Crear un ML pipeline
Para construir el modelo de predicción, usaremos el dataset preprocesado en el ML Pipeline Builder. El paso inicial en la construcción del ML Pipeline involucra seleccionar la columna objetivo, que es la columna que estamos intentando predecir.
Para crear un ML pipeline, primero navega al componente Pipelines y haz clic en la opción Create Pipeline.
En el pop-up que aparece, selecciona Prediction como tipo de pipeline y proporciona el nombre del pipeline, nombraremos el pipeline como Fraud Detection ML pipeline y el modelo Fraud Detection ML pipeline Model en el pop-up de Create Pipeline. Luego, selecciona el dataset apropiado y el nombre de la columna del objetivo.
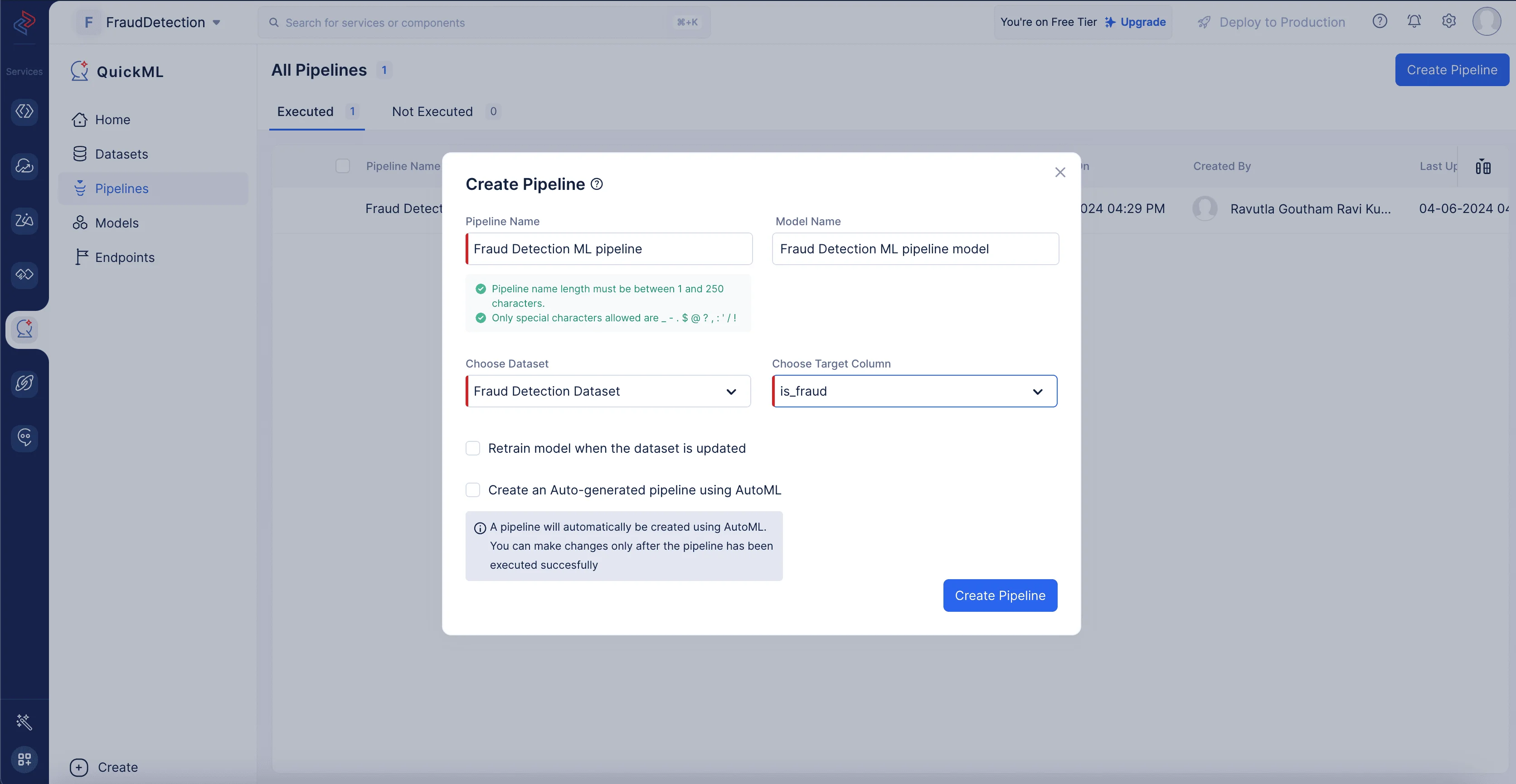
Necesitamos seleccionar el dataset fuente que fue elegido para construir el data pipeline, ya que los datos preprocesados se reflejan en el dataset fuente. En nuestro caso, importaremos el dataset Fraud Detection Dataset, ya que lo seleccionamos para preprocesamiento y limpieza, y nuestro objetivo es la columna llamada is_fraud.
