Crear un pipeline de ML
Para construir el modelo de predicción, utilizaremos el conjunto de datos preprocesado en el ML Pipeline Builder. El paso inicial en la construcción del Pipeline de ML implica seleccionar la columna objetivo, que es la columna que estamos intentando predecir.
Para crear un pipeline de ML, primero navega al componente Pipelines y haz clic en la opción Create Pipeline.
En la ventana emergente que aparece, proporciona el nombre del pipeline; nombraremos el pipeline como Churn Prediction y el modelo Churn Prediction Model en la ventana emergente Create Pipeline. Luego, selecciona el conjunto de datos apropiado y el nombre de la columna objetivo.
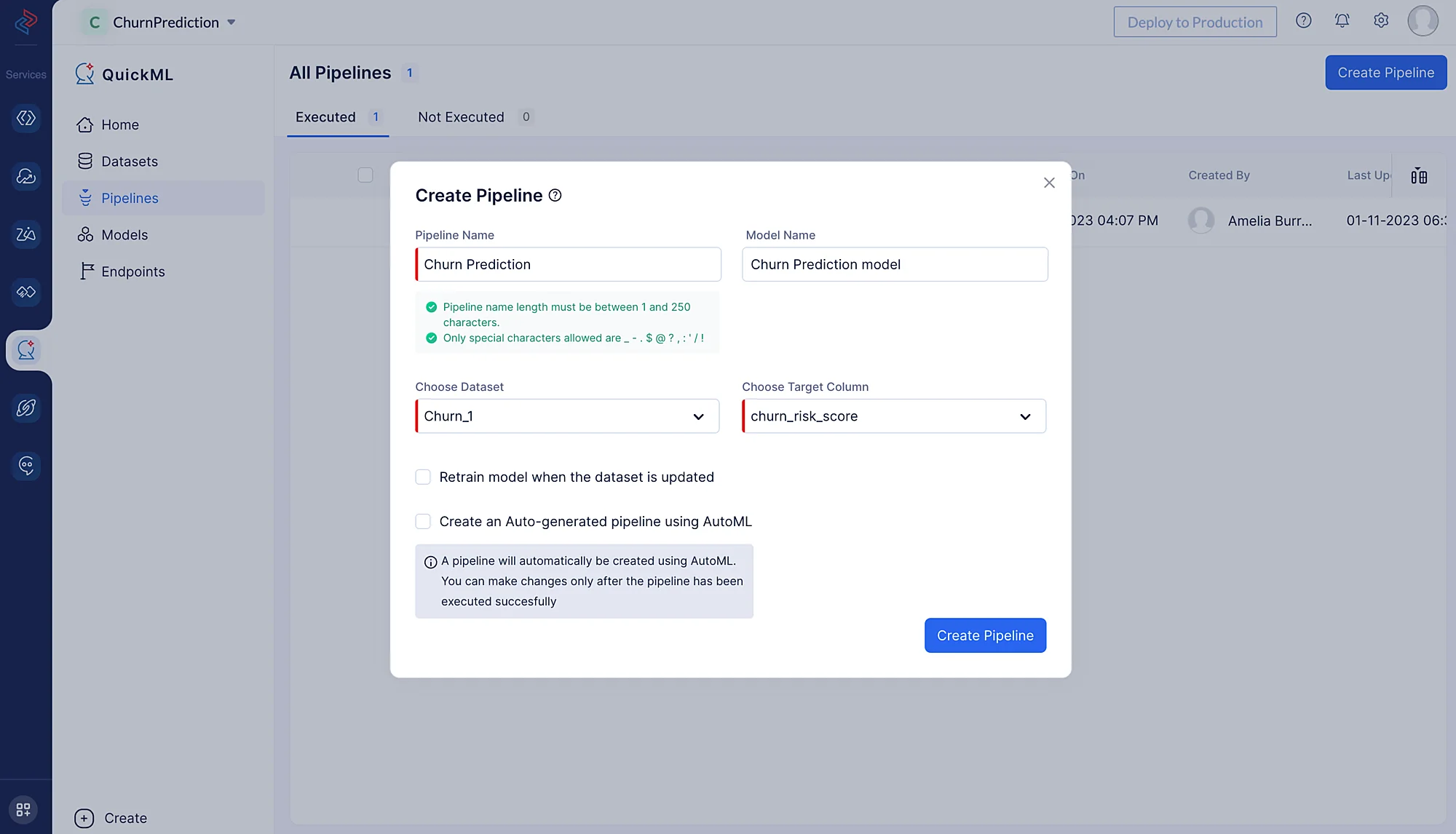
Necesitamos seleccionar el conjunto de datos fuente que se eligió para construir el pipeline de datos, ya que los datos preprocesados se reflejan en el conjunto de datos fuente. En nuestro caso, importaremos el conjunto de datos Churn_1, ya que lo hemos seleccionado para el preprocesamiento y la limpieza, y nuestro objetivo es la columna llamada churn_risk_score.
-
Codificación de columnas categóricas
Los codificadores se usan en diversas tareas de preprocesamiento de datos y machine learning para convertir datos categóricos o no numéricos en un formato numérico con el que los algoritmos de machine learning puedan trabajar de forma efectiva.
