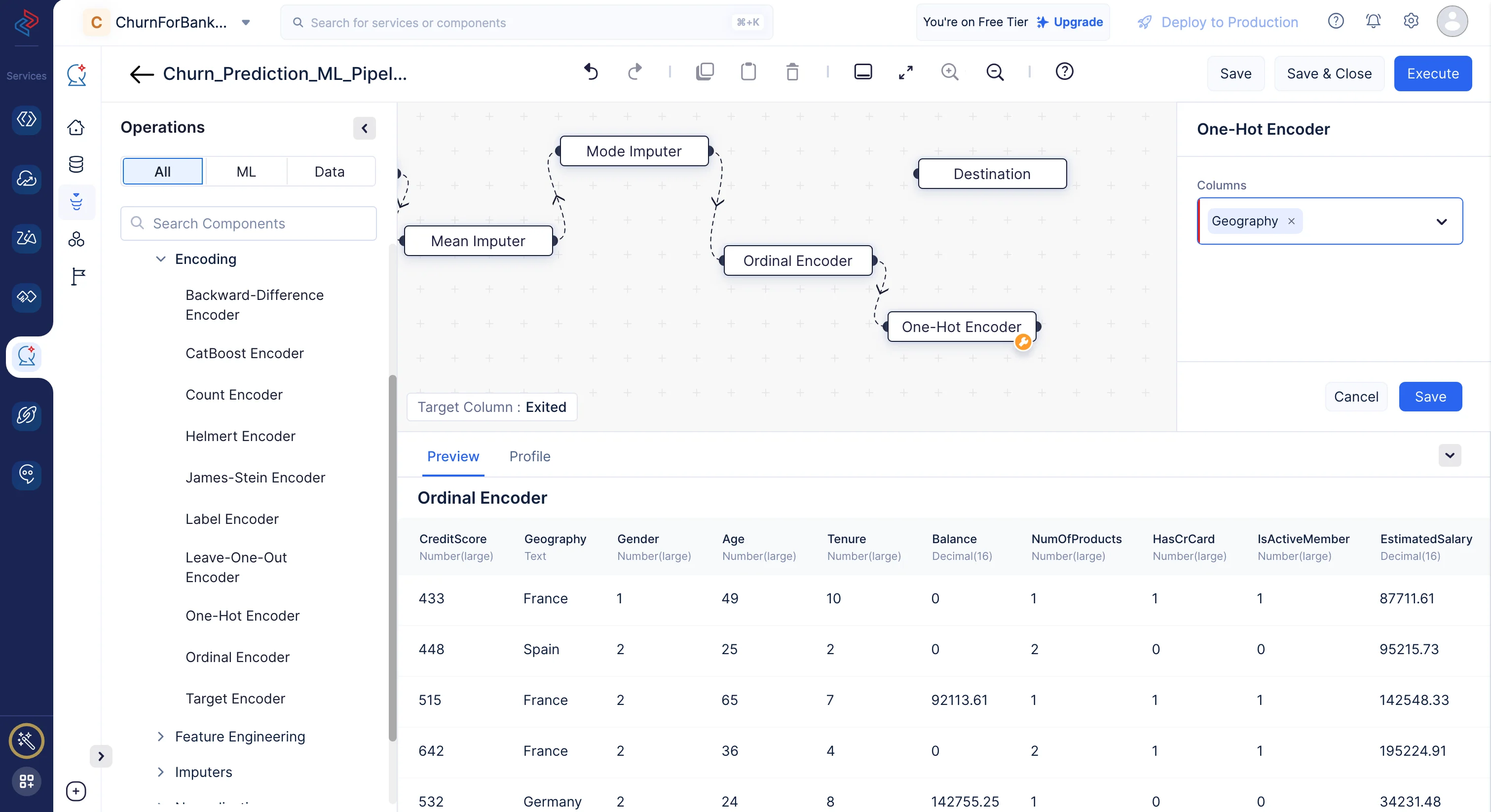
-
列の正規化
ML operations-> Normalizationに移動します。Min-Max Normalization ノードをMLパイプラインビルダーインターフェースにドラッグ&ドロップします。右パネルの設定ボックスで、ターゲットであるExitedを除くすべての列を選択し、Saveをクリックします。
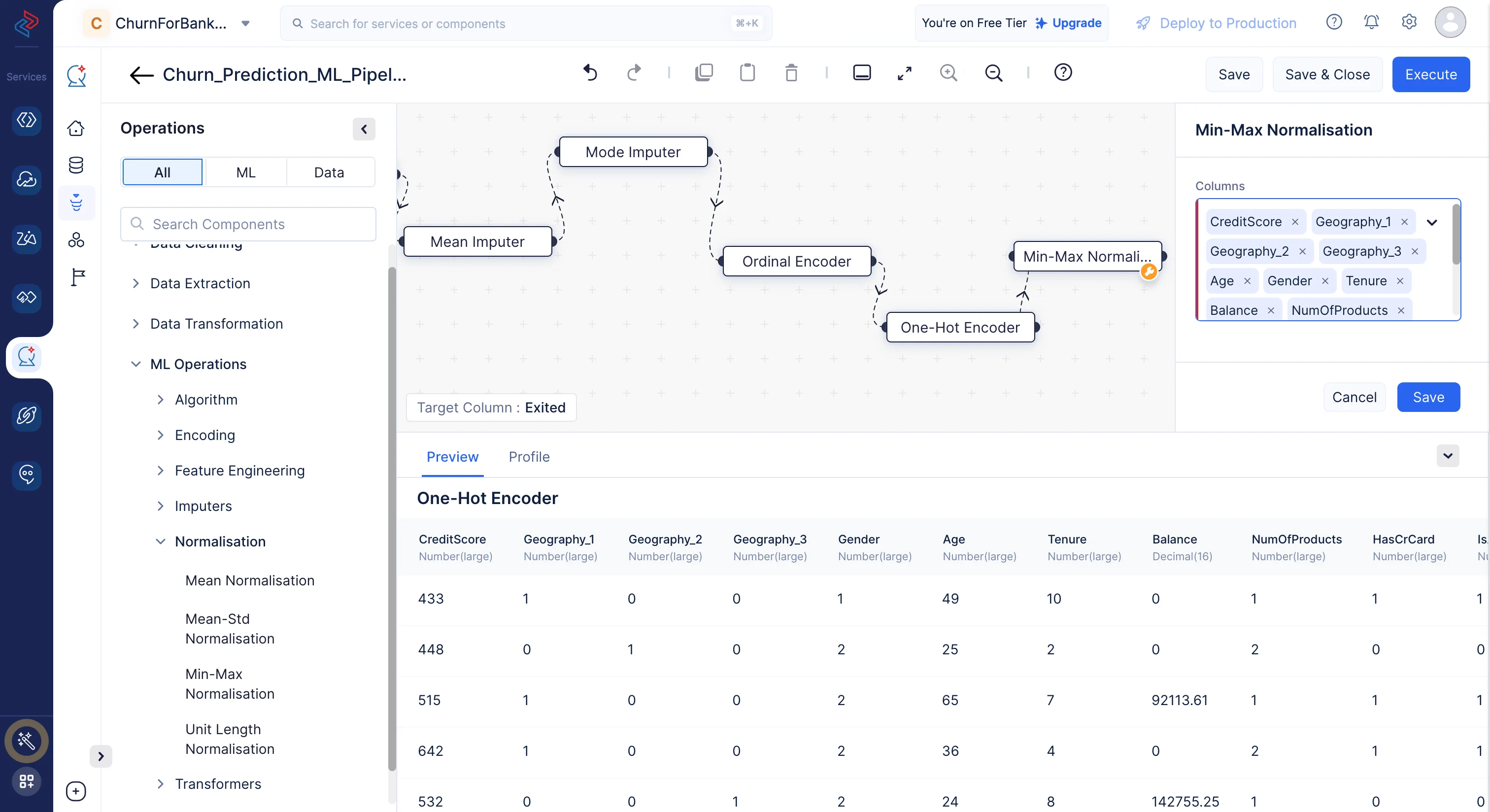
-
特徴量エンジニアリング:
特徴量選択は、モデルのトレーニングと分析に使用するために、データセットから最も関連性が高く重要な特徴量(変数または列)のサブセットを選択するプロセスです。