-
Normalizar las columnas
Dado que los valores de las características “amt”, “city_pop”, “age” están en varios rangos, usaremos el componente Mean-Std Normalization para escalar los valores de las características a un rango común, típicamente entre 0 y 1. Navega a ML operations->Normalization. Arrastra y suelta el nodo Mean-Std Normalization en la interfaz del ML pipeline builder. En el cuadro de configuración del panel derecho, elige todas las columnas excepto “is_fraud” y haz clic en Save.
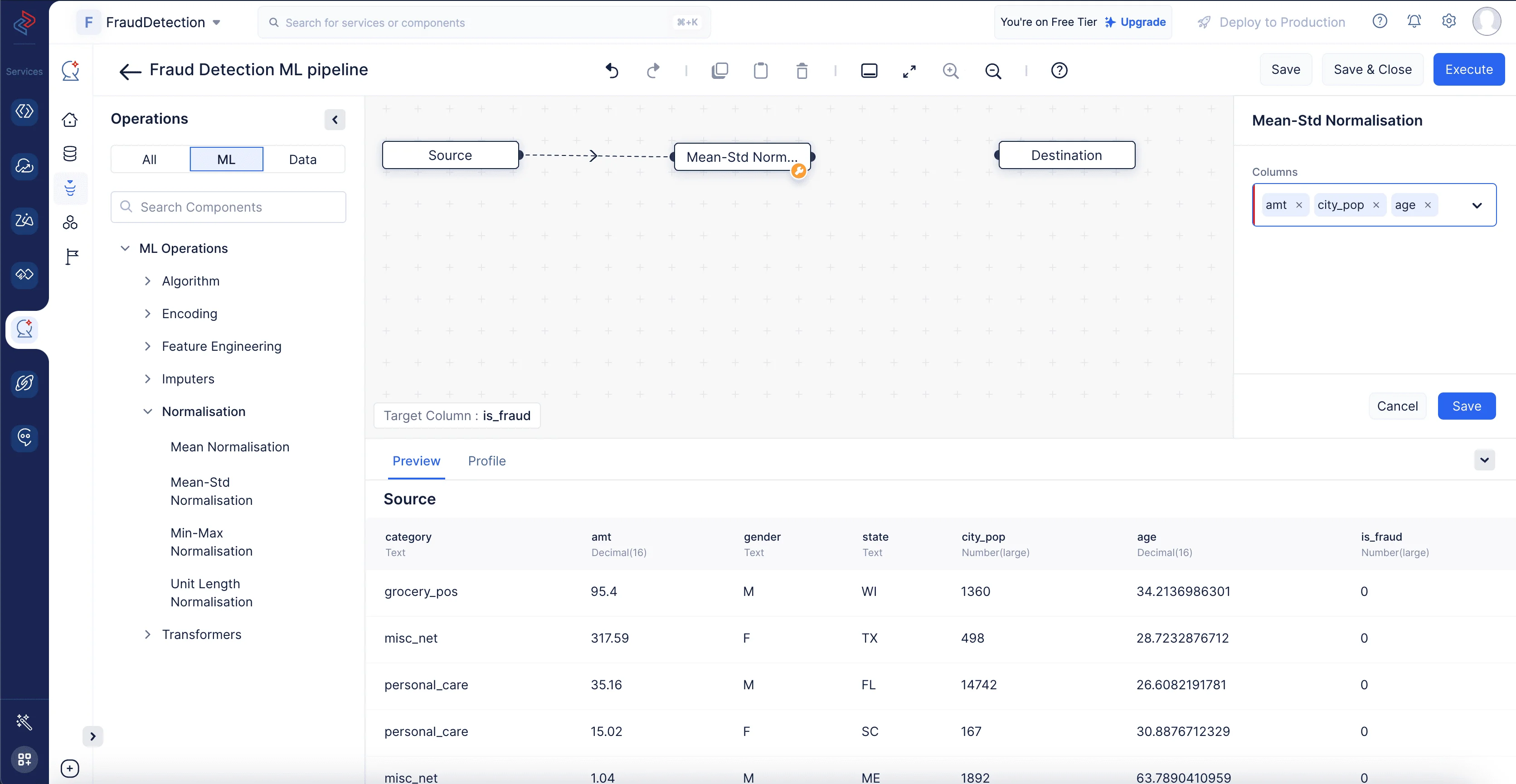
-
Codificar columnas categóricas
Los encoders se usan en diversas tareas de preprocesamiento de datos y aprendizaje automático para convertir datos categóricos o no numéricos en un formato numérico con el que los algoritmos de aprendizaje automático puedan trabajar efectivamente.