-
Codificación ordinal
Aquí estamos usando codificación ordinal para codificar las siguientes características categóricas: “membership_category”, “preferred_offer_types”, “medium_of_operation”, “internet_option”, “gender”, “used_special_discount”, “past_complaints”, “complaint_status” y “feedback”. Asigna enteros a las categorías basándose en su orden, haciendo posible que los algoritmos de machine learning capturen la naturaleza ordinal de los datos. Usaremos el nodo Ordinal Encoder navegando a ML operations, haciendo clic en el componente ->Encoding y eligiendo -> Ordinal Encoder en QuickML para convertir las columnas categóricas seleccionadas en columnas numéricas.
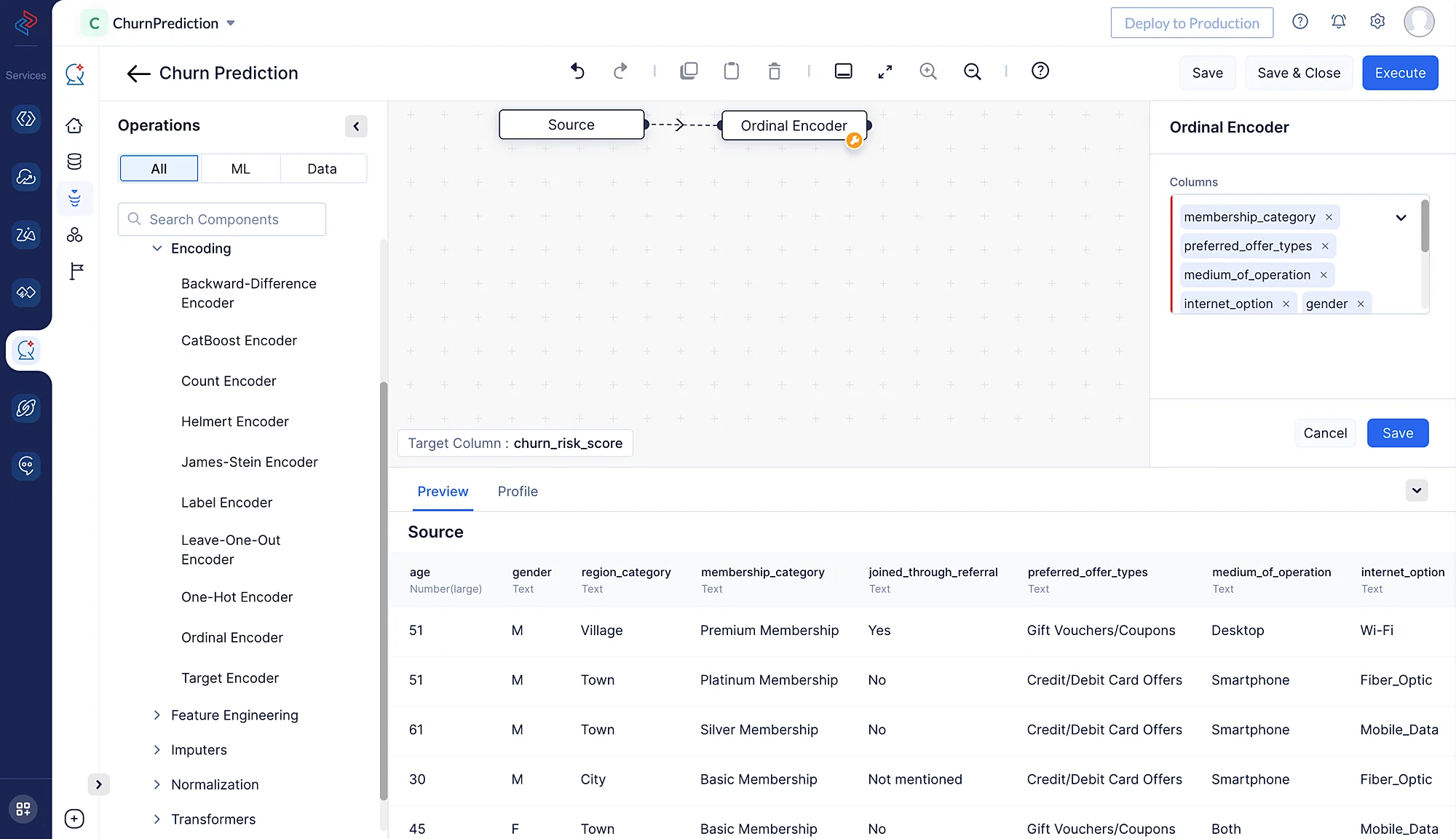
-
Codificador one-hot
La codificación one-hot se aplica típicamente a columnas categóricas en un conjunto de datos, donde cada categoría representa una clase o grupo distinto. Este método generalmente aumenta la dimensionalidad del conjunto de datos porque crea una nueva columna binaria para cada categoría única. El número de columnas binarias es igual al número de categorías únicas menos una, ya que puedes inferir la presencia de la última categoría por la ausencia de todas las demás.