特徴量選択の目的は、機械学習モデルの性能、効率、解釈可能性を向上させることです。特徴量選択は、高次元データセットを扱う場合に特に重要であり、過学習の軽減、計算時間の短縮、モデルの解釈性の向上に役立ちます。
ここでは、PCA 特徴量選択手法を使用して特徴量を生成します。ML operationsに移動し、->Feature Engineeringをクリックして、->Feature Reductionを選択し、PCAノードを選択します。
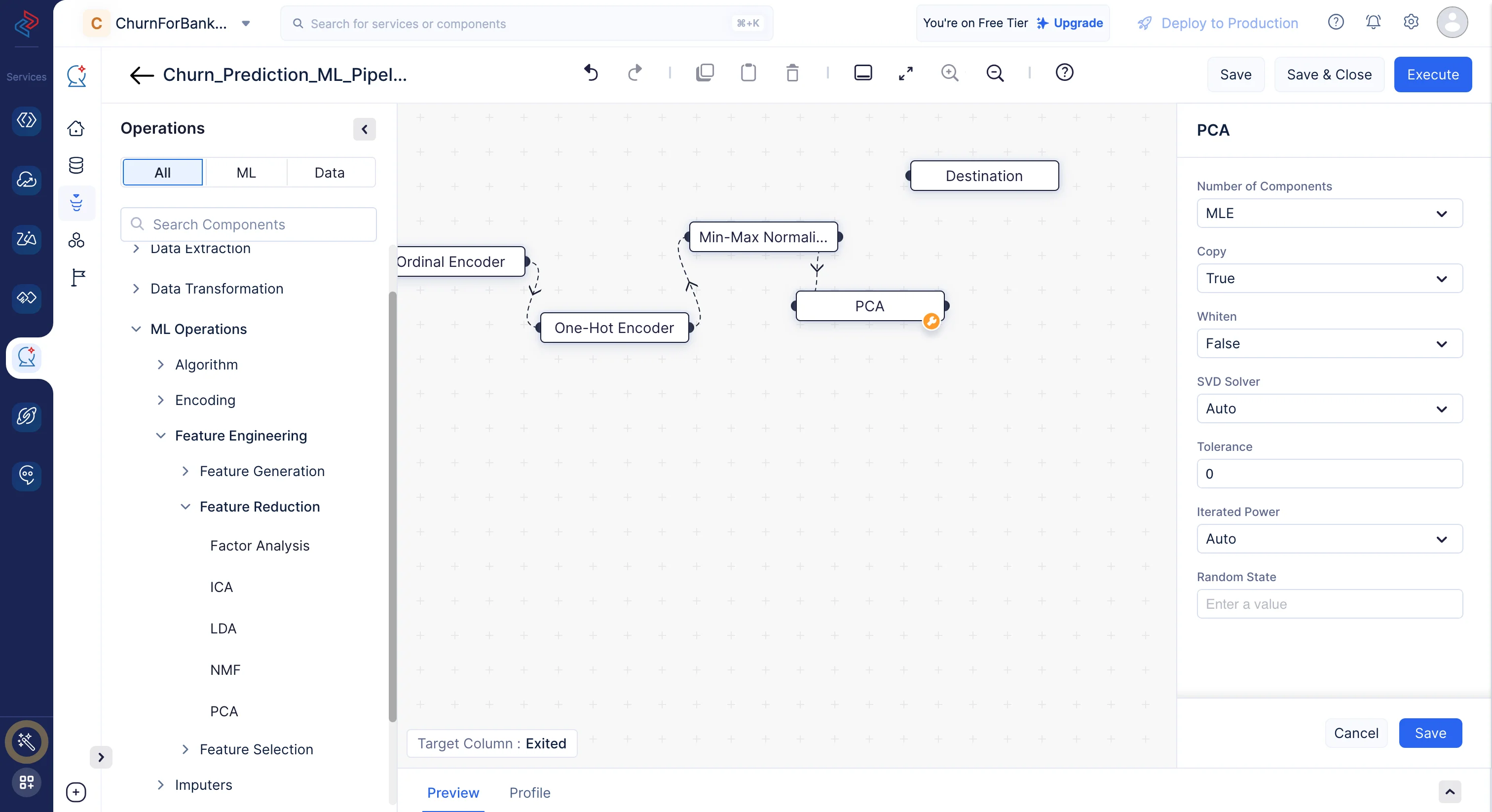
-
MLアルゴリズム:
MLパイプライン構築の次のステップは、前処理済みデータのトレーニングに適切なアルゴリズムを選択することです。ここでは、Random-Forest Classificationを使用してデータをトレーニングします。