-
One-hot encoder
La codificación one-hot se aplica típicamente a columnas categóricas en un dataset, donde cada categoría representa una clase o grupo distinto. Este método típicamente incrementa la dimensionalidad del dataset porque crea una nueva columna binaria para cada categoría única. El número de columnas binarias es igual al número de categorías únicas menos una, ya que puedes inferir la presencia de la última categoría por la ausencia de todas las demás.
Aquí, estamos usando el nodo One-Hot Encoder para codificar las siguientes columnas: “category”, “gender” y “state”. Usaremos el nodo One-Hot Encoder navegando a ML operations, seleccionando el componente -> Encoding y eligiendo -> One-Hot Encoder en QuickML para convertir las columnas de categoría seleccionadas en columnas numéricas.
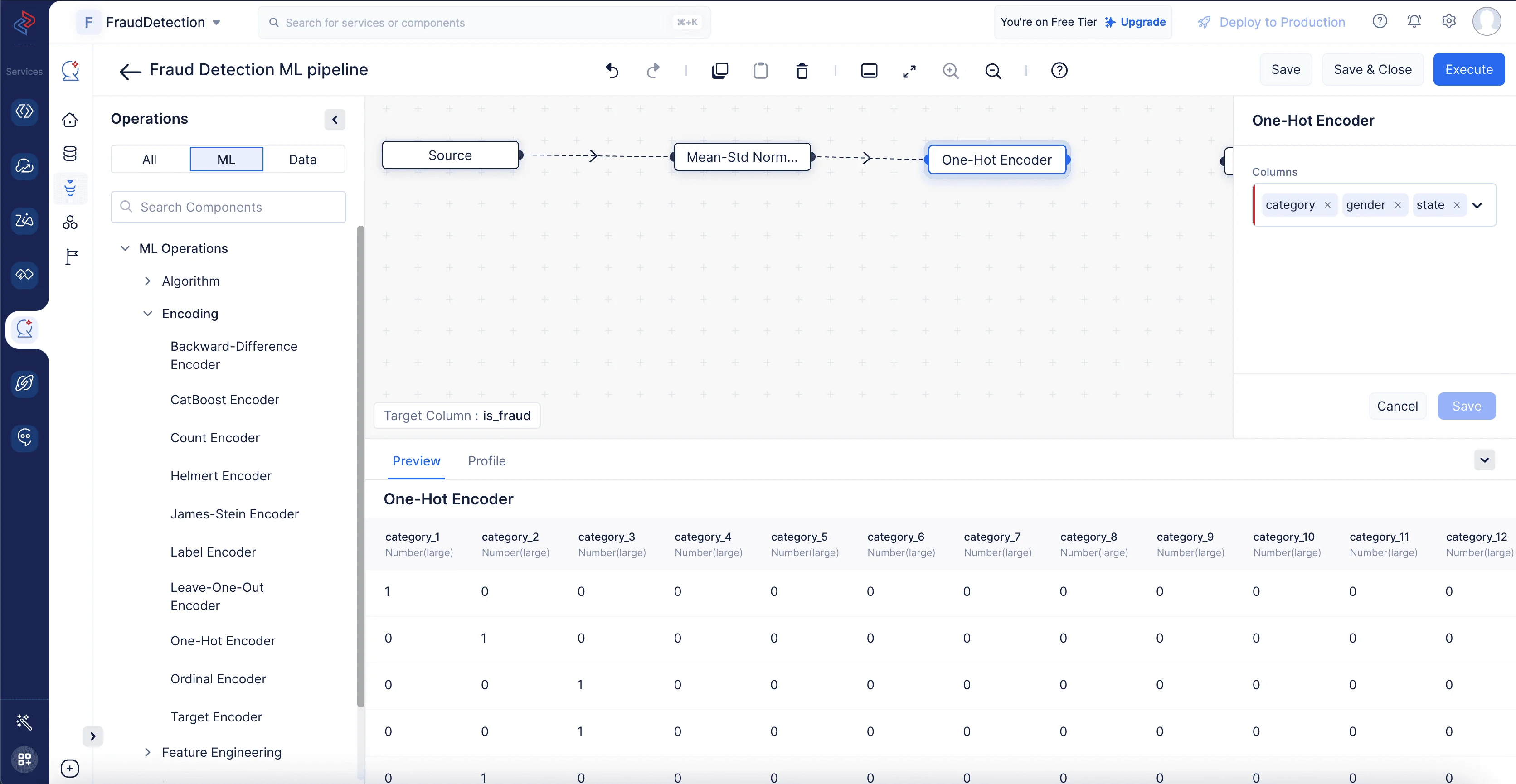
-
-
Algoritmo de ML:
El siguiente paso en la construcción del ML pipeline es seleccionar el algoritmo apropiado para entrenar los datos preprocesados. Aquí usaremos el algoritmo de clasificación XGBoost para entrenar los datos.
