Once the dataset is uploaded proceed with the below steps.
- Create a pipeline using the Create Pipeline button in details Page.
- We will be redirected into pipeline builder page to preprocess the dataset.
- Drag and drop the operation node and configure.
- Make connection between nodes to execute the pipeline.
Data Preprocessing creation with QuickML:
In the field of data science, data preprocessing is a crucial step in the data analysis pipeline. It involves preparing the raw data for analysis by removing or modifying incorrect or irrelevant information. Data preprocessing is a fundamental task as the quality and accuracy of the data directly impact the effectiveness of the machine learning models built on top of it.
Data preprocessing can be a time-consuming and labor-intensive process. In fact, a significant portion of a data scientist’s time, approximately 45%, is dedicated to cleaning and preparing the data rather than working on the machine learning algorithms.
However, with the introduction of QuickML, data preprocessing becomes much more streamlined and efficient. QuickML offers a simple and intuitive drag and drop interface within the Data Pipeline Builder. This means that data scientists can easily preprocess the data using predefined tools and operations, saving them valuable time and effort.
Furthermore, QuickML provides additional functionalities such as data profiling and data preview within the Pipeline Builder. These features enable data scientists to analyze and understand the characteristics of the data, facilitating more effective preprocessing decisions. follow the below steps to complete the predataprocessing for CRM Deal Prediction.
1. Selecting Required Fields for Model Training:
In this step, we choose the relevant columns from the dataset that are essential for model training by using the select-drop node, we are selecting to drop the “Deal_ID” column for our model training. We ensure that the selected fields provide meaningful insights and contribute significantly to the predictive power of the machine learning model.

2. Filter the non-empty data alone for the required columns:
To enhance the quality of the data used for training, we filter out the non-empty data for the required columns using Filter node. This process helps in eliminating irrelevant or incomplete data, ensuring that only valuable information is used for model development. Since the “Won/Lost” is a important column for our model training we adding a filter for that columns to avoid empty cells. If you want to process the unmatched data from the filter, click Show unmatched records as secondary output to receive another output for unmatched data. In our case, we don’t need the unmatched data, so we are not selecting it.

3. Handling Missing Values in the Data:
By utilizing the Profiling feature in QuickML, we easily identify columns with missing values and efficiently replace them with desired values based on predefined conditions with help of Fill-column node. This step ensures that the dataset is complete and devoid of any missing information, thereby preventing potential biases in the model. In our dataset we are replacing the empty cells of “Amount (USD)” with custom value 0.
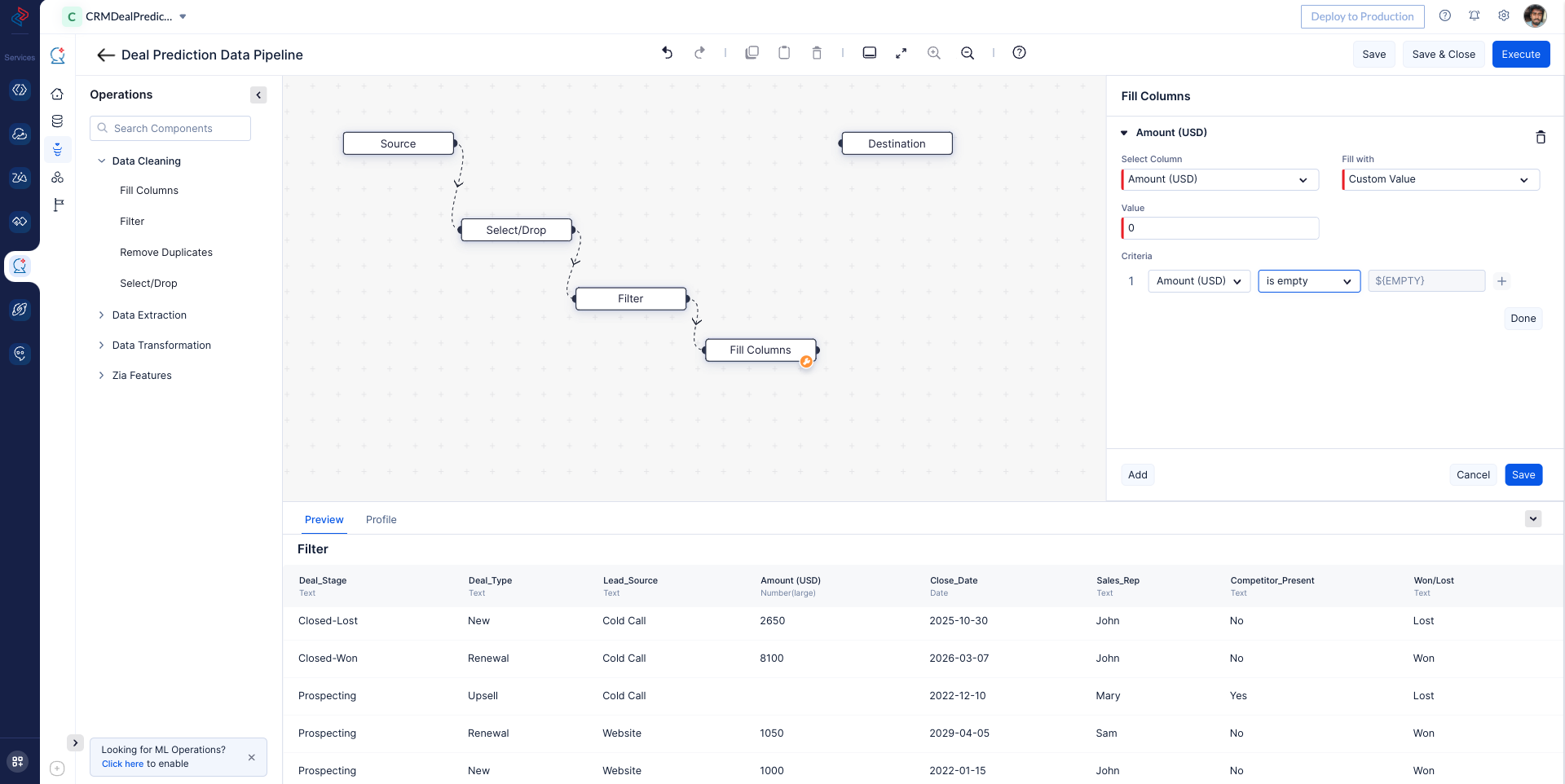
Once all the nodes are connected in the data pipeline, we can proceed to Save and Execute the pipeline.

Execute option will execute the Pipeline.

Upon successful pipeline execution, we can review the execution information for more insights into the preprocessing execution by clicking on Execution Stats.

With QuickML, we have effectively preprocessed the dataset without the need for any code implementation, streamlining the data preparation process for model training. This data pipeline what we craeted can be reused to create multiple ML experiments for our usecase going forward.
Last Updated 2023-09-07 11:29:42 +0530 +0530