Aquí, estamos usando el nodo One-Hot Encoder para codificar las siguientes columnas: “region_category”, “joined_through_referral” y “offer_application_preference”. Usaremos el nodo One-Hot Encoder navegando a ML operations, seleccionando el componente -> Encoding y eligiendo -> One-Hot Encoder en QuickML para convertir las columnas categóricas seleccionadas en columnas numéricas.
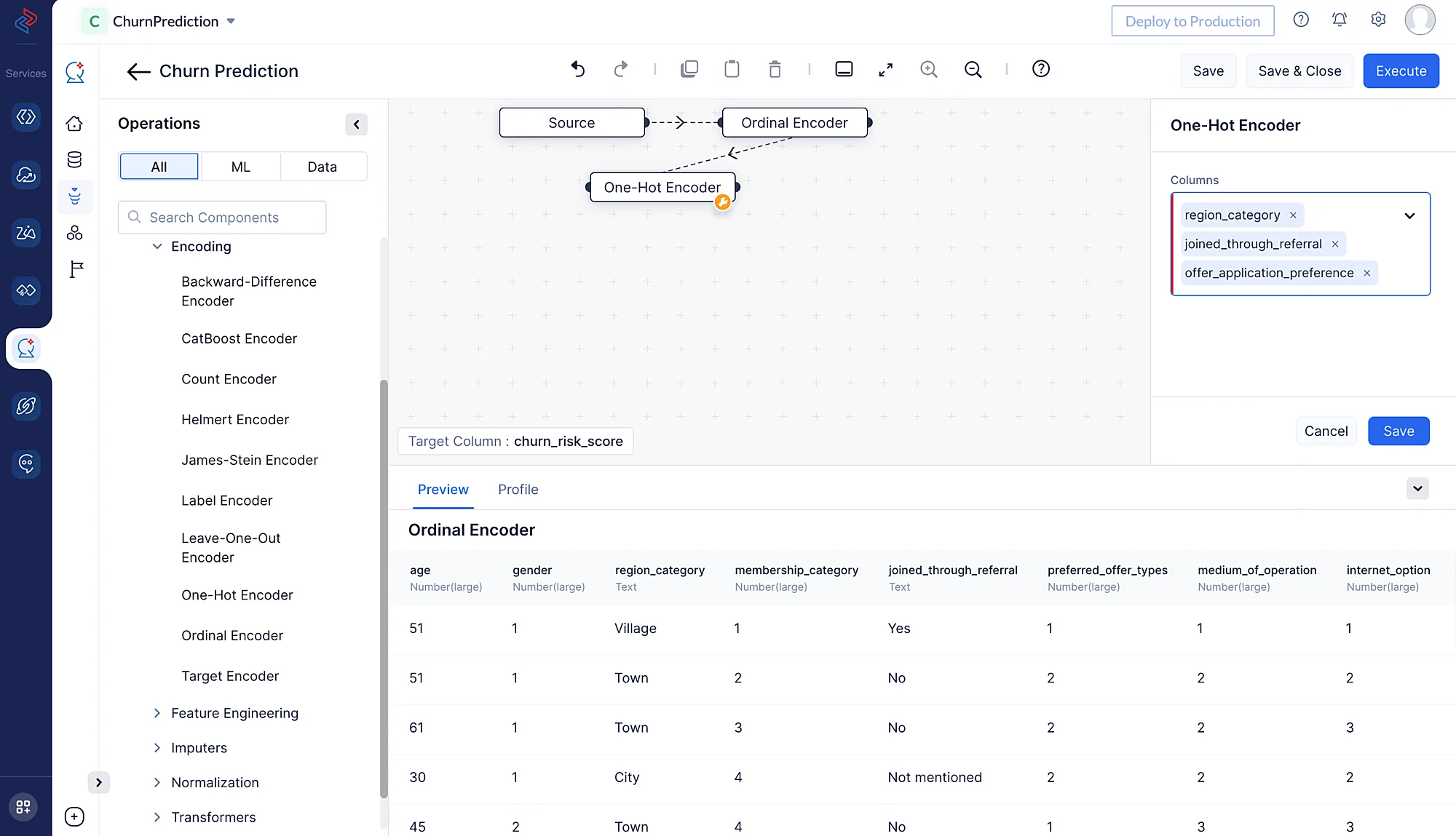
-
-
Ingeniería de Características:
La selección de características es el proceso de elegir un subconjunto de las características más relevantes e importantes (variables o columnas) del conjunto de datos para usar en el entrenamiento del modelo y análisis. El objetivo de la selección de características es mejorar el rendimiento, la eficiencia y la interpretabilidad de los modelos de machine learning. La selección de características es particularmente crucial cuando se trabaja con conjuntos de datos de alta dimensionalidad, ya que puede ayudar a reducir el sobreajuste, reducir el tiempo de cómputo y mejorar la interpretabilidad del modelo.
Aquí estamos usando la técnica de selección de características redundancy elimination para generar las características. Este método identificará y eliminará características redundantes de un conjunto de datos. Las características redundantes proporcionan información duplicada o altamente correlacionada, y no contribuyen significativamente a mejorar el rendimiento de los modelos de machine learning. Selecciona el nodo Redundancy Elimination navegando a ML operations, haciendo clic en ->Feature Engineering, seleccionando ->Feature Selection y eligiendo ->Redundancy Elimination.