XGBoost (Extreme Gradient Boosting) es un algoritmo de aprendizaje automático popular y poderoso comúnmente usado para tareas de clasificación. Es un método de aprendizaje por ensamble que combina las predicciones de múltiples árboles de decisión para crear un modelo predictivo fuerte. XGBoost es conocido por su velocidad, escalabilidad y capacidad para manejar datasets complejos.
Podemos construir rápidamente el método de clasificación XGBoost en el ML Pipeline Builder de QuickML arrastrando y soltando el nodo XGBoost Classification relevante desde ML operations, seleccionando ->Algorithm, haciendo clic en ->Classification, y eligiendo ->XGBoost Classification.
Para asegurarnos de que el modelo esté optimizado para nuestro dataset particular, también podemos ajustar los parámetros de ajuste; en nuestro caso, podemos simplemente mantener la configuración predeterminada. Cuando todo esté configurado, podemos guardar el pipeline para pruebas y despliegue posteriores.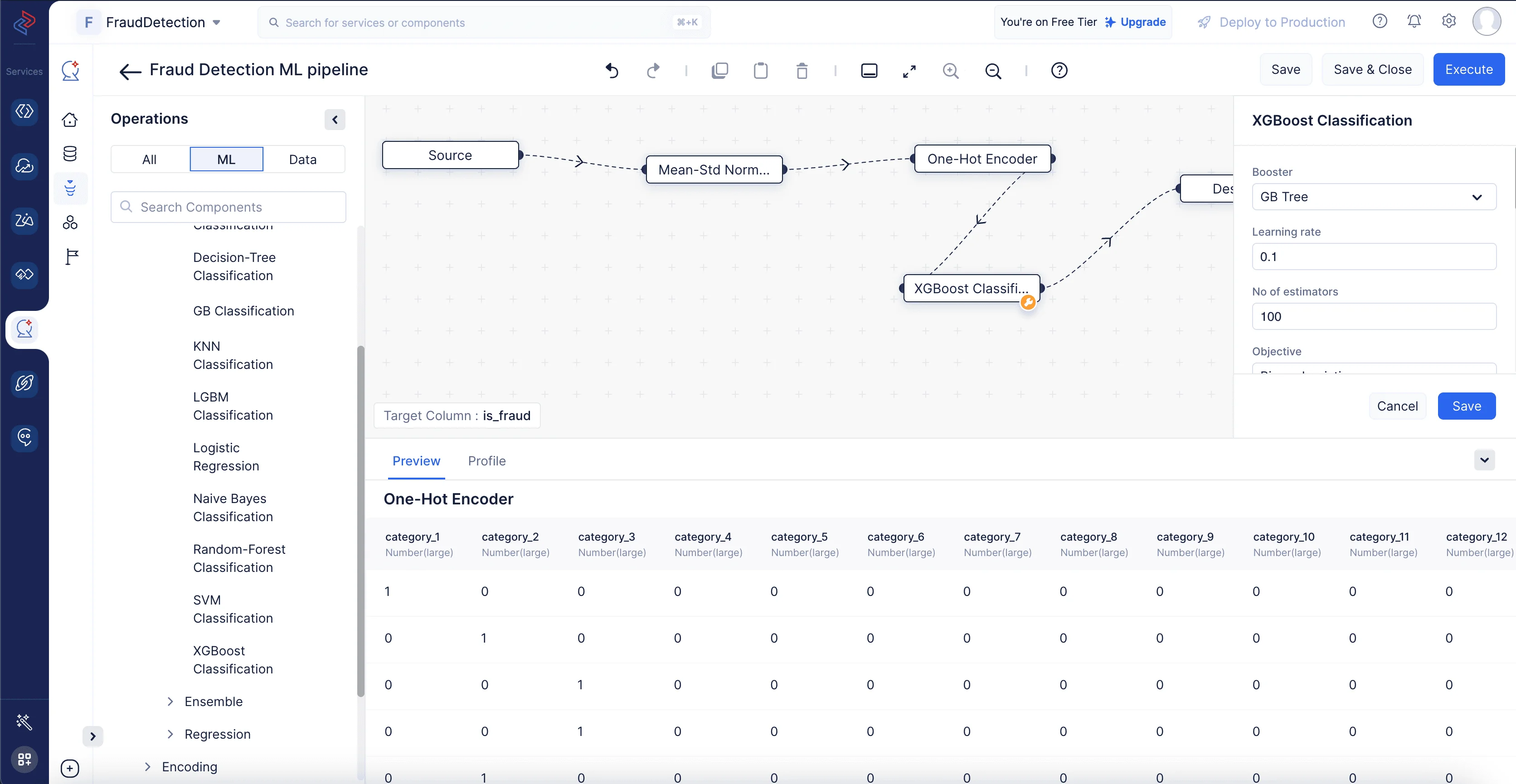
Una vez que arrastramos y soltamos el nodo del algoritmo, su nodo final se conectará automáticamente al nodo de destino. Haz clic en Save para guardar el pipeline y ejecuta el pipeline haciendo clic en el botón Execute en la esquina superior derecha de la