特定のデータセットに対してモデルを最適化するために、チューニングパラメータを調整することもできます。今回はデフォルト設定のまま使用します。ML operationsに移動し、->Algorithmsをクリックして、->Classificationを選択し、Random-Forest Classificationノードを選択します。すべての設定が完了したら、パイプラインを保存して、さらなるテストとデプロイに進むことができます。

アルゴリズムノードをドラッグ&ドロップすると、そのエンドノードは自動的に宛先ノードに接続されます。Saveをクリックしてパイプラインを保存し、パイプラインビルダーページの右上にあるExecuteボタンをクリックしてパイプラインを実行します。
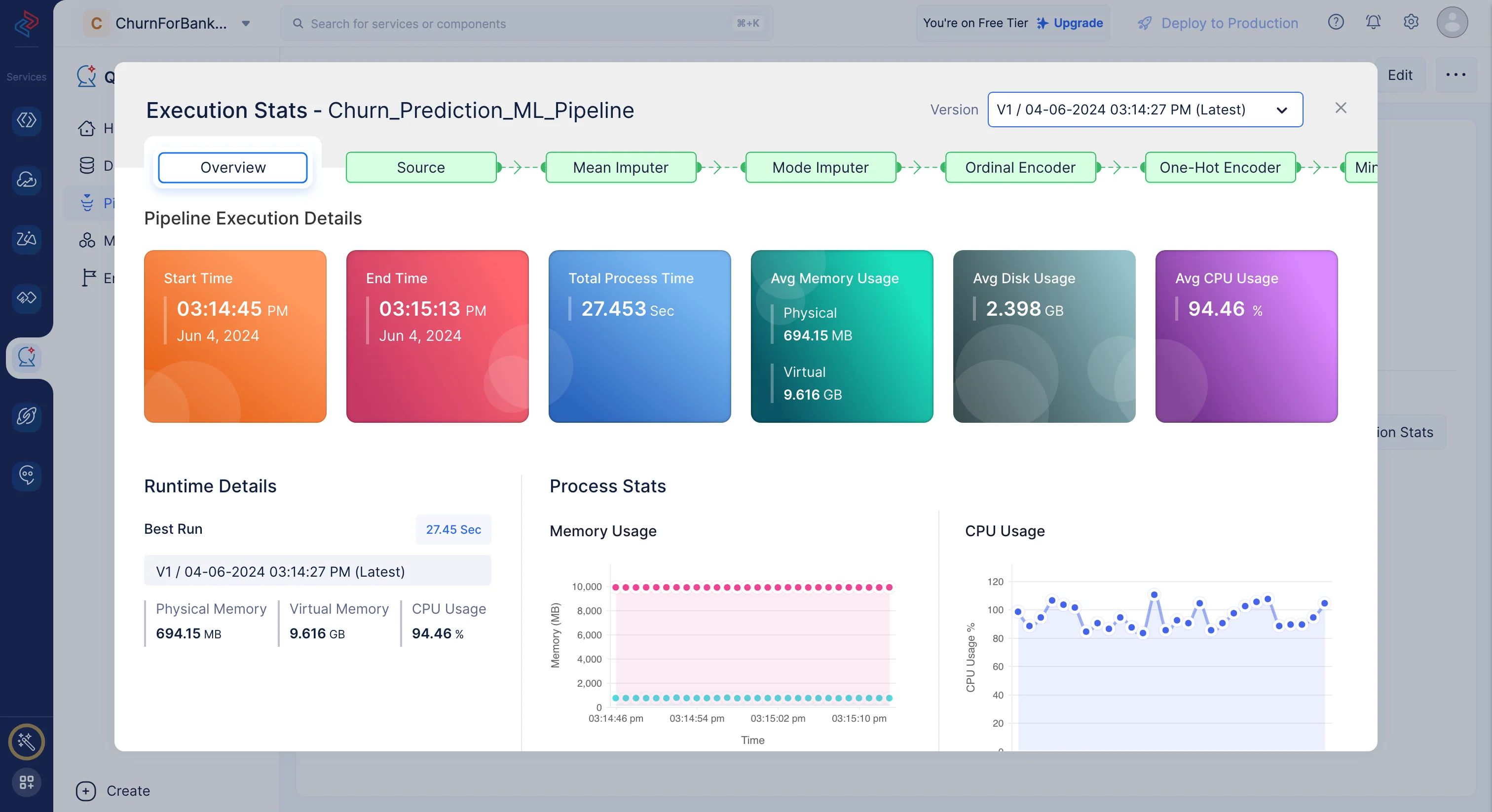
下記のページにリダイレクトされ、実行ステータスとともに実行済みのパイプラインが表示されます。パイプラインの実行が成功したことを確認できます。

Execution Statsをクリックすると、モデル実行の各ステージに関するコンピューティングの詳細を確認できます。
MLワークフローが正常に完了すると、予測モデルが作成され、Modelセクション(Churn_Prediction_ML_Pipeline Modelをクリック)で確認できます。
これにより、データに基づいた予測を行う際のモデルの効率と性能に関する有用な知見が得られます。

最終更新日 2026-03-05 11:43:24 +0530 IST