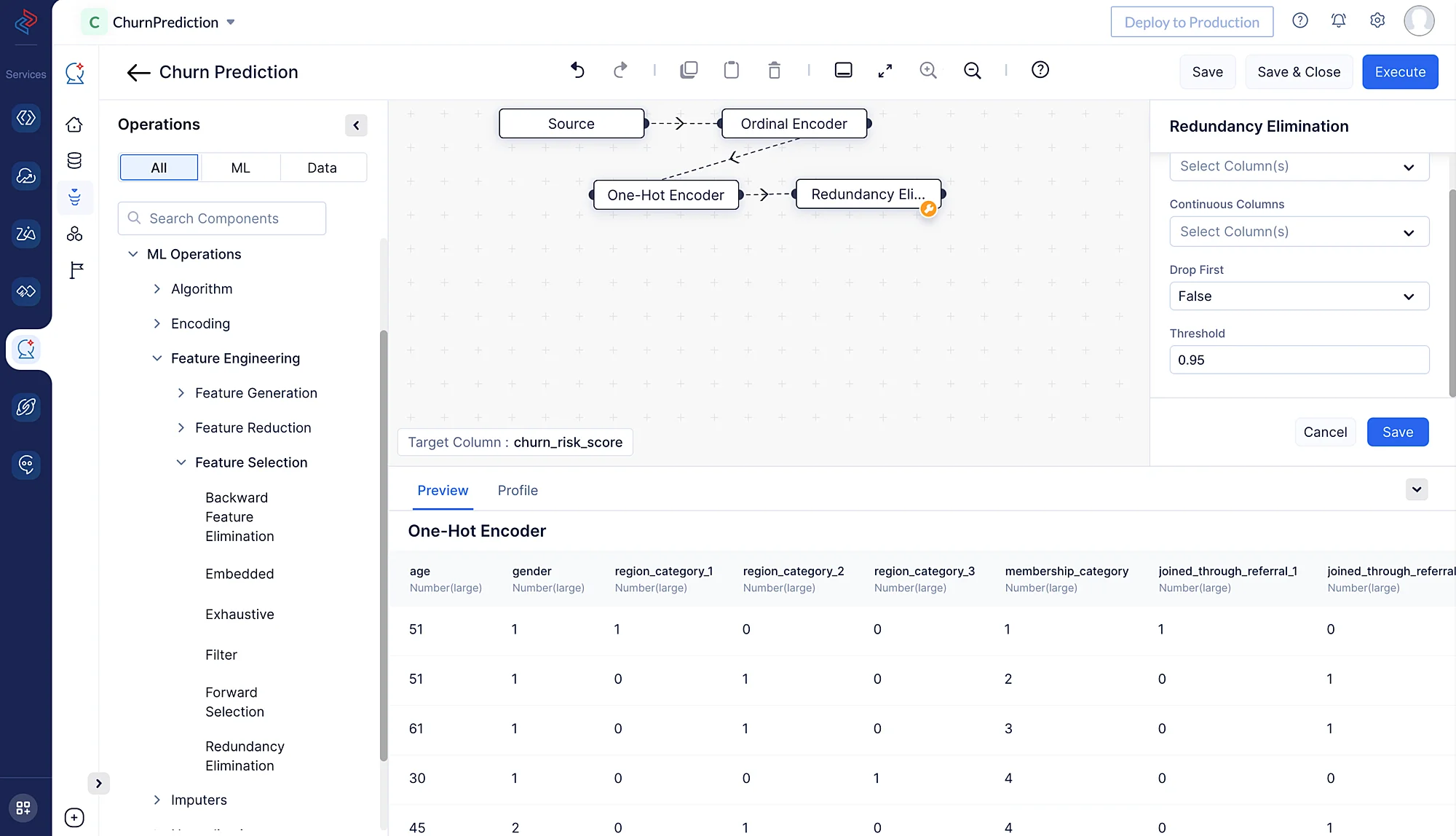
-
Algoritmo de ML:
El siguiente paso en la construcción del pipeline de ML es seleccionar el algoritmo apropiado para entrenar los datos preprocesados. Aquí usaremos el algoritmo de clasificación XGBoost para entrenar los datos.
XGBoost (Extreme Gradient Boosting) es un algoritmo de machine learning popular y poderoso comúnmente usado para tareas de clasificación. Es un método de aprendizaje de conjunto que combina las predicciones de múltiples árboles de decisión para crear un modelo predictivo fuerte. XGBoost es conocido por su velocidad, escalabilidad y capacidad para manejar conjuntos de datos complejos.
Podemos construir rápidamente el método XGBoost Classification en el ML Pipeline Builder de QuickML arrastrando y soltando el nodo relevante XGBoost Classification desde ML operations, seleccionando ->Algorithm, haciendo clic en ->Classification y eligiendo ->XGBoost Classification.