página del pipeline builder. Esto te redirigirá a la página que se muestra a continuación, que muestra el pipeline ejecutado con el estado de ejecución. Podemos ver claramente aquí que la ejecución del pipeline fue exitosa.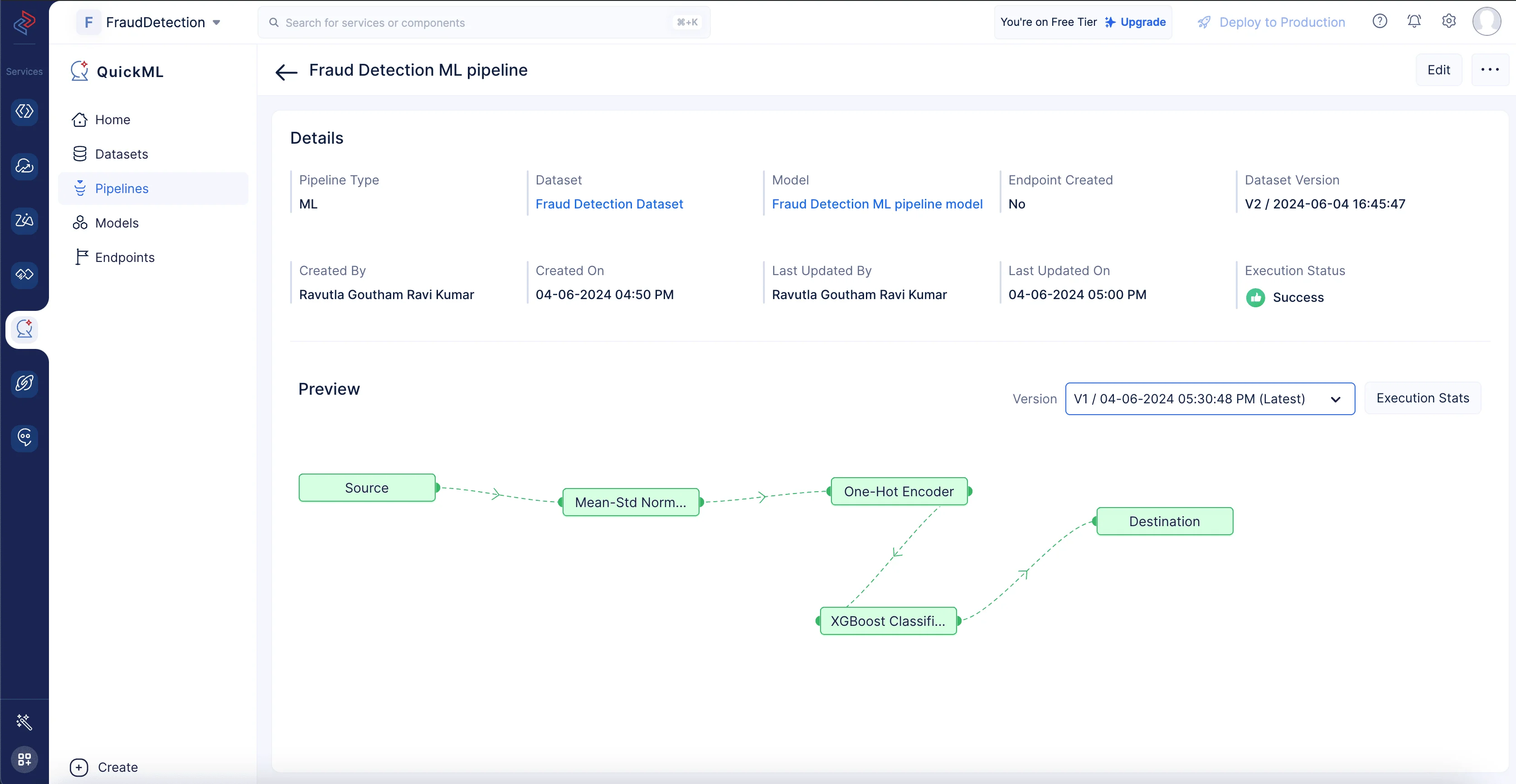
Haz clic en Execution Stats para ver más detalles de cómputo sobre cada etapa de la ejecución del modelo en detalle.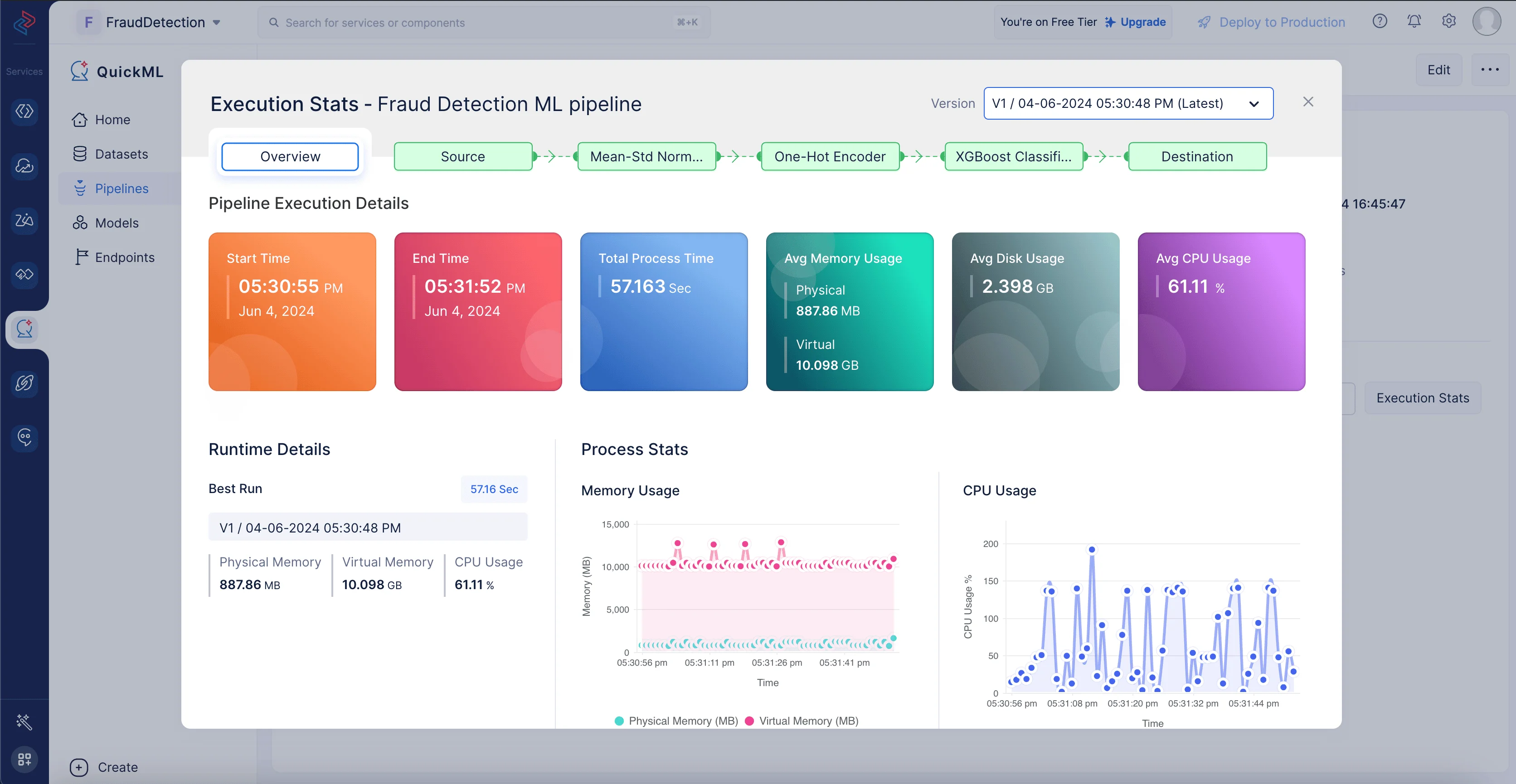