Para asegurarnos de que el modelo esté optimizado para nuestro conjunto de datos particular, también podemos ajustar los parámetros de ajuste; en nuestro caso, podemos simplemente mantener la configuración predeterminada. Cuando todo esté configurado, podemos guardar el pipeline para pruebas y despliegue posteriores.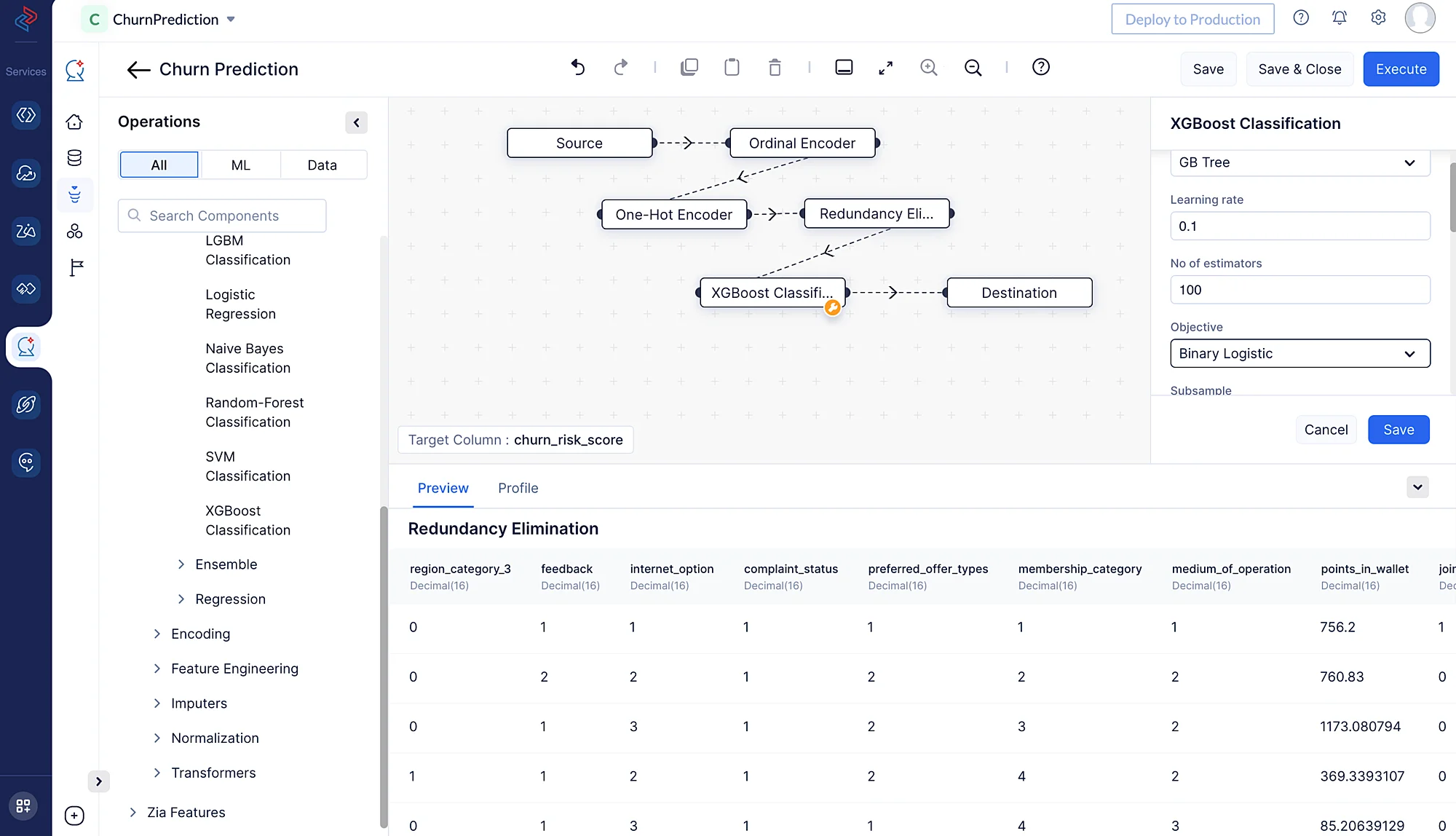
Una vez que arrastramos y soltamos el nodo del algoritmo, su nodo final se conectará automáticamente al nodo de destino. Haz clic en Save para guardar el pipeline y ejecuta el pipeline haciendo clic en el botón Execute en la esquina superior derecha de la página del pipeline builder. Esto te redirigirá a la página a continuación que muestra el pipeline ejecutado con el estado de ejecución. Podemos ver claramente aquí que la ejecución del pipeline fue exitosa.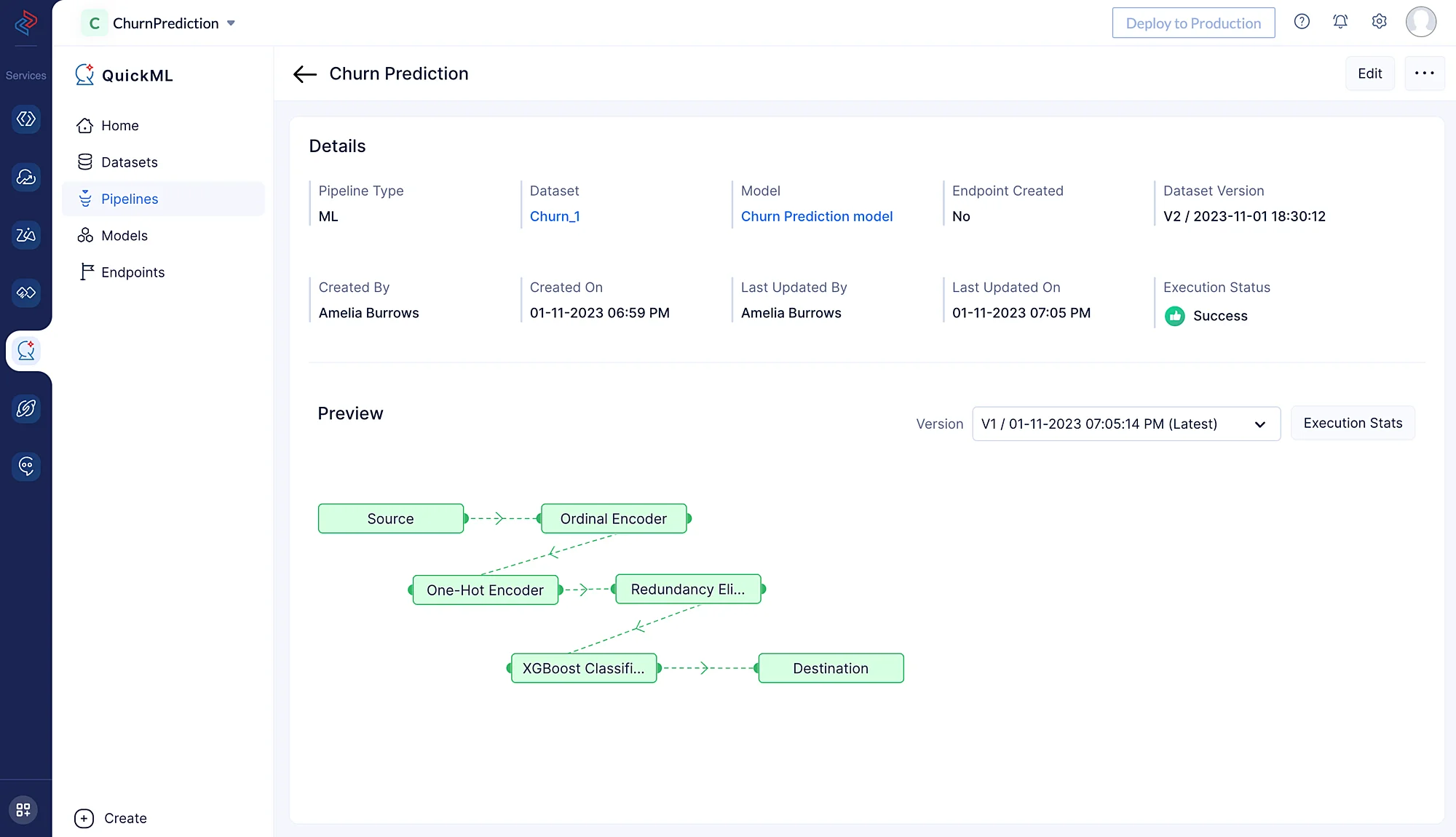
Haz clic en Execution Stats para ver más detalles de cómputo sobre cada etapa de la ejecución del modelo en detalle.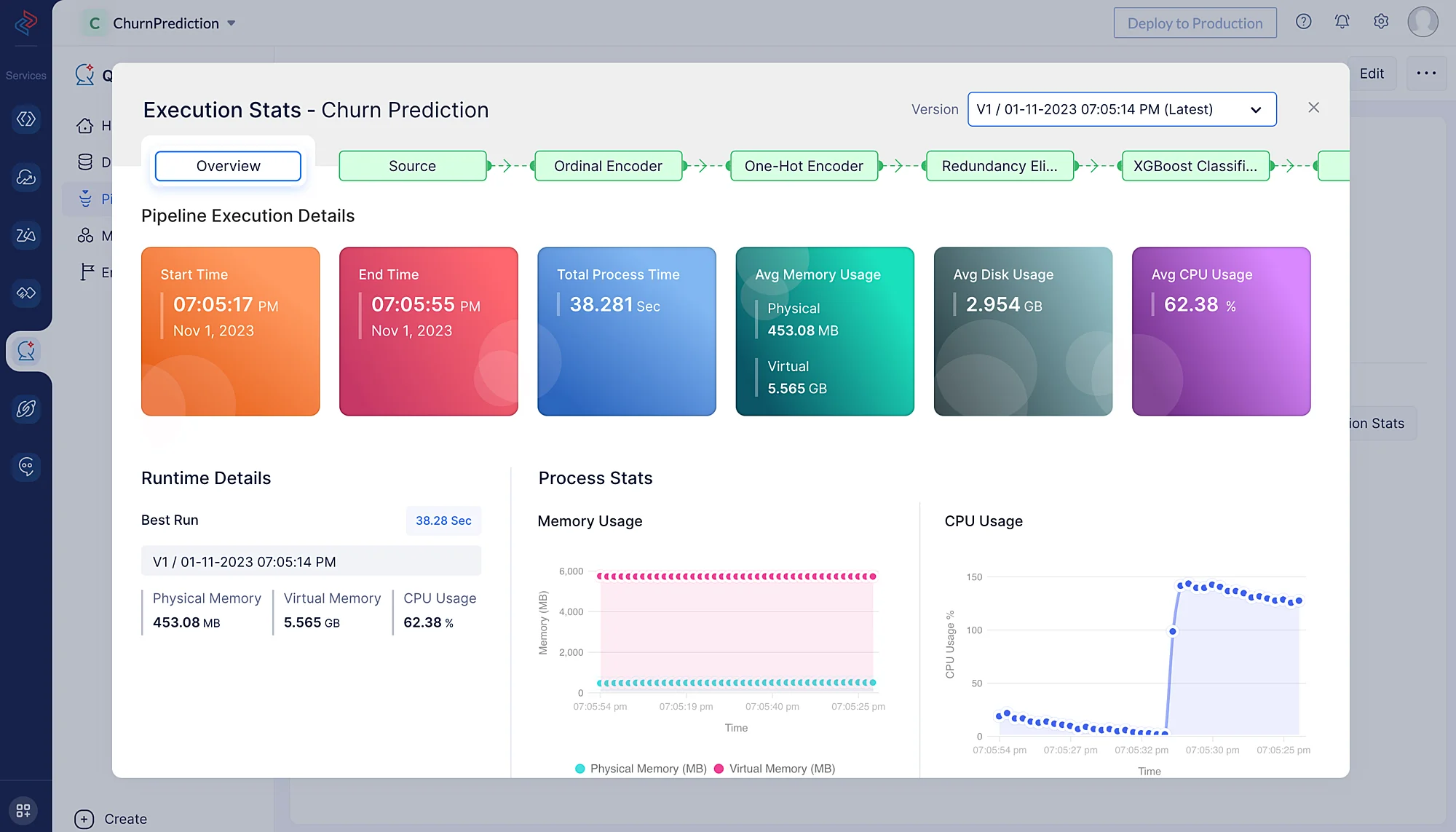
El modelo de predicción se crea y puede examinarse en la