El modelo de predicción está creado y puede examinarse en la sección Model (haz clic en Fraud Detection ML pipeline model) tras la finalización exitosa del flujo de trabajo de ML.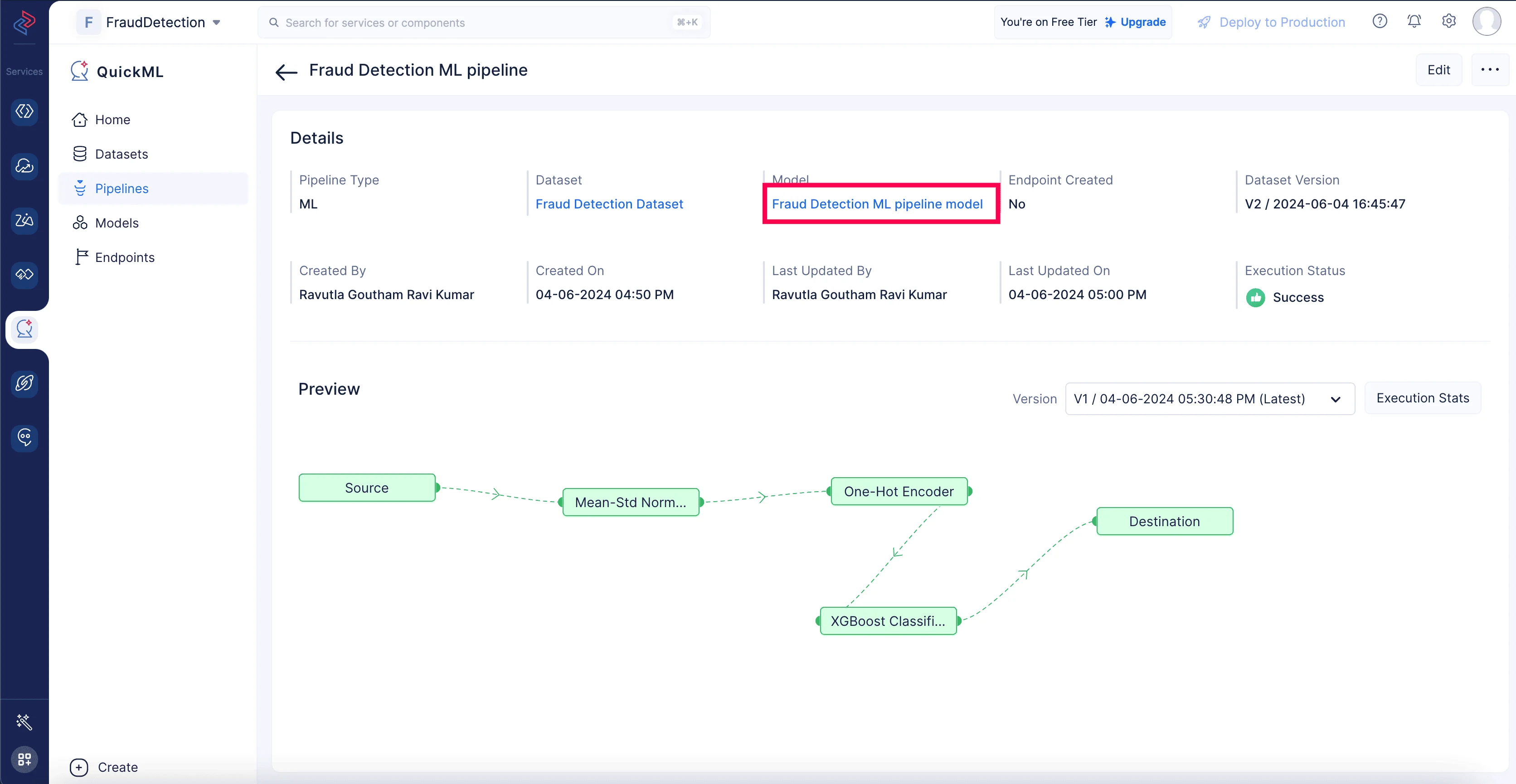
Esto ofrece percepciones útiles sobre la eficiencia y el rendimiento del modelo al hacer predicciones basadas en los datos.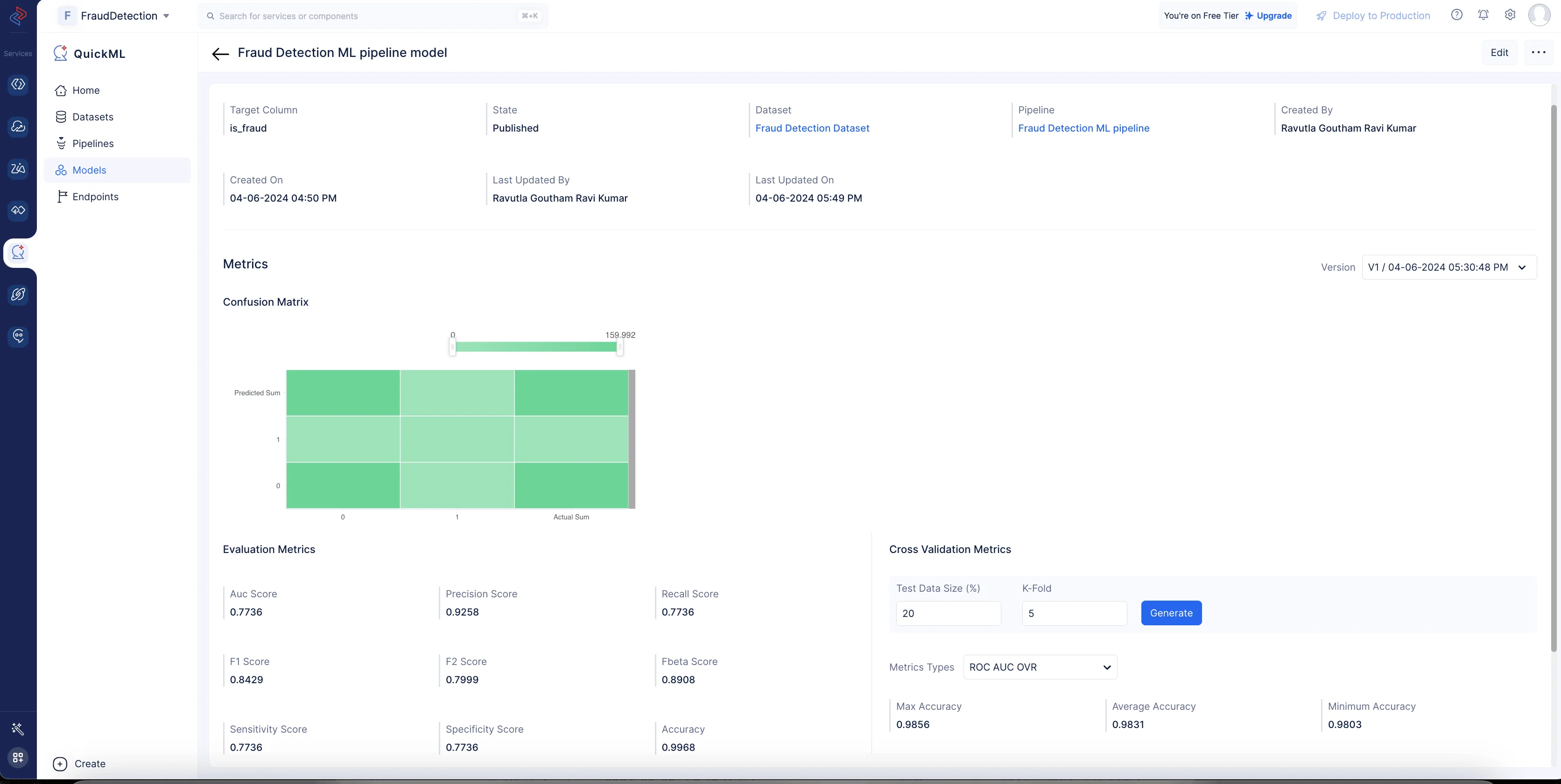
Última actualización 2026-03-20 21:51:56 +0530 IST