sección Model (haz clic en Churn Prediction model) tras la finalización exitosa del flujo de trabajo de ML.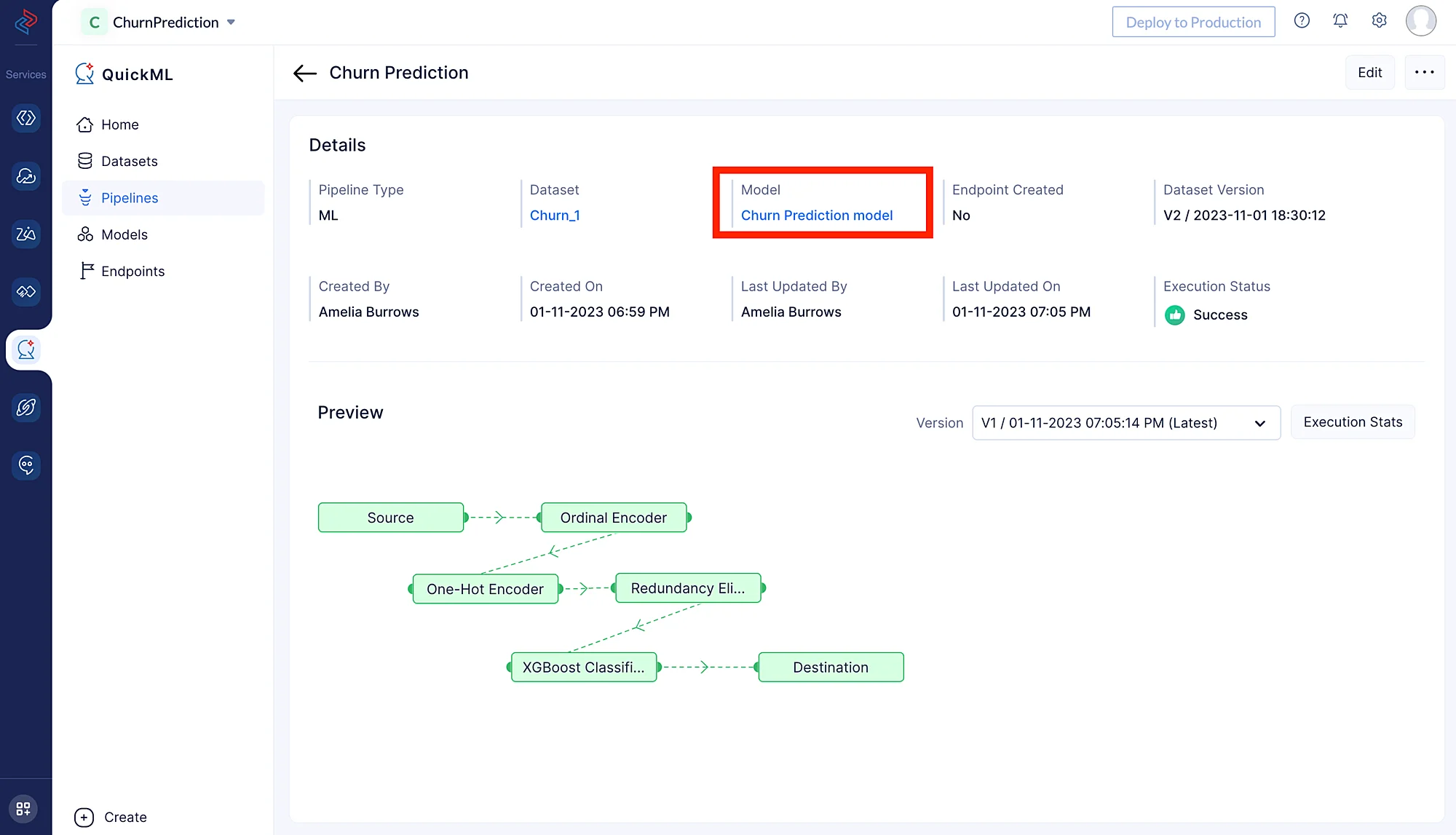
Esto ofrece percepciones útiles sobre la eficiencia y el rendimiento del modelo al hacer predicciones basadas en los datos.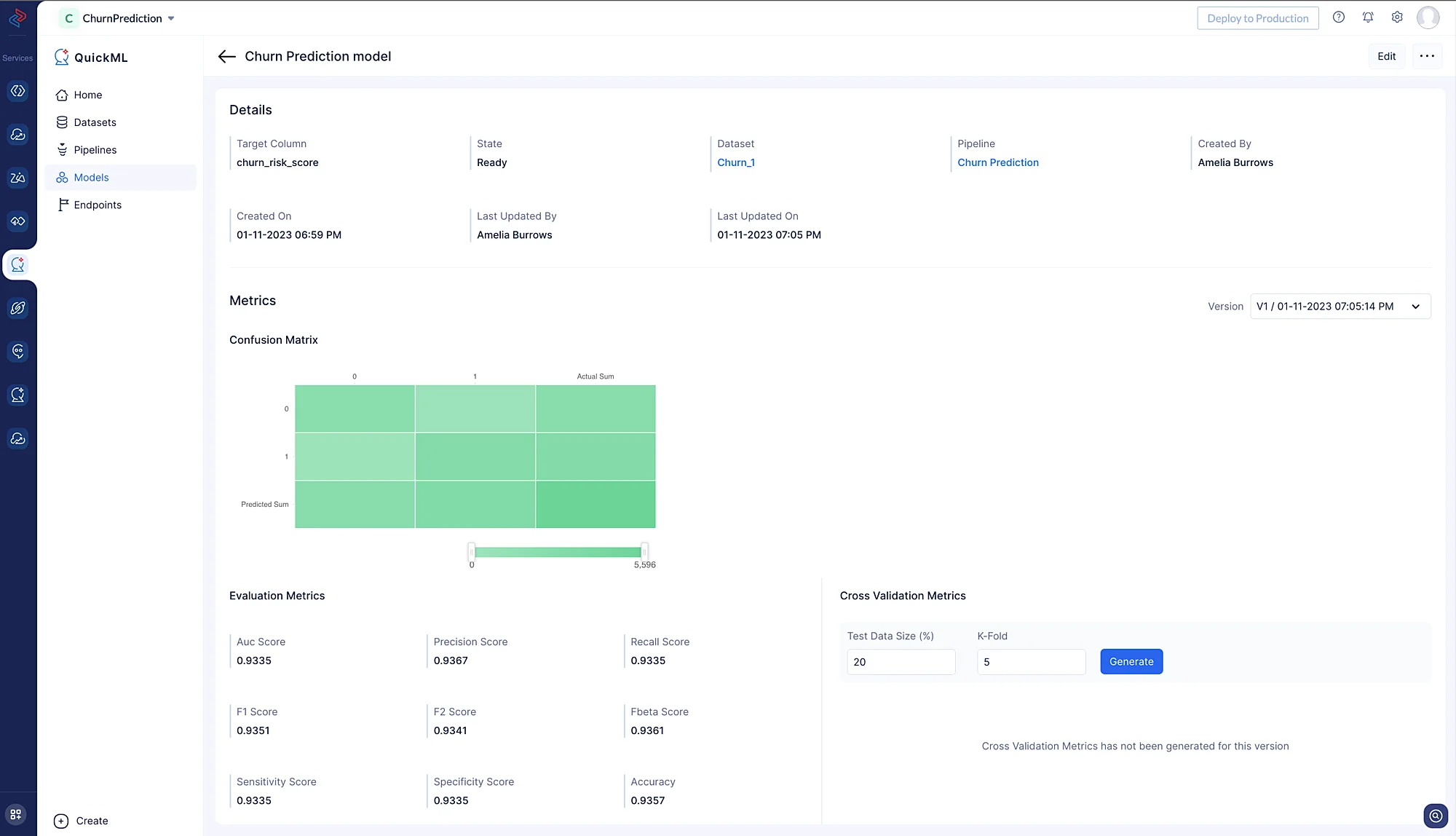
Última actualización 2026-03-20 21:51:56 +0530 IST